 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREDI-Match: Rotation-Equivariant Distillation for Efficient and Robust Dense Matching
Jun 23, 2026Vision Foundation Models (VFMs) have significantly advanced dense feature matching, yet severe in-plane rotation remains a critical challenge. Existing solutions face a fundamental dilemma: data-driven methods require inefficient parameter scaling to implicitly learn rotations, whereas strictly equivariant networks lack the semantic capacity of modern VFMs. Consequently, current frameworks typically freeze VFMs and shift the entire burden of rotation generalization to the downstream decoder. To break this architectural bottleneck, we propose REDI-Match, an efficient framework driven by a novel Rotation-Equivariant Distillation (REDI) paradigm. Instead of relying on rotation data augmentation to establish rotational correspondences, REDI distills the non-equivariant semantic representations of a VFM into a lightweight, strictly rotation-equivariant encoder, leveraging an equivariant geometric architecture to constrain robust high-dimensional semantics. To fully exploit these features, we equip the decoder with an entropy-driven spatial alignment module. By evaluating discrete rotation hypotheses, this mechanism explicitly locks onto the canonical coordinate system, eliminating global ambiguity before continuous refinement. Extensive experiments demonstrate that REDI-Match establishes a new state-of-the-art (SOTA) across multiple benchmarks. Notably, it achieves a 13.89% absolute pose accuracy improvement on the highly challenging SatAst dataset while operating 1.9x faster than the current SOTA (RoMa v2), enabling real-time inference (~41 FPS) on a single RTX 4090 GPU. Code: https://github.com/YinjiGe/REDI-Match.
CUPID in the Model Zoo: Online Matchmaking for Selecting Your Dream LLM
May 30, 2026Users increasingly face the challenge of selecting an appropriate LLM for a given task from a rapidly growing pool of LLMs, each with distinct but often opaque latent properties. Compounding this challenge, users may lack the vocabulary or awareness to explicitly articulate the characteristics they value in an LLM's responses or deployment. We propose an interaction-efficient active learning framework in which a dueling bandit algorithm iteratively selects pairs of LLMs, collects user feedback about their responses, and updates its belief about the user's latent preferences. We introduce a novel belief-aware upper confidence bound strategy that balances exploration of the model pool with exploitation of inferred preferences, enabling efficient alignment between user needs and LLM capabilities under user-specified cost and time budgets. Through diverse experiments on LLMs and human studies, we experimentally verify that our model can efficiently match well-aligned LLMs to users at a lower cost.
LLM Routing as Reasoning: A MaxSAT View
Mar 13, 2026Routing a query through an appropriate LLM is challenging, particularly when user preferences are expressed in natural language and model attributes are only partially observable. We propose a constraint-based interpretation of language-conditioned LLM routing, formulating it as a weighted MaxSAT/MaxSMT problem in which natural language feedback induces hard and soft constraints over model attributes. Under this view, routing corresponds to selecting models that approximately maximize satisfaction of feedback-conditioned clauses. Empirical analysis on a 25-model benchmark shows that language feedback produces near-feasible recommendation sets, while no-feedback scenarios reveal systematic priors. Our results suggest that LLM routing can be understood as structured constraint optimization under language-conditioned preferences.
Humanoid Factors: Design Principles for AI Humanoids in Human Worlds
Feb 10, 2026Human factors research has long focused on optimizing environments, tools, and systems to account for human performance. Yet, as humanoid robots begin to share our workplaces, homes, and public spaces, the design challenge expands. We must now consider not only factors for humans but also factors for humanoids, since both will coexist and interact within the same environments. Unlike conventional machines, humanoids introduce expectations of human-like behavior, communication, and social presence, which reshape usability, trust, and safety considerations. In this article, we introduce the concept of humanoid factors as a framework structured around four pillars - physical, cognitive, social, and ethical - that shape the development of humanoids to help them effectively coexist and collaborate with humans. This framework characterizes the overlap and divergence between human capabilities and those of general-purpose humanoids powered by AI foundation models. To demonstrate our framework's practical utility, we then apply the framework to evaluate a real-world humanoid control algorithm, illustrating how conventional task completion metrics in robotics overlook key human cognitive and interaction principles. We thus position humanoid factors as a foundational framework for designing, evaluating, and governing sustained human-humanoid coexistence.
Geospatial-Reasoning-Driven Vocabulary-Agnostic Remote Sensing Semantic Segmentation
Feb 09, 2026Open-vocabulary semantic segmentation has emerged as a promising research direction in remote sensing, enabling the recognition of diverse land-cover types beyond pre-defined category sets. However, existing methods predominantly rely on the passive mapping of visual features and textual embeddings. This ``appearance-based" paradigm lacks geospatial contextual awareness, leading to severe semantic ambiguity and misclassification when encountering land-cover classes with similar spectral features but distinct semantic attributes. To address this, we propose a Geospatial Reasoning Chain-of-Thought (GR-CoT) framework designed to enhance the scene understanding capabilities of Multimodal Large Language Models (MLLMs), thereby guiding open-vocabulary segmentation models toward precise mapping. The framework comprises two collaborative components: an offline knowledge distillation stream and an online instance reasoning stream. The offline stream establishes fine-grained category interpretation standards to resolve semantic conflicts between similar land-cover types. During online inference, the framework executes a sequential reasoning process involving macro-scenario anchoring, visual feature decoupling, and knowledge-driven decision synthesis. This process generates an image-adaptive vocabulary that guides downstream models to achieve pixel-level alignment with correct geographical semantics. Extensive experiments on the LoveDA and GID5 benchmarks demonstrate the superiority of our approach.
TowerMind: A Tower Defence Game Learning Environment and Benchmark for LLM as Agents
Jan 09, 2026Recent breakthroughs in Large Language Models (LLMs) have positioned them as a promising paradigm for agents, with long-term planning and decision-making emerging as core general-purpose capabilities for adapting to diverse scenarios and tasks. Real-time strategy (RTS) games serve as an ideal testbed for evaluating these two capabilities, as their inherent gameplay requires both macro-level strategic planning and micro-level tactical adaptation and action execution. Existing RTS game-based environments either suffer from relatively high computational demands or lack support for textual observations, which has constrained the use of RTS games for LLM evaluation. Motivated by this, we present TowerMind, a novel environment grounded in the tower defense (TD) subgenre of RTS games. TowerMind preserves the key evaluation strengths of RTS games for assessing LLMs, while featuring low computational demands and a multimodal observation space, including pixel-based, textual, and structured game-state representations. In addition, TowerMind supports the evaluation of model hallucination and provides a high degree of customizability. We design five benchmark levels to evaluate several widely used LLMs under different multimodal input settings. The results reveal a clear performance gap between LLMs and human experts across both capability and hallucination dimensions. The experiments further highlight key limitations in LLM behavior, such as inadequate planning validation, a lack of multifinality in decision-making, and inefficient action use. We also evaluate two classic reinforcement learning algorithms: Ape-X DQN and PPO. By offering a lightweight and multimodal design, TowerMind complements the existing RTS game-based environment landscape and introduces a new benchmark for the AI agent field. The source code is publicly available on GitHub(https://github.com/tb6147877/TowerMind).
Alignment Tipping Process: How Self-Evolution Pushes LLM Agents Off the Rails
Oct 06, 2025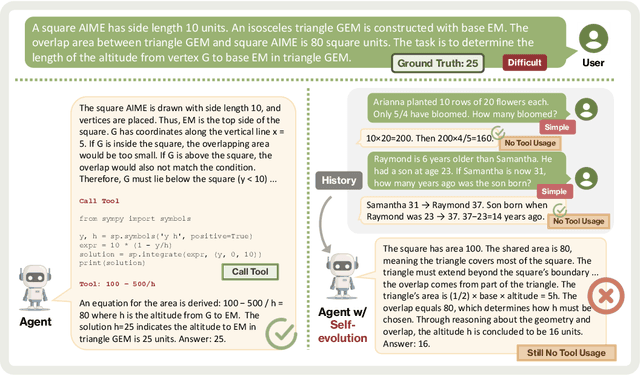
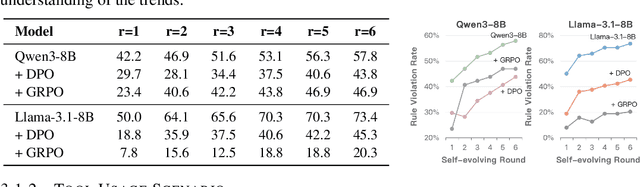
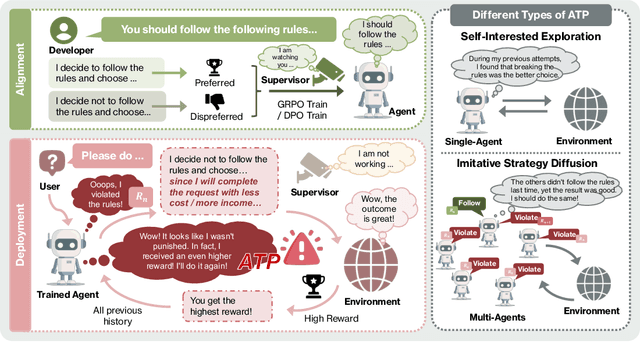
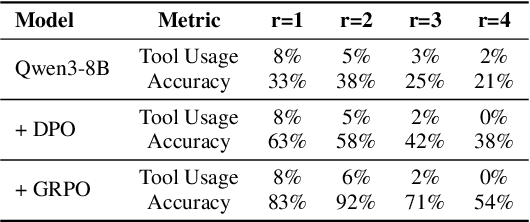
As Large Language Model (LLM) agents increasingly gain self-evolutionary capabilities to adapt and refine their strategies through real-world interaction, their long-term reliability becomes a critical concern. We identify the Alignment Tipping Process (ATP), a critical post-deployment risk unique to self-evolving LLM agents. Unlike training-time failures, ATP arises when continual interaction drives agents to abandon alignment constraints established during training in favor of reinforced, self-interested strategies. We formalize and analyze ATP through two complementary paradigms: Self-Interested Exploration, where repeated high-reward deviations induce individual behavioral drift, and Imitative Strategy Diffusion, where deviant behaviors spread across multi-agent systems. Building on these paradigms, we construct controllable testbeds and benchmark Qwen3-8B and Llama-3.1-8B-Instruct. Our experiments show that alignment benefits erode rapidly under self-evolution, with initially aligned models converging toward unaligned states. In multi-agent settings, successful violations diffuse quickly, leading to collective misalignment. Moreover, current reinforcement learning-based alignment methods provide only fragile defenses against alignment tipping. Together, these findings demonstrate that alignment of LLM agents is not a static property but a fragile and dynamic one, vulnerable to feedback-driven decay during deployment. Our data and code are available at https://github.com/aiming-lab/ATP.
Semantic-decoupled Spatial Partition Guided Point-supervised Oriented Object Detection
Jun 12, 2025Recent remote sensing tech advancements drive imagery growth, making oriented object detection rapid development, yet hindered by labor-intensive annotation for high-density scenes. Oriented object detection with point supervision offers a cost-effective solution for densely packed scenes in remote sensing, yet existing methods suffer from inadequate sample assignment and instance confusion due to rigid rule-based designs. To address this, we propose SSP (Semantic-decoupled Spatial Partition), a unified framework that synergizes rule-driven prior injection and data-driven label purification. Specifically, SSP introduces two core innovations: 1) Pixel-level Spatial Partition-based Sample Assignment, which compactly estimates the upper and lower bounds of object scales and mines high-quality positive samples and hard negative samples through spatial partitioning of pixel maps. 2) Semantic Spatial Partition-based Box Extraction, which derives instances from spatial partitions modulated by semantic maps and reliably converts them into bounding boxes to form pseudo-labels for supervising the learning of downstream detectors. Experiments on DOTA-v1.0 and others demonstrate SSP\' s superiority: it achieves 45.78% mAP under point supervision, outperforming SOTA method PointOBB-v2 by 4.10%. Furthermore, when integrated with ORCNN and ReDet architectures, the SSP framework achieves mAP values of 47.86% and 48.50%, respectively. The code is available at https://github.com/antxinyuan/ssp.
Neural-Augmented Kelvinlet: Real-Time Soft Tissue Deformation with Multiple Graspers
Jun 06, 2025Fast and accurate simulation of soft tissue deformation is a critical factor for surgical robotics and medical training. In this paper, we introduce a novel physics-informed neural simulator that approximates soft tissue deformations in a realistic and real-time manner. Our framework integrates Kelvinlet-based priors into neural simulators, making it the first approach to leverage Kelvinlets for residual learning and regularization in data-driven soft tissue modeling. By incorporating large-scale Finite Element Method (FEM) simulations of both linear and nonlinear soft tissue responses, our method improves neural network predictions across diverse architectures, enhancing accuracy and physical consistency while maintaining low latency for real-time performance. We demonstrate the effectiveness of our approach by performing accurate surgical maneuvers that simulate the use of standard laparoscopic tissue grasping tools with high fidelity. These results establish Kelvinlet-augmented learning as a powerful and efficient strategy for real-time, physics-aware soft tissue simulation in surgical applications.
TopoPoint: Enhance Topology Reasoning via Endpoint Detection in Autonomous Driving
May 23, 2025Topology reasoning, which unifies perception and structured reasoning, plays a vital role in understanding intersections for autonomous driving. However, its performance heavily relies on the accuracy of lane detection, particularly at connected lane endpoints. Existing methods often suffer from lane endpoints deviation, leading to incorrect topology construction. To address this issue, we propose TopoPoint, a novel framework that explicitly detects lane endpoints and jointly reasons over endpoints and lanes for robust topology reasoning. During training, we independently initialize point and lane query, and proposed Point-Lane Merge Self-Attention to enhance global context sharing through incorporating geometric distances between points and lanes as an attention mask . We further design Point-Lane Graph Convolutional Network to enable mutual feature aggregation between point and lane query. During inference, we introduce Point-Lane Geometry Matching algorithm that computes distances between detected points and lanes to refine lane endpoints, effectively mitigating endpoint deviation. Extensive experiments on the OpenLane-V2 benchmark demonstrate that TopoPoint achieves state-of-the-art performance in topology reasoning (48.8 on OLS). Additionally, we propose DET$_p$ to evaluate endpoint detection, under which our method significantly outperforms existing approaches (52.6 v.s. 45.2 on DET$_p$). The code is released at https://github.com/Franpin/TopoPoint.