 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLM4VLA: Revisiting Vision-Language-Models in Vision-Language-Action Models
Jan 06, 2026Vision-Language-Action (VLA) models, which integrate pretrained large Vision-Language Models (VLM) into their policy backbone, are gaining significant attention for their promising generalization capabilities. This paper revisits a fundamental yet seldom systematically studied question: how VLM choice and competence translate to downstream VLA policies performance? We introduce VLM4VLA, a minimal adaptation pipeline that converts general-purpose VLMs into VLA policies using only a small set of new learnable parameters for fair and efficient comparison. Despite its simplicity, VLM4VLA proves surprisingly competitive with more sophisticated network designs. Through extensive empirical studies on various downstream tasks across three benchmarks, we find that while VLM initialization offers a consistent benefit over training from scratch, a VLM's general capabilities are poor predictors of its downstream task performance. This challenges common assumptions, indicating that standard VLM competence is necessary but insufficient for effective embodied control. We further investigate the impact of specific embodied capabilities by fine-tuning VLMs on seven auxiliary embodied tasks (e.g., embodied QA, visual pointing, depth estimation). Contrary to intuition, improving a VLM's performance on specific embodied skills does not guarantee better downstream control performance. Finally, modality-level ablations identify the visual module in VLM, rather than the language component, as the primary performance bottleneck. We demonstrate that injecting control-relevant supervision into the vision encoder of the VLM yields consistent gains, even when the encoder remains frozen during downstream fine-tuning. This isolates a persistent domain gap between current VLM pretraining objectives and the requirements of embodied action-planning.
Encyclo-K: Evaluating LLMs with Dynamically Composed Knowledge Statements
Dec 31, 2025Benchmarks play a crucial role in tracking the rapid advancement of large language models (LLMs) and identifying their capability boundaries. However, existing benchmarks predominantly curate questions at the question level, suffering from three fundamental limitations: vulnerability to data contamination, restriction to single-knowledge-point assessment, and reliance on costly domain expert annotation. We propose Encyclo-K, a statement-based benchmark that rethinks benchmark construction from the ground up. Our key insight is that knowledge statements, not questions, can serve as the unit of curation, and questions can then be constructed from them. We extract standalone knowledge statements from authoritative textbooks and dynamically compose them into evaluation questions through random sampling at test time. This design directly addresses all three limitations: the combinatorial space is too vast to memorize, and model rankings remain stable across dynamically generated question sets, enabling reliable periodic dataset refresh; each question aggregates 8-10 statements for comprehensive multi-knowledge assessment; annotators only verify formatting compliance without requiring domain expertise, substantially reducing annotation costs. Experiments on over 50 LLMs demonstrate that Encyclo-K poses substantial challenges with strong discriminative power. Even the top-performing OpenAI-GPT-5.1 achieves only 62.07% accuracy, and model performance displays a clear gradient distribution--reasoning models span from 16.04% to 62.07%, while chat models range from 9.71% to 50.40%. These results validate the challenges introduced by dynamic evaluation and multi-statement comprehensive understanding. These findings establish Encyclo-K as a scalable framework for dynamic evaluation of LLMs' comprehensive understanding over multiple fine-grained disciplinary knowledge statements.
GR-Dexter Technical Report
Dec 30, 2025Vision-language-action (VLA) models have enabled language-conditioned, long-horizon robot manipulation, but most existing systems are limited to grippers. Scaling VLA policies to bimanual robots with high degree-of-freedom (DoF) dexterous hands remains challenging due to the expanded action space, frequent hand-object occlusions, and the cost of collecting real-robot data. We present GR-Dexter, a holistic hardware-model-data framework for VLA-based generalist manipulation on a bimanual dexterous-hand robot. Our approach combines the design of a compact 21-DoF robotic hand, an intuitive bimanual teleoperation system for real-robot data collection, and a training recipe that leverages teleoperated robot trajectories together with large-scale vision-language and carefully curated cross-embodiment datasets. Across real-world evaluations spanning long-horizon everyday manipulation and generalizable pick-and-place, GR-Dexter achieves strong in-domain performance and improved robustness to unseen objects and unseen instructions. We hope GR-Dexter serves as a practical step toward generalist dexterous-hand robotic manipulation.
HiSciBench: A Hierarchical Multi-disciplinary Benchmark for Scientific Intelligence from Reading to Discovery
Dec 28, 2025The rapid advancement of large language models (LLMs) and multimodal foundation models has sparked growing interest in their potential for scientific research. However, scientific intelligence encompasses a broad spectrum of abilities ranging from understanding fundamental knowledge to conducting creative discovery, and existing benchmarks remain fragmented. Most focus on narrow tasks and fail to reflect the hierarchical and multi-disciplinary nature of real scientific inquiry. We introduce \textbf{HiSciBench}, a hierarchical benchmark designed to evaluate foundation models across five levels that mirror the complete scientific workflow: \textit{Scientific Literacy} (L1), \textit{Literature Parsing} (L2), \textit{Literature-based Question Answering} (L3), \textit{Literature Review Generation} (L4), and \textit{Scientific Discovery} (L5). HiSciBench contains 8,735 carefully curated instances spanning six major scientific disciplines, including mathematics, physics, chemistry, biology, geography, and astronomy, and supports multimodal inputs including text, equations, figures, and tables, as well as cross-lingual evaluation. Unlike prior benchmarks that assess isolated abilities, HiSciBench provides an integrated, dependency-aware framework that enables detailed diagnosis of model capabilities across different stages of scientific reasoning. Comprehensive evaluations of leading models, including GPT-5, DeepSeek-R1, and several multimodal systems, reveal substantial performance gaps: while models achieve up to 69\% accuracy on basic literacy tasks, performance declines sharply to 25\% on discovery-level challenges. HiSciBench establishes a new standard for evaluating scientific Intelligence and offers actionable insights for developing models that are not only more capable but also more reliable. The benchmark will be publicly released to facilitate future research.
UNSEEN: Enhancing Dataset Pruning from a Generalization Perspective
Nov 18, 2025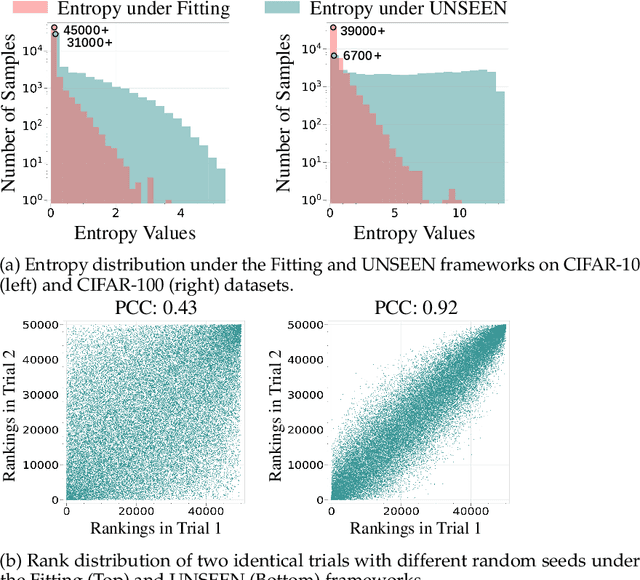

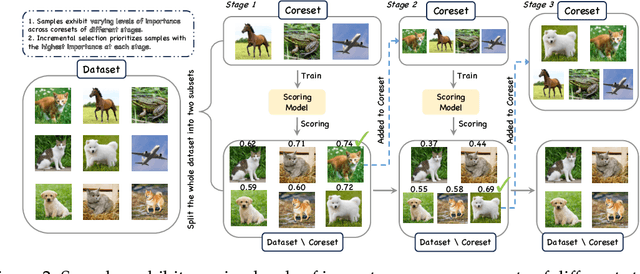

The growing scale of datasets in deep learning has introduced significant computational challenges. Dataset pruning addresses this challenge by constructing a compact but informative coreset from the full dataset with comparable performance. Previous approaches typically establish scoring metrics based on specific criteria to identify representative samples. However, these methods predominantly rely on sample scores obtained from the model's performance during the training (i.e., fitting) phase. As scoring models achieve near-optimal performance on training data, such fitting-centric approaches induce a dense distribution of sample scores within a narrow numerical range. This concentration reduces the distinction between samples and hinders effective selection. To address this challenge, we conduct dataset pruning from the perspective of generalization, i.e., scoring samples based on models not exposed to them during training. We propose a plug-and-play framework, UNSEEN, which can be integrated into existing dataset pruning methods. Additionally, conventional score-based methods are single-step and rely on models trained solely on the complete dataset, providing limited perspective on the importance of samples. To address this limitation, we scale UNSEEN to multi-step scenarios and propose an incremental selection technique through scoring models trained on varying coresets, and optimize the quality of the coreset dynamically. Extensive experiments demonstrate that our method significantly outperforms existing state-of-the-art (SOTA) methods on CIFAR-10, CIFAR-100, and ImageNet-1K. Notably, on ImageNet-1K, UNSEEN achieves lossless performance while reducing training data by 30\%.
Parallel Scaling Law: Unveiling Reasoning Generalization through A Cross-Linguistic Perspective
Oct 02, 2025Recent advancements in Reinforcement Post-Training (RPT) have significantly enhanced the capabilities of Large Reasoning Models (LRMs), sparking increased interest in the generalization of RL-based reasoning. While existing work has primarily focused on investigating its generalization across tasks or modalities, this study proposes a novel cross-linguistic perspective to investigate reasoning generalization. This raises a crucial question: $\textit{Does the reasoning capability achieved from English RPT effectively transfer to other languages?}$ We address this by systematically evaluating English-centric LRMs on multilingual reasoning benchmarks and introducing a metric to quantify cross-lingual transferability. Our findings reveal that cross-lingual transferability varies significantly across initial model, target language, and training paradigm. Through interventional studies, we find that models with stronger initial English capabilities tend to over-rely on English-specific patterns, leading to diminished cross-lingual generalization. To address this, we conduct a thorough parallel training study. Experimental results yield three key findings: $\textbf{First-Parallel Leap}$, a substantial leap in performance when transitioning from monolingual to just a single parallel language, and a predictable $\textbf{Parallel Scaling Law}$, revealing that cross-lingual reasoning transfer follows a power-law with the number of training parallel languages. Moreover, we identify the discrepancy between actual monolingual performance and the power-law prediction as $\textbf{Monolingual Generalization Gap}$, indicating that English-centric LRMs fail to fully generalize across languages. Our study challenges the assumption that LRM reasoning mirrors human cognition, providing critical insights for the development of more language-agnostic LRMs.
MARS2 2025 Challenge on Multimodal Reasoning: Datasets, Methods, Results, Discussion, and Outlook
Sep 17, 2025



This paper reviews the MARS2 2025 Challenge on Multimodal Reasoning. We aim to bring together different approaches in multimodal machine learning and LLMs via a large benchmark. We hope it better allows researchers to follow the state-of-the-art in this very dynamic area. Meanwhile, a growing number of testbeds have boosted the evolution of general-purpose large language models. Thus, this year's MARS2 focuses on real-world and specialized scenarios to broaden the multimodal reasoning applications of MLLMs. Our organizing team released two tailored datasets Lens and AdsQA as test sets, which support general reasoning in 12 daily scenarios and domain-specific reasoning in advertisement videos, respectively. We evaluated 40+ baselines that include both generalist MLLMs and task-specific models, and opened up three competition tracks, i.e., Visual Grounding in Real-world Scenarios (VG-RS), Visual Question Answering with Spatial Awareness (VQA-SA), and Visual Reasoning in Creative Advertisement Videos (VR-Ads). Finally, 76 teams from the renowned academic and industrial institutions have registered and 40+ valid submissions (out of 1200+) have been included in our ranking lists. Our datasets, code sets (40+ baselines and 15+ participants' methods), and rankings are publicly available on the MARS2 workshop website and our GitHub organization page https://github.com/mars2workshop/, where our updates and announcements of upcoming events will be continuously provided.
ACE-RL: Adaptive Constraint-Enhanced Reward for Long-form Generation Reinforcement Learning
Sep 05, 2025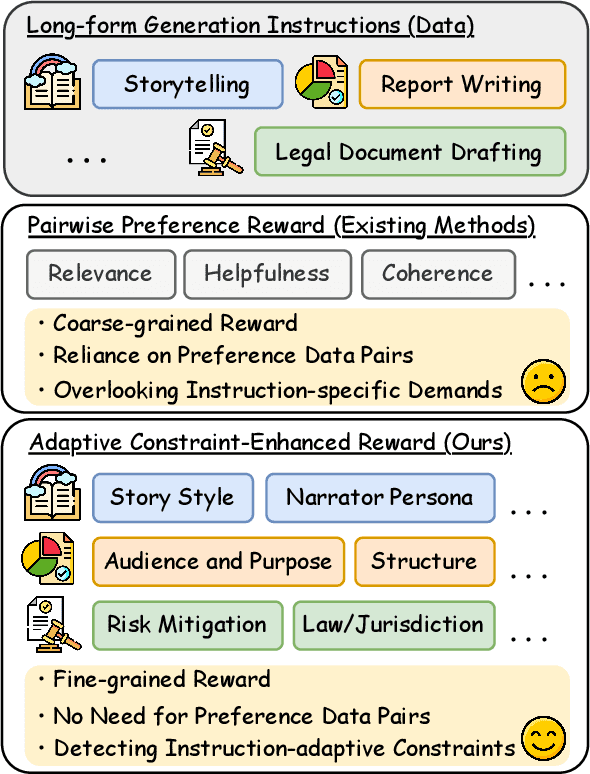

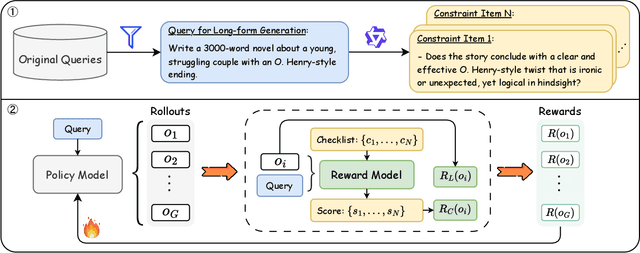
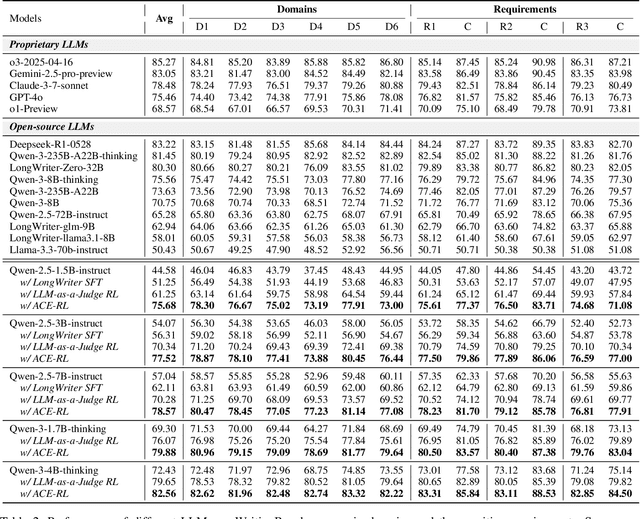
Large Language Models (LLMs) have demonstrated remarkable progress in long-context understanding, yet they face significant challenges in high-quality long-form generation. Existing studies primarily suffer from two limitations: (1) A heavy reliance on scarce, high-quality long-form response data for supervised fine-tuning (SFT) or for pairwise preference reward in reinforcement learning (RL). (2) Focus on coarse-grained quality optimization dimensions, such as relevance, coherence, and helpfulness, overlooking the fine-grained specifics inherent to diverse long-form generation scenarios. To address this issue, we propose a framework using Adaptive Constraint-Enhanced reward for long-form generation Reinforcement Learning (ACE-RL). ACE-RL first automatically deconstructs each instruction into a set of fine-grained, adaptive constraint criteria by identifying its underlying intents and demands. Subsequently, we design a reward mechanism that quantifies the quality of long-form responses based on their satisfaction over corresponding constraints, converting subjective quality evaluation into constraint verification. Finally, we utilize reinforcement learning to guide models toward superior long-form generation capabilities. Experimental results demonstrate that our ACE-RL framework significantly outperforms existing SFT and RL baselines by 20.70% and 7.32% on WritingBench, and our top-performing model even surpasses proprietary systems like GPT-4o by 7.10%, providing a more effective training paradigm for LLMs to generate high-quality content across diverse long-form generation scenarios.
GAF: Gaussian Action Field as a Dvnamic World Model for Robotic Mlanipulation
Jun 17, 2025



Accurate action inference is critical for vision-based robotic manipulation. Existing approaches typically follow either a Vision-to-Action (V-A) paradigm, predicting actions directly from visual inputs, or a Vision-to-3D-to-Action (V-3D-A) paradigm, leveraging intermediate 3D representations. However, these methods often struggle with action inaccuracies due to the complexity and dynamic nature of manipulation scenes. In this paper, we propose a V-4D-A framework that enables direct action reasoning from motion-aware 4D representations via a Gaussian Action Field (GAF). GAF extends 3D Gaussian Splatting (3DGS) by incorporating learnable motion attributes, allowing simultaneous modeling of dynamic scenes and manipulation actions. To learn time-varying scene geometry and action-aware robot motion, GAF supports three key query types: reconstruction of the current scene, prediction of future frames, and estimation of initial action via robot motion. Furthermore, the high-quality current and future frames generated by GAF facilitate manipulation action refinement through a GAF-guided diffusion model. Extensive experiments demonstrate significant improvements, with GAF achieving +11.5385 dB PSNR and -0.5574 LPIPS improvements in reconstruction quality, while boosting the average success rate in robotic manipulation tasks by 10.33% over state-of-the-art methods. Project page: http://chaiying1.github.io/GAF.github.io/project_page/
Group then Scale: Dynamic Mixture-of-Experts Multilingual Language Model
Jun 14, 2025The curse of multilinguality phenomenon is a fundamental problem of multilingual Large Language Models (LLMs), where the competition between massive languages results in inferior performance. It mainly comes from limited capacity and negative transfer between dissimilar languages. To address this issue, we propose a method to dynamically group and scale up the parameters of multilingual LLM while boosting positive transfer among similar languages. Specifically, the model is first tuned on monolingual corpus to determine the parameter deviation in each layer and quantify the similarity between languages. Layers with more deviations are extended to mixture-of-experts layers to reduce competition between languages, where one expert module serves one group of similar languages. Experimental results on 18 to 128 languages show that our method reduces the negative transfer between languages and significantly boosts multilingual performance with fewer parameters. Such language group specialization on experts benefits the new language adaptation and reduces the inference on the previous multilingual knowledge learned.