 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel Scaling Law: Unveiling Reasoning Generalization through A Cross-Linguistic Perspective
Oct 02, 2025Recent advancements in Reinforcement Post-Training (RPT) have significantly enhanced the capabilities of Large Reasoning Models (LRMs), sparking increased interest in the generalization of RL-based reasoning. While existing work has primarily focused on investigating its generalization across tasks or modalities, this study proposes a novel cross-linguistic perspective to investigate reasoning generalization. This raises a crucial question: $\textit{Does the reasoning capability achieved from English RPT effectively transfer to other languages?}$ We address this by systematically evaluating English-centric LRMs on multilingual reasoning benchmarks and introducing a metric to quantify cross-lingual transferability. Our findings reveal that cross-lingual transferability varies significantly across initial model, target language, and training paradigm. Through interventional studies, we find that models with stronger initial English capabilities tend to over-rely on English-specific patterns, leading to diminished cross-lingual generalization. To address this, we conduct a thorough parallel training study. Experimental results yield three key findings: $\textbf{First-Parallel Leap}$, a substantial leap in performance when transitioning from monolingual to just a single parallel language, and a predictable $\textbf{Parallel Scaling Law}$, revealing that cross-lingual reasoning transfer follows a power-law with the number of training parallel languages. Moreover, we identify the discrepancy between actual monolingual performance and the power-law prediction as $\textbf{Monolingual Generalization Gap}$, indicating that English-centric LRMs fail to fully generalize across languages. Our study challenges the assumption that LRM reasoning mirrors human cognition, providing critical insights for the development of more language-agnostic LRMs.
Emergent Hierarchical Reasoning in LLMs through Reinforcement Learning
Sep 03, 2025

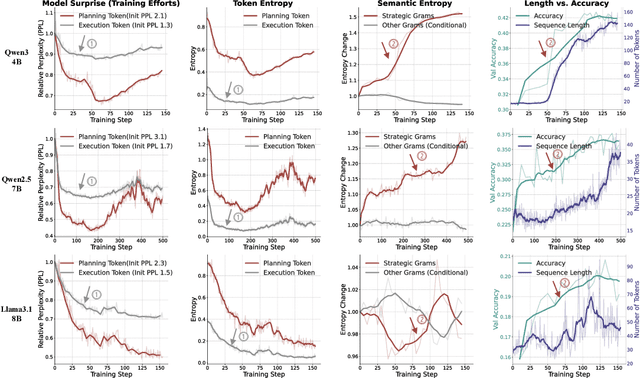

Reinforcement Learning (RL) has proven highly effective at enhancing the complex reasoning abilities of Large Language Models (LLMs), yet underlying mechanisms driving this success remain largely opaque. Our analysis reveals that puzzling phenomena like ``aha moments", ``length-scaling'' and entropy dynamics are not disparate occurrences but hallmarks of an emergent reasoning hierarchy, akin to the separation of high-level strategic planning from low-level procedural execution in human cognition. We uncover a compelling two-phase dynamic: initially, a model is constrained by procedural correctness and must improve its low-level skills. The learning bottleneck then decisively shifts, with performance gains being driven by the exploration and mastery of high-level strategic planning. This insight exposes a core inefficiency in prevailing RL algorithms like GRPO, which apply optimization pressure agnostically and dilute the learning signal across all tokens. To address this, we propose HIerarchy-Aware Credit Assignment (HICRA), an algorithm that concentrates optimization efforts on high-impact planning tokens. HICRA significantly outperforms strong baselines, demonstrating that focusing on this strategic bottleneck is key to unlocking advanced reasoning. Furthermore, we validate semantic entropy as a superior compass for measuring strategic exploration over misleading metrics such as token-level entropy.
Implicit Cross-Lingual Rewarding for Efficient Multilingual Preference Alignment
Mar 06, 2025



Direct Preference Optimization (DPO) has become a prominent method for aligning Large Language Models (LLMs) with human preferences. While DPO has enabled significant progress in aligning English LLMs, multilingual preference alignment is hampered by data scarcity. To address this, we propose a novel approach that $\textit{captures}$ learned preferences from well-aligned English models by implicit rewards and $\textit{transfers}$ them to other languages through iterative training. Specifically, we derive an implicit reward model from the logits of an English DPO-aligned model and its corresponding reference model. This reward model is then leveraged to annotate preference relations in cross-lingual instruction-following pairs, using English instructions to evaluate multilingual responses. The annotated data is subsequently used for multilingual DPO fine-tuning, facilitating preference knowledge transfer from English to other languages. Fine-tuning Llama3 for two iterations resulted in a 12.72% average improvement in Win Rate and a 5.97% increase in Length Control Win Rate across all training languages on the X-AlpacaEval leaderboard. Our findings demonstrate that leveraging existing English-aligned models can enable efficient and effective multilingual preference alignment, significantly reducing the need for extensive multilingual preference data. The code is available at https://github.com/ZNLP/Implicit-Cross-Lingual-Rewarding
LADM: Long-context Training Data Selection with Attention-based Dependency Measurement for LLMs
Mar 04, 2025



Long-context modeling has drawn more and more attention in the area of Large Language Models (LLMs). Continual training with long-context data becomes the de-facto method to equip LLMs with the ability to process long inputs. However, it still remains an open challenge to measure the quality of long-context training data. To address this issue, we propose a Long-context data selection framework with Attention-based Dependency Measurement (LADM), which can efficiently identify high-quality long-context data from a large-scale, multi-domain pre-training corpus. LADM leverages the retrieval capabilities of the attention mechanism to capture contextual dependencies, ensuring a comprehensive quality measurement of long-context data. Experimental results show that our LADM framework significantly boosts the performance of LLMs on multiple long-context tasks with only 1B tokens for continual training.
Boosting LLM Translation Skills without General Ability Loss via Rationale Distillation
Oct 17, 2024



Large Language Models (LLMs) have achieved impressive results across numerous NLP tasks but still encounter difficulties in machine translation. Traditional methods to improve translation have typically involved fine-tuning LLMs using parallel corpora. However, vanilla fine-tuning often leads to catastrophic forgetting of the instruction-following capabilities and alignment with human preferences, compromising their broad general abilities and introducing potential security risks. These abilities, which are developed using proprietary and unavailable training data, make existing continual instruction tuning methods ineffective. To overcome this issue, we propose a novel approach called RaDis (Rationale Distillation). RaDis harnesses the strong generative capabilities of LLMs to create rationales for training data, which are then "replayed" to prevent forgetting. These rationales encapsulate general knowledge and safety principles, acting as self-distillation targets to regulate the training process. By jointly training on both reference translations and self-generated rationales, the model can learn new translation skills while preserving its overall general abilities. Extensive experiments demonstrate that our method enhances machine translation performance while maintaining the broader capabilities of LLMs across other tasks. This work presents a pathway for creating more versatile LLMs that excel in specialized tasks without compromising generality and safety.
Language Imbalance Driven Rewarding for Multilingual Self-improving
Oct 11, 2024Large Language Models (LLMs) have achieved state-of-the-art performance across numerous tasks. However, these advancements have predominantly benefited "first-class" languages such as English and Chinese, leaving many other languages underrepresented. This imbalance, while limiting broader applications, generates a natural preference ranking between languages, offering an opportunity to bootstrap the multilingual capabilities of LLM in a self-improving manner. Thus, we propose $\textit{Language Imbalance Driven Rewarding}$, where the inherent imbalance between dominant and non-dominant languages within LLMs is leveraged as a reward signal. Iterative DPO training demonstrates that this approach not only enhances LLM performance in non-dominant languages but also improves the dominant language's capacity, thereby yielding an iterative reward signal. Fine-tuning Meta-Llama-3-8B-Instruct over two iterations of this approach results in continuous improvements in multilingual performance across instruction-following and arithmetic reasoning tasks, evidenced by an average improvement of 7.46% win rate on the X-AlpacaEval leaderboard and 13.9% accuracy on the MGSM benchmark. This work serves as an initial exploration, paving the way for multilingual self-improvement of LLMs.
Hit the Sweet Spot! Span-Level Ensemble for Large Language Models
Sep 27, 2024



Ensembling various LLMs to unlock their complementary potential and leverage their individual strengths is highly valuable. Previous studies typically focus on two main paradigms: sample-level and token-level ensembles. Sample-level ensemble methods either select or blend fully generated outputs, which hinders dynamic correction and enhancement of outputs during the generation process. On the other hand, token-level ensemble methods enable real-time correction through fine-grained ensemble at each generation step. However, the information carried by an individual token is quite limited, leading to suboptimal decisions at each step. To address these issues, we propose SweetSpan, a span-level ensemble method that effectively balances the need for real-time adjustments and the information required for accurate ensemble decisions. Our approach involves two key steps: First, we have each candidate model independently generate candidate spans based on the shared prefix. Second, we calculate perplexity scores to facilitate mutual evaluation among the candidate models and achieve robust span selection by filtering out unfaithful scores. To comprehensively evaluate ensemble methods, we propose a new challenging setting (ensemble models with significant performance gaps) in addition to the standard setting (ensemble the best-performing models) to assess the performance of model ensembles in more realistic scenarios. Experimental results in both standard and challenging settings across various language generation tasks demonstrate the effectiveness, robustness, and versatility of our approach compared with previous ensemble methods.
BLSP-Emo: Towards Empathetic Large Speech-Language Models
Jun 06, 2024The recent release of GPT-4o showcased the potential of end-to-end multimodal models, not just in terms of low latency but also in their ability to understand and generate expressive speech with rich emotions. While the details are unknown to the open research community, it likely involves significant amounts of curated data and compute, neither of which is readily accessible. In this paper, we present BLSP-Emo (Bootstrapped Language-Speech Pretraining with Emotion support), a novel approach to developing an end-to-end speech-language model capable of understanding both semantics and emotions in speech and generate empathetic responses. BLSP-Emo utilizes existing speech recognition (ASR) and speech emotion recognition (SER) datasets through a two-stage process. The first stage focuses on semantic alignment, following recent work on pretraining speech-language models using ASR data. The second stage performs emotion alignment with the pretrained speech-language model on an emotion-aware continuation task constructed from SER data. Our experiments demonstrate that the BLSP-Emo model excels in comprehending speech and delivering empathetic responses, both in instruction-following tasks and conversations.
F-MALLOC: Feed-forward Memory Allocation for Continual Learning in Neural Machine Translation
Apr 07, 2024In the evolving landscape of Neural Machine Translation (NMT), the pretrain-then-finetune paradigm has yielded impressive results. However, the persistent challenge of Catastrophic Forgetting (CF) remains a hurdle. While previous work has introduced Continual Learning (CL) methods to address CF, these approaches grapple with the delicate balance between avoiding forgetting and maintaining system extensibility. To address this, we propose a CL method, named $\textbf{F-MALLOC}$ ($\textbf{F}$eed-forward $\textbf{M}$emory $\textbf{ALLOC}ation)$. F-MALLOC is inspired by recent insights highlighting that feed-forward layers emulate neural memories and encapsulate crucial translation knowledge. It decomposes feed-forward layers into discrete memory cells and allocates these memories to different tasks. By learning to allocate and safeguard these memories, our method effectively alleviates CF while ensuring robust extendability. Besides, we propose a comprehensive assessment protocol for multi-stage CL of NMT systems. Experiments conducted following this new protocol showcase the superior performance of F-MALLOC, evidenced by higher BLEU scores and almost zero forgetting.
BLSP: Bootstrapping Language-Speech Pre-training via Behavior Alignment of Continuation Writing
Sep 02, 2023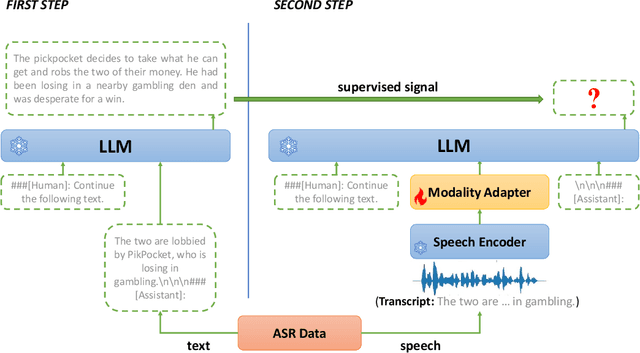


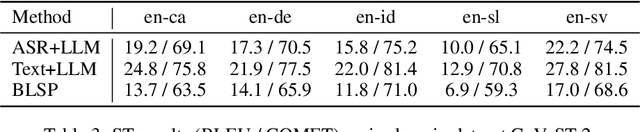
The emergence of large language models (LLMs) has sparked significant interest in extending their remarkable language capabilities to speech. However, modality alignment between speech and text still remains an open problem. Current solutions can be categorized into two strategies. One is a cascaded approach where outputs (tokens or states) of a separately trained speech recognition system are used as inputs for LLMs, which limits their potential in modeling alignment between speech and text. The other is an end-to-end approach that relies on speech instruction data, which is very difficult to collect in large quantities. In this paper, we address these issues and propose the BLSP approach that Bootstraps Language-Speech Pre-training via behavior alignment of continuation writing. We achieve this by learning a lightweight modality adapter between a frozen speech encoder and an LLM, ensuring that the LLM exhibits the same generation behavior regardless of the modality of input: a speech segment or its transcript. The training process can be divided into two steps. The first step prompts an LLM to generate texts with speech transcripts as prefixes, obtaining text continuations. In the second step, these continuations are used as supervised signals to train the modality adapter in an end-to-end manner. We demonstrate that this straightforward process can extend the capabilities of LLMs to speech, enabling speech recognition, speech translation, spoken language understanding, and speech conversation, even in zero-shot cross-lingual scenarios.