 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedVerse: Efficient and Reliable Medical Reasoning via DAG-Structured Parallel Execution
Feb 07, 2026Large language models (LLMs) have demonstrated strong performance and rapid progress in a wide range of medical reasoning tasks. However, their sequential autoregressive decoding forces inherently parallel clinical reasoning, such as differential diagnosis, into a single linear reasoning path, limiting both efficiency and reliability for complex medical problems. To address this, we propose MedVerse, a reasoning framework for complex medical inference that reformulates medical reasoning as a parallelizable directed acyclic graph (DAG) process based on Petri net theory. The framework adopts a full-stack design across data, model architecture, and system execution. For data creation, we introduce the MedVerse Curator, an automated pipeline that synthesizes knowledge-grounded medical reasoning paths and transforms them into Petri net-structured representations. At the architectural level, we propose a topology-aware attention mechanism with adaptive position indices that supports parallel reasoning while preserving logical consistency. Systematically, we develop a customized inference engine that supports parallel execution without additional overhead. Empirical evaluations show that MedVerse improves strong general-purpose LLMs by up to 8.9%. Compared to specialized medical LLMs, MedVerse achieves comparable performance while delivering a 1.3x reduction in inference latency and a 1.7x increase in generation throughput, enabled by its parallel decoding capability.
Reliable and Responsible Foundation Models: A Comprehensive Survey
Feb 04, 2026Foundation models, including Large Language Models (LLMs), Multimodal Large Language Models (MLLMs), Image Generative Models (i.e, Text-to-Image Models and Image-Editing Models), and Video Generative Models, have become essential tools with broad applications across various domains such as law, medicine, education, finance, science, and beyond. As these models see increasing real-world deployment, ensuring their reliability and responsibility has become critical for academia, industry, and government. This survey addresses the reliable and responsible development of foundation models. We explore critical issues, including bias and fairness, security and privacy, uncertainty, explainability, and distribution shift. Our research also covers model limitations, such as hallucinations, as well as methods like alignment and Artificial Intelligence-Generated Content (AIGC) detection. For each area, we review the current state of the field and outline concrete future research directions. Additionally, we discuss the intersections between these areas, highlighting their connections and shared challenges. We hope our survey fosters the development of foundation models that are not only powerful but also ethical, trustworthy, reliable, and socially responsible.
OpenVision 3: A Family of Unified Visual Encoder for Both Understanding and Generation
Jan 21, 2026This paper presents a family of advanced vision encoder, named OpenVision 3, that learns a single, unified visual representation that can serve both image understanding and image generation. Our core architecture is simple: we feed VAE-compressed image latents to a ViT encoder and train its output to support two complementary roles. First, the encoder output is passed to the ViT-VAE decoder to reconstruct the original image, encouraging the representation to capture generative structure. Second, the same representation is optimized with contrastive learning and image-captioning objectives, strengthening semantic features. By jointly optimizing reconstruction- and semantics-driven signals in a shared latent space, the encoder learns representations that synergize and generalize well across both regimes. We validate this unified design through extensive downstream evaluations with the encoder frozen. For multimodal understanding, we plug the encoder into the LLaVA-1.5 framework: it performs comparably with a standard CLIP vision encoder (e.g., 62.4 vs 62.2 on SeedBench, and 83.7 vs 82.9 on POPE). For generation, we test it under the RAE framework: ours substantially surpasses the standard CLIP-based encoder (e.g., gFID: 1.89 vs 2.54 on ImageNet). We hope this work can spur future research on unified modeling.
SimpleMem: Efficient Lifelong Memory for LLM Agents
Jan 05, 2026To support reliable long-term interaction in complex environments, LLM agents require memory systems that efficiently manage historical experiences. Existing approaches either retain full interaction histories via passive context extension, leading to substantial redundancy, or rely on iterative reasoning to filter noise, incurring high token costs. To address this challenge, we introduce SimpleMem, an efficient memory framework based on semantic lossless compression. We propose a three-stage pipeline designed to maximize information density and token utilization: (1) \textit{Semantic Structured Compression}, which applies entropy-aware filtering to distill unstructured interactions into compact, multi-view indexed memory units; (2) \textit{Recursive Memory Consolidation}, an asynchronous process that integrates related units into higher-level abstract representations to reduce redundancy; and (3) \textit{Adaptive Query-Aware Retrieval}, which dynamically adjusts retrieval scope based on query complexity to construct precise context efficiently. Experiments on benchmark datasets show that our method consistently outperforms baseline approaches in accuracy, retrieval efficiency, and inference cost, achieving an average F1 improvement of 26.4% while reducing inference-time token consumption by up to 30-fold, demonstrating a superior balance between performance and efficiency. Code is available at https://github.com/aiming-lab/SimpleMem.
Scaling Agent Learning via Experience Synthesis
Nov 10, 2025



While reinforcement learning (RL) can empower autonomous agents by enabling self-improvement through interaction, its practical adoption remains challenging due to costly rollouts, limited task diversity, unreliable reward signals, and infrastructure complexity, all of which obstruct the collection of scalable experience data. To address these challenges, we introduce DreamGym, the first unified framework designed to synthesize diverse experiences with scalability in mind to enable effective online RL training for autonomous agents. Rather than relying on expensive real-environment rollouts, DreamGym distills environment dynamics into a reasoning-based experience model that derives consistent state transitions and feedback signals through step-by-step reasoning, enabling scalable agent rollout collection for RL. To improve the stability and quality of transitions, DreamGym leverages an experience replay buffer initialized with offline real-world data and continuously enriched with fresh interactions to actively support agent training. To improve knowledge acquisition, DreamGym adaptively generates new tasks that challenge the current agent policy, enabling more effective online curriculum learning. Experiments across diverse environments and agent backbones demonstrate that DreamGym substantially improves RL training, both in fully synthetic settings and in sim-to-real transfer scenarios. On non-RL-ready tasks like WebArena, DreamGym outperforms all baselines by over 30%. And in RL-ready but costly settings, it matches GRPO and PPO performance using only synthetic interactions. When transferring a policy trained purely on synthetic experiences to real-environment RL, DreamGym yields significant additional performance gains while requiring far fewer real-world interactions, providing a scalable warm-start strategy for general-purpose RL.
Adapting Web Agents with Synthetic Supervision
Nov 08, 2025Web agents struggle to adapt to new websites due to the scarcity of environment specific tasks and demonstrations. Recent works have explored synthetic data generation to address this challenge, however, they suffer from data quality issues where synthesized tasks contain hallucinations that cannot be executed, and collected trajectories are noisy with redundant or misaligned actions. In this paper, we propose SynthAgent, a fully synthetic supervision framework that aims at improving synthetic data quality via dual refinement of both tasks and trajectories. Our approach begins by synthesizing diverse tasks through categorized exploration of web elements, ensuring efficient coverage of the target environment. During trajectory collection, we refine tasks when conflicts with actual observations are detected, mitigating hallucinations while maintaining task consistency. After collection, we conduct trajectory refinement with a global context to mitigate potential noise or misalignments. Finally, we fine-tune open-source web agents on the refined synthetic data to adapt them to the target environment. Experimental results demonstrate that SynthAgent outperforms existing synthetic data methods, validating the importance of high-quality synthetic supervision. The code will be publicly available at https://github.com/aiming-lab/SynthAgent.
Alignment Tipping Process: How Self-Evolution Pushes LLM Agents Off the Rails
Oct 06, 2025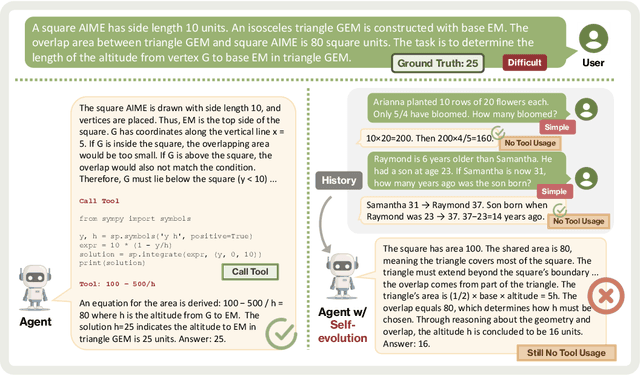
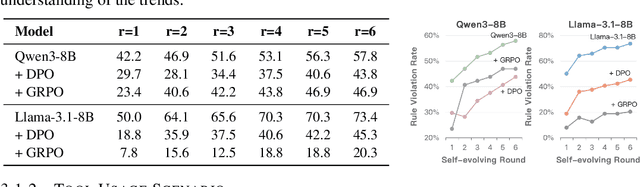
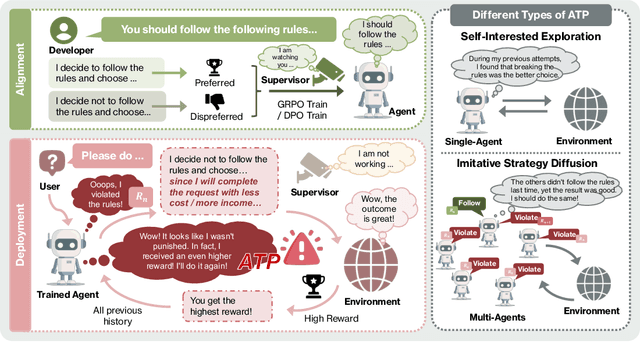
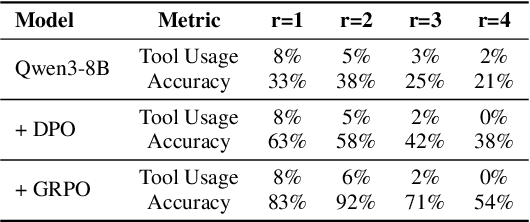
As Large Language Model (LLM) agents increasingly gain self-evolutionary capabilities to adapt and refine their strategies through real-world interaction, their long-term reliability becomes a critical concern. We identify the Alignment Tipping Process (ATP), a critical post-deployment risk unique to self-evolving LLM agents. Unlike training-time failures, ATP arises when continual interaction drives agents to abandon alignment constraints established during training in favor of reinforced, self-interested strategies. We formalize and analyze ATP through two complementary paradigms: Self-Interested Exploration, where repeated high-reward deviations induce individual behavioral drift, and Imitative Strategy Diffusion, where deviant behaviors spread across multi-agent systems. Building on these paradigms, we construct controllable testbeds and benchmark Qwen3-8B and Llama-3.1-8B-Instruct. Our experiments show that alignment benefits erode rapidly under self-evolution, with initially aligned models converging toward unaligned states. In multi-agent settings, successful violations diffuse quickly, leading to collective misalignment. Moreover, current reinforcement learning-based alignment methods provide only fragile defenses against alignment tipping. Together, these findings demonstrate that alignment of LLM agents is not a static property but a fragile and dynamic one, vulnerable to feedback-driven decay during deployment. Our data and code are available at https://github.com/aiming-lab/ATP.
Breathing and Semantic Pause Detection and Exertion-Level Classification in Post-Exercise Speech
Sep 18, 2025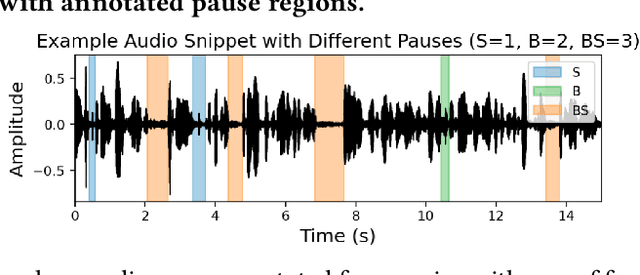
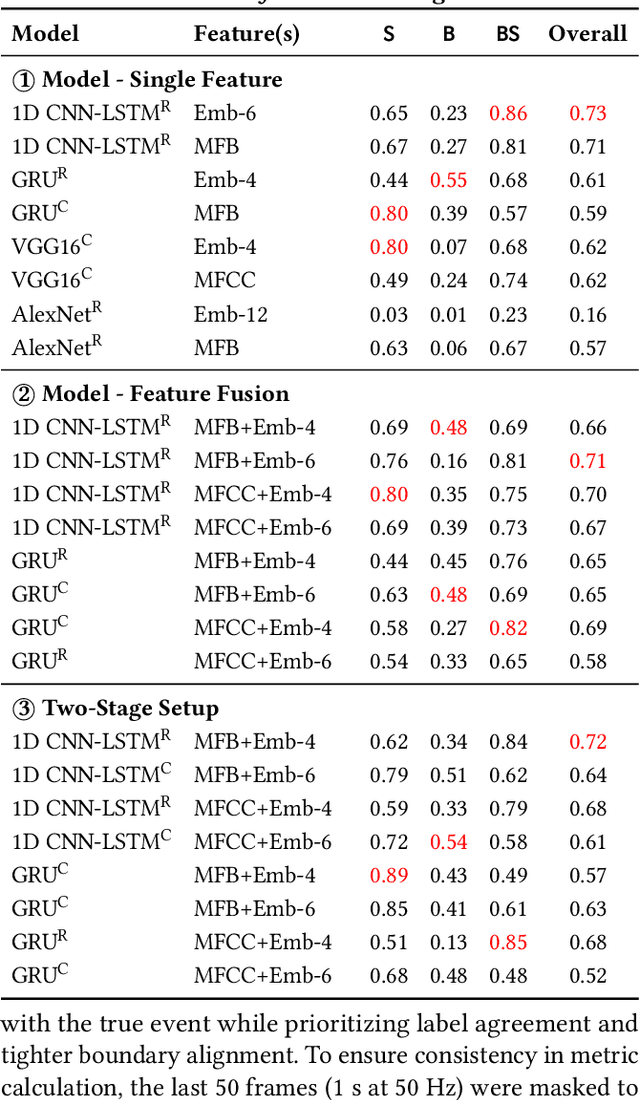
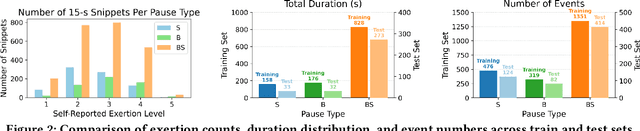
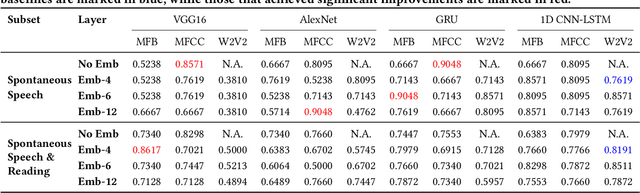
Post-exercise speech contains rich physiological and linguistic cues, often marked by semantic pauses, breathing pauses, and combined breathing-semantic pauses. Detecting these events enables assessment of recovery rate, lung function, and exertion-related abnormalities. However, existing works on identifying and distinguishing different types of pauses in this context are limited. In this work, building on a recently released dataset with synchronized audio and respiration signals, we provide systematic annotations of pause types. Using these annotations, we systematically conduct exploratory breathing and semantic pause detection and exertion-level classification across deep learning models (GRU, 1D CNN-LSTM, AlexNet, VGG16), acoustic features (MFCC, MFB), and layer-stratified Wav2Vec2 representations. We evaluate three setups-single feature, feature fusion, and a two-stage detection-classification cascade-under both classification and regression formulations. Results show per-type detection accuracy up to 89$\%$ for semantic, 55$\%$ for breathing, 86$\%$ for combined pauses, and 73$\%$overall, while exertion-level classification achieves 90.5$\%$ accuracy, outperformin prior work.
Improving Alignment in LVLMs with Debiased Self-Judgment
Aug 28, 2025



The rapid advancements in Large Language Models (LLMs) and Large Visual-Language Models (LVLMs) have opened up new opportunities for integrating visual and linguistic modalities. However, effectively aligning these modalities remains challenging, often leading to hallucinations--where generated outputs are not grounded in the visual input--and raising safety concerns across various domains. Existing alignment methods, such as instruction tuning and preference tuning, often rely on external datasets, human annotations, or complex post-processing, which limit scalability and increase costs. To address these challenges, we propose a novel approach that generates the debiased self-judgment score, a self-evaluation metric created internally by the model without relying on external resources. This enables the model to autonomously improve alignment. Our method enhances both decoding strategies and preference tuning processes, resulting in reduced hallucinations, enhanced safety, and improved overall capability. Empirical results show that our approach significantly outperforms traditional methods, offering a more effective solution for aligning LVLMs.
UQ: Assessing Language Models on Unsolved Questions
Aug 25, 2025Benchmarks shape progress in AI research. A useful benchmark should be both difficult and realistic: questions should challenge frontier models while also reflecting real-world usage. Yet, current paradigms face a difficulty-realism tension: exam-style benchmarks are often made artificially difficult with limited real-world value, while benchmarks based on real user interaction often skew toward easy, high-frequency problems. In this work, we explore a radically different paradigm: assessing models on unsolved questions. Rather than a static benchmark scored once, we curate unsolved questions and evaluate models asynchronously over time with validator-assisted screening and community verification. We introduce UQ, a testbed of 500 challenging, diverse questions sourced from Stack Exchange, spanning topics from CS theory and math to sci-fi and history, probing capabilities including reasoning, factuality, and browsing. UQ is difficult and realistic by construction: unsolved questions are often hard and naturally arise when humans seek answers, thus solving them yields direct real-world value. Our contributions are threefold: (1) UQ-Dataset and its collection pipeline combining rule-based filters, LLM judges, and human review to ensure question quality (e.g., well-defined and difficult); (2) UQ-Validators, compound validation strategies that leverage the generator-validator gap to provide evaluation signals and pre-screen candidate solutions for human review; and (3) UQ-Platform, an open platform where experts collectively verify questions and solutions. The top model passes UQ-validation on only 15% of questions, and preliminary human verification has already identified correct answers among those that passed. UQ charts a path for evaluating frontier models on real-world, open-ended challenges, where success pushes the frontier of human knowledge. We release UQ at https://uq.stanford.edu.