 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACE-RL: Adaptive Constraint-Enhanced Reward for Long-form Generation Reinforcement Learning
Paper and Code
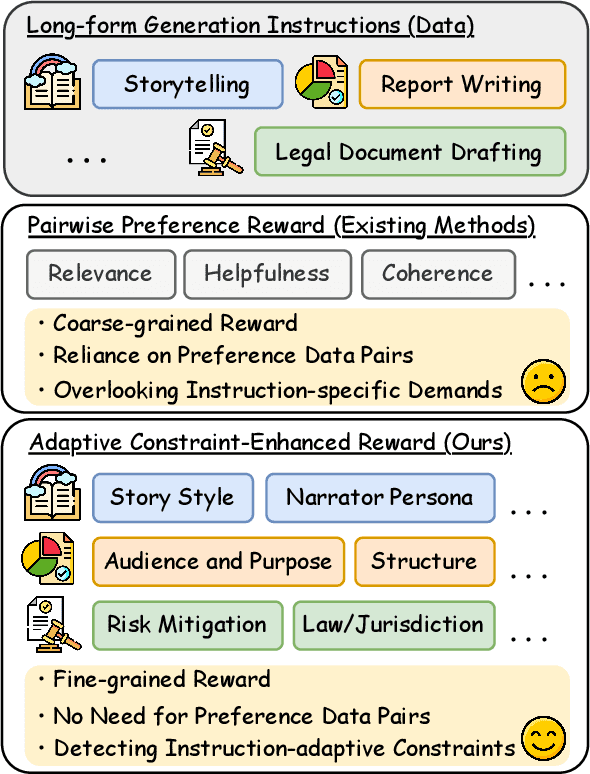

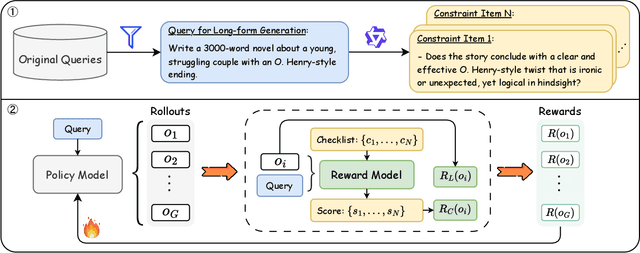
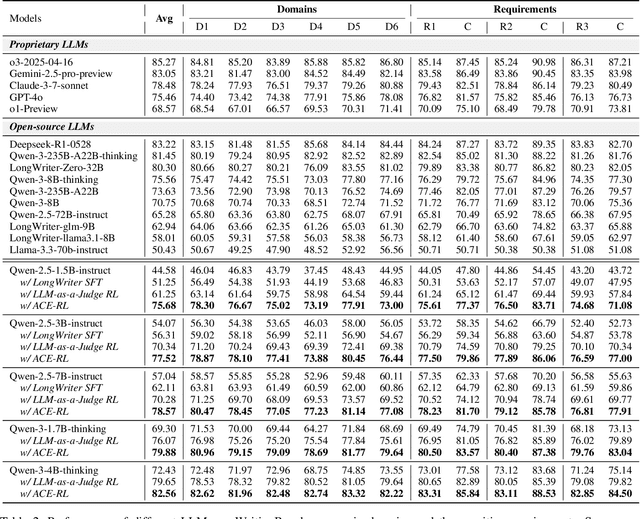
Large Language Models (LLMs) have demonstrated remarkable progress in long-context understanding, yet they face significant challenges in high-quality long-form generation. Existing studies primarily suffer from two limitations: (1) A heavy reliance on scarce, high-quality long-form response data for supervised fine-tuning (SFT) or for pairwise preference reward in reinforcement learning (RL). (2) Focus on coarse-grained quality optimization dimensions, such as relevance, coherence, and helpfulness, overlooking the fine-grained specifics inherent to diverse long-form generation scenarios. To address this issue, we propose a framework using Adaptive Constraint-Enhanced reward for long-form generation Reinforcement Learning (ACE-RL). ACE-RL first automatically deconstructs each instruction into a set of fine-grained, adaptive constraint criteria by identifying its underlying intents and demands. Subsequently, we design a reward mechanism that quantifies the quality of long-form responses based on their satisfaction over corresponding constraints, converting subjective quality evaluation into constraint verification. Finally, we utilize reinforcement learning to guide models toward superior long-form generation capabilities. Experimental results demonstrate that our ACE-RL framework significantly outperforms existing SFT and RL baselines by 20.70% and 7.32% on WritingBench, and our top-performing model even surpasses proprietary systems like GPT-4o by 7.10%, providing a more effective training paradigm for LLMs to generate high-quality content across diverse long-form generation scenarios.