 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Layer Vision Smoothing: Enhancing Visual Understanding via Sustained Focus on Key Objects in Large Vision-Language Models
Sep 16, 2025Large Vision-Language Models (LVLMs) can accurately locate key objects in images, yet their attention to these objects tends to be very brief. Motivated by the hypothesis that sustained focus on key objects can improve LVLMs' visual capabilities, we propose Cross-Layer Vision Smoothing (CLVS). The core idea of CLVS is to incorporate a vision memory that smooths the attention distribution across layers. Specifically, we initialize this vision memory with position-unbiased visual attention in the first layer. In subsequent layers, the model's visual attention jointly considers the vision memory from previous layers, while the memory is updated iteratively, thereby maintaining smooth attention on key objects. Given that visual understanding primarily occurs in the early and middle layers of the model, we use uncertainty as an indicator of completed visual understanding and terminate the smoothing process accordingly. Experiments on four benchmarks across three LVLMs confirm the effectiveness and generalizability of our method. CLVS achieves state-of-the-art performance on a variety of visual understanding tasks, with particularly significant improvements in relation and attribute understanding.
ACE-RL: Adaptive Constraint-Enhanced Reward for Long-form Generation Reinforcement Learning
Sep 05, 2025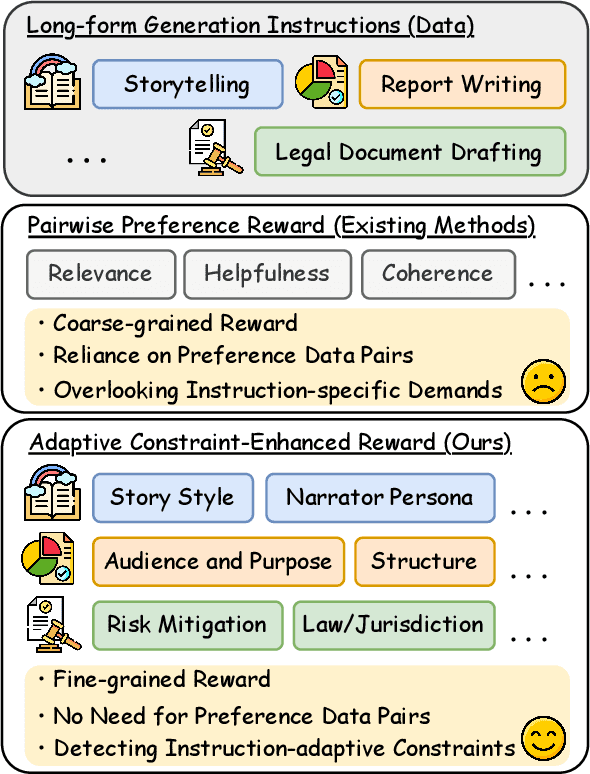

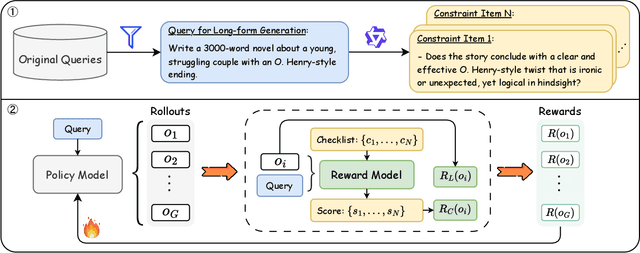
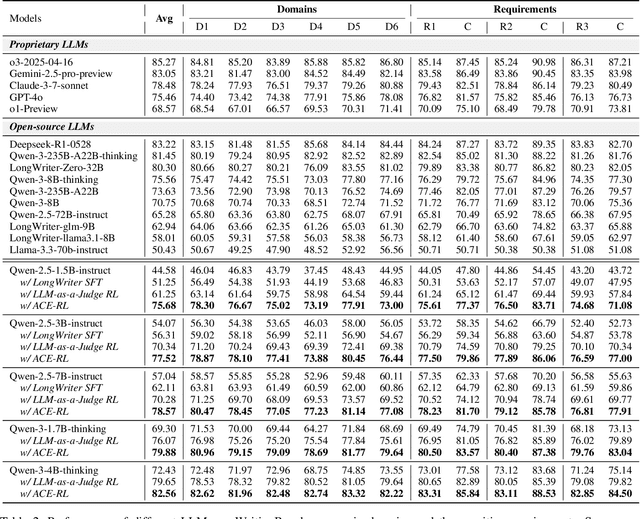
Large Language Models (LLMs) have demonstrated remarkable progress in long-context understanding, yet they face significant challenges in high-quality long-form generation. Existing studies primarily suffer from two limitations: (1) A heavy reliance on scarce, high-quality long-form response data for supervised fine-tuning (SFT) or for pairwise preference reward in reinforcement learning (RL). (2) Focus on coarse-grained quality optimization dimensions, such as relevance, coherence, and helpfulness, overlooking the fine-grained specifics inherent to diverse long-form generation scenarios. To address this issue, we propose a framework using Adaptive Constraint-Enhanced reward for long-form generation Reinforcement Learning (ACE-RL). ACE-RL first automatically deconstructs each instruction into a set of fine-grained, adaptive constraint criteria by identifying its underlying intents and demands. Subsequently, we design a reward mechanism that quantifies the quality of long-form responses based on their satisfaction over corresponding constraints, converting subjective quality evaluation into constraint verification. Finally, we utilize reinforcement learning to guide models toward superior long-form generation capabilities. Experimental results demonstrate that our ACE-RL framework significantly outperforms existing SFT and RL baselines by 20.70% and 7.32% on WritingBench, and our top-performing model even surpasses proprietary systems like GPT-4o by 7.10%, providing a more effective training paradigm for LLMs to generate high-quality content across diverse long-form generation scenarios.
MixRED: A Mix-lingual Relation Extraction Dataset
Mar 23, 2024



Relation extraction is a critical task in the field of natural language processing with numerous real-world applications. Existing research primarily focuses on monolingual relation extraction or cross-lingual enhancement for relation extraction. Yet, there remains a significant gap in understanding relation extraction in the mix-lingual (or code-switching) scenario, where individuals intermix contents from different languages within sentences, generating mix-lingual content. Due to the lack of a dedicated dataset, the effectiveness of existing relation extraction models in such a scenario is largely unexplored. To address this issue, we introduce a novel task of considering relation extraction in the mix-lingual scenario called MixRE and constructing the human-annotated dataset MixRED to support this task. In addition to constructing the MixRED dataset, we evaluate both state-of-the-art supervised models and large language models (LLMs) on MixRED, revealing their respective advantages and limitations in the mix-lingual scenario. Furthermore, we delve into factors influencing model performance within the MixRE task and uncover promising directions for enhancing the performance of both supervised models and LLMs in this novel task.