 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSGG-R$^{\rm 3}$: From Next-Token Prediction to End-to-End Unbiased Scene Graph Generation
Mar 12, 2026Scene Graph Generation (SGG) structures visual scenes as graphs of objects and their relations. While Multimodal Large Language Models (MLLMs) have advanced end-to-end SGG, current methods are hindered by both a lack of task-specific structured reasoning and the challenges of sparse, long-tailed relation distributions, resulting in incomplete scene graphs characterized by low recall and biased predictions. To address these issues, we introduce SGG-R$^{\rm 3}$, a structured reasoning framework that integrates task-specific chain-of-thought (CoT)-guided supervised fine-tuning (SFT) and reinforcement learning (RL) with group sequence policy optimization (GSPO), designed to engage in three sequential stages to achieve end-to-end unbiased scene graph generation. During the SFT phase, we propose a relation augmentation strategy by leveraging an MLLM and refined via embedding similarity filtering to alleviate relation sparsity. Subsequently, a stage-aligned reward scheme optimizes the procedural reasoning during RL. Specifically, we propose a novel dual-granularity reward which integrates fine-grained and coarse-grained relation rewards, simultaneously mitigating the long-tail issue via frequency-based adaptive weighting of predicates and improving relation coverage through semantic clustering. Experiments on two benchmarks show that SGG-R$^{\rm 3}$ achieves superior performance compared to existing methods, demonstrating the effectiveness and generalization of the framework.
MM-DeepResearch: A Simple and Effective Multimodal Agentic Search Baseline
Mar 01, 2026We aim to develop a multimodal research agent capable of explicit reasoning and planning, multi-tool invocation, and cross-modal information synthesis, enabling it to conduct deep research tasks. However, we observe three main challenges in developing such agents: (1) scarcity of search-intensive multimodal QA data, (2) lack of effective search trajectories, and (3) prohibitive cost of training with online search APIs. To tackle them, we first propose Hyper-Search, a hypergraph-based QA generation method that models and connects visual and textual nodes within and across modalities, enabling to generate search-intensive multimodal QA pairs that require invoking various search tools to solve. Second, we introduce DR-TTS, which first decomposes search-involved tasks into several categories according to search tool types, and respectively optimize specialized search tool experts for each tool. It then recomposes tool experts to jointly explore search trajectories via tree search, producing trajectories that successfully solve complex tasks using various search tools. Third, we build an offline search engine supporting multiple search tools, enabling agentic reinforcement learning without using costly online search APIs. With the three designs, we develop MM-DeepResearch, a powerful multimodal deep research agent, and extensive results shows its superiority across benchmarks. Code is available at https://github.com/HJYao00/MM-DeepResearch
ACE-RL: Adaptive Constraint-Enhanced Reward for Long-form Generation Reinforcement Learning
Sep 05, 2025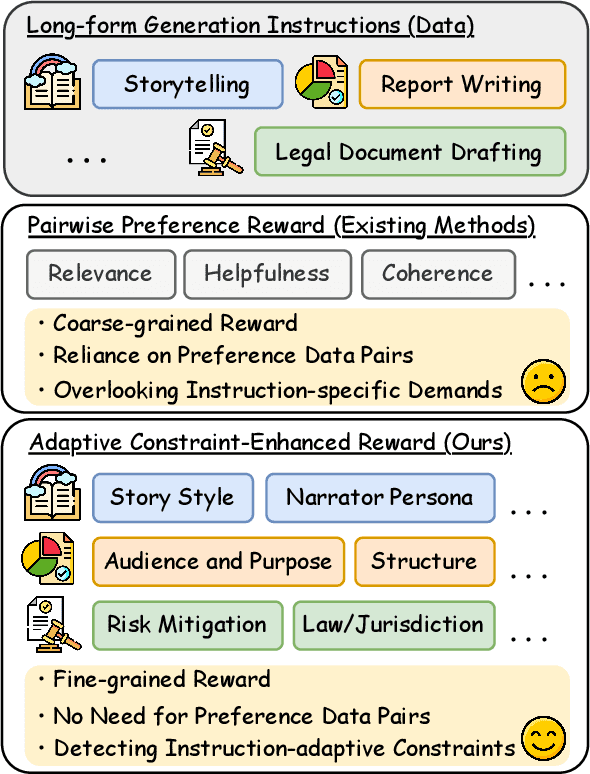

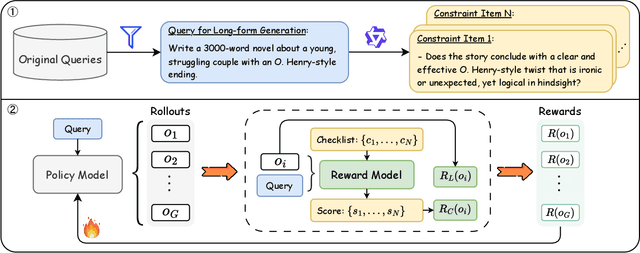
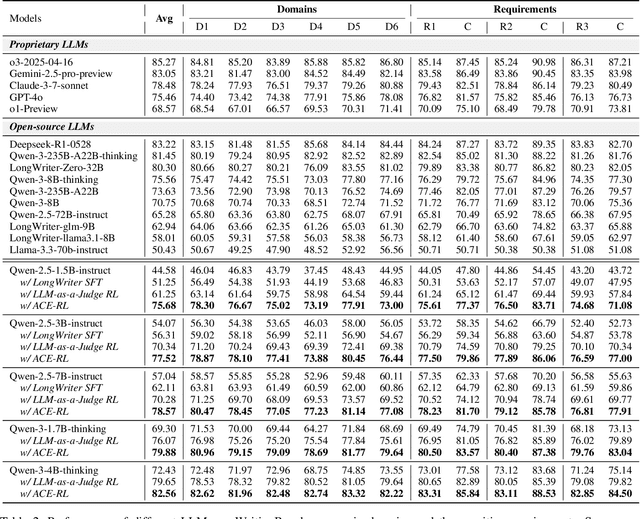
Large Language Models (LLMs) have demonstrated remarkable progress in long-context understanding, yet they face significant challenges in high-quality long-form generation. Existing studies primarily suffer from two limitations: (1) A heavy reliance on scarce, high-quality long-form response data for supervised fine-tuning (SFT) or for pairwise preference reward in reinforcement learning (RL). (2) Focus on coarse-grained quality optimization dimensions, such as relevance, coherence, and helpfulness, overlooking the fine-grained specifics inherent to diverse long-form generation scenarios. To address this issue, we propose a framework using Adaptive Constraint-Enhanced reward for long-form generation Reinforcement Learning (ACE-RL). ACE-RL first automatically deconstructs each instruction into a set of fine-grained, adaptive constraint criteria by identifying its underlying intents and demands. Subsequently, we design a reward mechanism that quantifies the quality of long-form responses based on their satisfaction over corresponding constraints, converting subjective quality evaluation into constraint verification. Finally, we utilize reinforcement learning to guide models toward superior long-form generation capabilities. Experimental results demonstrate that our ACE-RL framework significantly outperforms existing SFT and RL baselines by 20.70% and 7.32% on WritingBench, and our top-performing model even surpasses proprietary systems like GPT-4o by 7.10%, providing a more effective training paradigm for LLMs to generate high-quality content across diverse long-form generation scenarios.
R1-ShareVL: Incentivizing Reasoning Capability of Multimodal Large Language Models via Share-GRPO
May 22, 2025In this work, we aim to incentivize the reasoning ability of Multimodal Large Language Models (MLLMs) via reinforcement learning (RL) and develop an effective approach that mitigates the sparse reward and advantage vanishing issues during RL. To this end, we propose Share-GRPO, a novel RL approach that tackle these issues by exploring and sharing diverse reasoning trajectories over expanded question space. Specifically, Share-GRPO first expands the question space for a given question via data transformation techniques, and then encourages MLLM to effectively explore diverse reasoning trajectories over the expanded question space and shares the discovered reasoning trajectories across the expanded questions during RL. In addition, Share-GRPO also shares reward information during advantage computation, which estimates solution advantages hierarchically across and within question variants, allowing more accurate estimation of relative advantages and improving the stability of policy training. Extensive evaluations over six widely-used reasoning benchmarks showcase the superior performance of our method. Code will be available at https://github.com/HJYao00/R1-ShareVL.
CPAny: Couple With Any Encoder to Refer Multi-Object Tracking
Mar 10, 2025Referring Multi-Object Tracking (RMOT) aims to localize target trajectories specified by natural language expressions in videos. Existing RMOT methods mainly follow two paradigms, namely, one-stage strategies and two-stage ones. The former jointly trains tracking with referring but suffers from substantial computational overhead. Although the latter improves computational efficiency, its CLIP-inspired dual-tower architecture restricts compatibility with other visual/text backbones and is not future-proof. To overcome these limitations, we propose CPAny, a novel encoder-decoder framework for two-stage RMOT, which introduces two core components: (1) a Contextual Visual Semantic Abstractor (CVSA) performs context-aware aggregation on visual backbone features and projects them into a unified semantic space; (2) a Parallel Semantic Summarizer (PSS) decodes the visual and linguistic features at the semantic level in parallel and generates referring scores. By replacing the inherent feature alignment of encoders with a self-constructed unified semantic space, CPAny achieves flexible compatibility with arbitrary emerging visual / text encoders. Meanwhile, CPAny aggregates contextual information by encoding only once and processes multiple expressions in parallel, significantly reducing computational redundancy. Extensive experiments on the Refer-KITTI and Refer-KITTI-V2 datasets show that CPAny outperforms SOTA methods across diverse encoder combinations, with a particular 7.77\% HOTA improvement on Refer-KITTI-V2. Code will be available soon.