 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimeSRL: Generalizable Time-Series Behavioral Modeling via Semantic RL-Tuned LLMs -- A Case Study in Mental Health
May 20, 2026Longitudinal passive sensing enables continuous health prediction, yet models often fail under cross-dataset distribution shifts. Traditional ML overfits cohort-specific artifacts, while Large Language Models (LLMs) struggle to reason reliably over long, heterogeneous time-series. We introduce TimeSRL, a two-stage LLM framework that routes predictions through an explicit semantic bottleneck. The model first abstracts raw signals into high-level natural language, then predicts behavioral outcomes from these abstractions alone. This forces the model to reason over semantic concepts that we argue generalize better than raw numbers. We optimize this process end-to-end using Group Relative Policy Optimization (GRPO) with Reinforcement Learning from Verifiable Rewards (RLVR), learning outcome-aligned abstractions without gold intermediate annotations. Instantiated on mental-health prediction, TimeSRL achieves state-of-the-art performance on a benchmark designed to stress-test cross-cohort generalization under a rigorous leave-one-dataset-out (LOSO) protocol, reducing mean absolute error (MAE) over strong non-LLM ML and LLM baselines by 3.1--10.1% and 9.5--44.1% for anxiety, and 3.2--9.6% and 27.4--57.6% for depression (all $p$s<0.05). TimeSRL significantly outperforms prior methods in cross-benchmark transfer across different sensing pipelines, rivaling its own within-domain performance without target-domain fine-tuning. These results demonstrate that semantic abstractions are reusable and point to a new direction for generalizable behavior modeling via RL-tuned LLMs.
Breathing and Semantic Pause Detection and Exertion-Level Classification in Post-Exercise Speech
Sep 18, 2025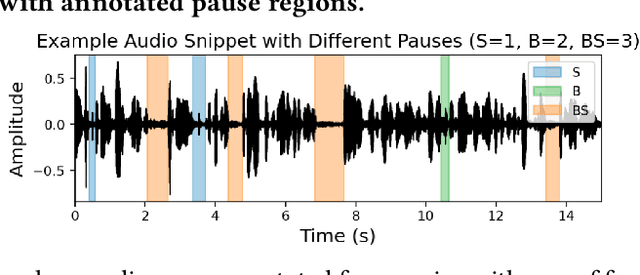
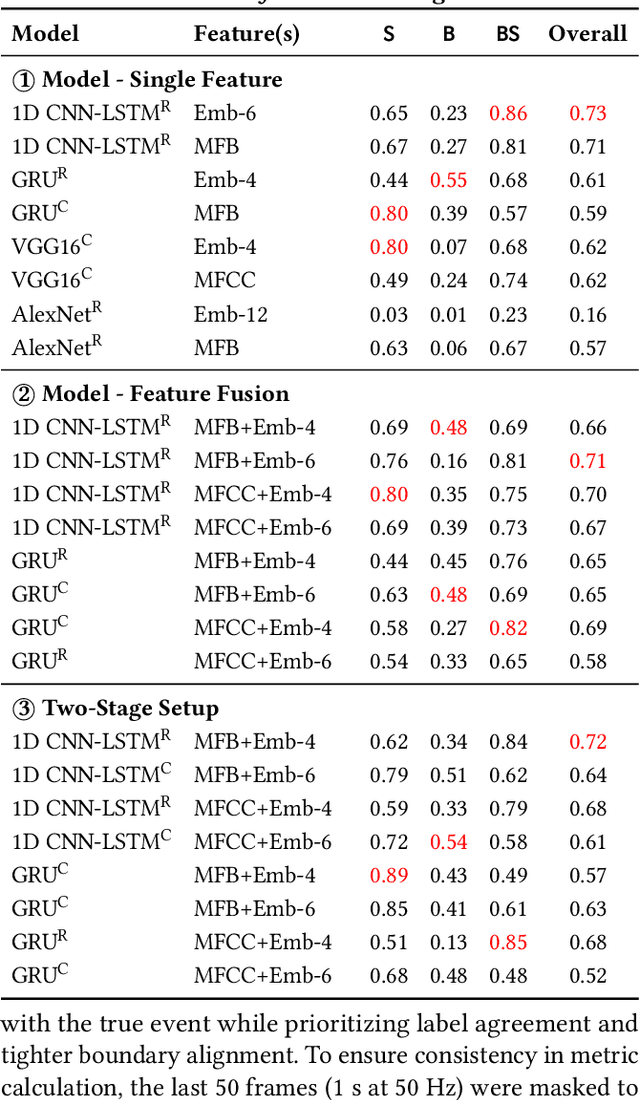
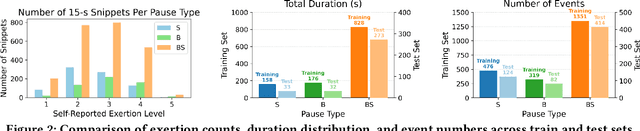
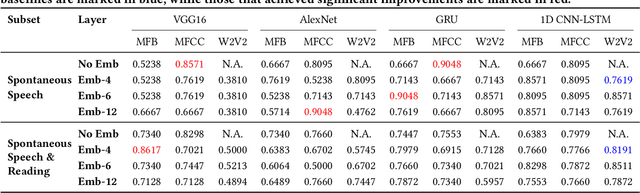
Post-exercise speech contains rich physiological and linguistic cues, often marked by semantic pauses, breathing pauses, and combined breathing-semantic pauses. Detecting these events enables assessment of recovery rate, lung function, and exertion-related abnormalities. However, existing works on identifying and distinguishing different types of pauses in this context are limited. In this work, building on a recently released dataset with synchronized audio and respiration signals, we provide systematic annotations of pause types. Using these annotations, we systematically conduct exploratory breathing and semantic pause detection and exertion-level classification across deep learning models (GRU, 1D CNN-LSTM, AlexNet, VGG16), acoustic features (MFCC, MFB), and layer-stratified Wav2Vec2 representations. We evaluate three setups-single feature, feature fusion, and a two-stage detection-classification cascade-under both classification and regression formulations. Results show per-type detection accuracy up to 89$\%$ for semantic, 55$\%$ for breathing, 86$\%$ for combined pauses, and 73$\%$overall, while exertion-level classification achieves 90.5$\%$ accuracy, outperformin prior work.
Foundation Model Hidden Representations for Heart Rate Estimation from Auscultation
May 29, 2025



Auscultation, particularly heart sound, is a non-invasive technique that provides essential vital sign information. Recently, self-supervised acoustic representation foundation models (FMs) have been proposed to offer insights into acoustics-based vital signs. However, there has been little exploration of the extent to which auscultation is encoded in these pre-trained FM representations. In this work, using a publicly available phonocardiogram (PCG) dataset and a heart rate (HR) estimation model, we conduct a layer-wise investigation of six acoustic representation FMs: HuBERT, wav2vec2, wavLM, Whisper, Contrastive Language-Audio Pretraining (CLAP), and an in-house CLAP model. Additionally, we implement the baseline method from Nie et al., 2024 (which relies on acoustic features) and show that overall, representation vectors from pre-trained foundation models (FMs) offer comparable performance to the baseline. Notably, HR estimation using the representations from the audio encoder of the in-house CLAP model outperforms the results obtained from the baseline, achieving a lower mean absolute error (MAE) across various train/validation/test splits despite the domain mismatch.
Model-driven Heart Rate Estimation and Heart Murmur Detection based on Phonocardiogram
Jul 25, 2024



Acoustic signals are crucial for health monitoring, particularly heart sounds which provide essential data like heart rate and detect cardiac anomalies such as murmurs. This study utilizes a publicly available phonocardiogram (PCG) dataset to estimate heart rate using model-driven methods and extends the best-performing model to a multi-task learning (MTL) framework for simultaneous heart rate estimation and murmur detection. Heart rate estimates are derived using a sliding window technique on heart sound snippets, analyzed with a combination of acoustic features (Mel spectrogram, cepstral coefficients, power spectral density, root mean square energy). Our findings indicate that a 2D convolutional neural network (\textbf{\texttt{2dCNN}}) is most effective for heart rate estimation, achieving a mean absolute error (MAE) of 1.312 bpm. We systematically investigate the impact of different feature combinations and find that utilizing all four features yields the best results. The MTL model (\textbf{\texttt{2dCNN-MTL}}) achieves accuracy over 95% in murmur detection, surpassing existing models, while maintaining an MAE of 1.636 bpm in heart rate estimation, satisfying the requirements stated by Association for the Advancement of Medical Instrumentation (AAMI).
LLM-based Conversational AI Therapist for Daily Functioning Screening and Psychotherapeutic Intervention via Everyday Smart Devices
Mar 16, 2024



Despite the global mental health crisis, access to screenings, professionals, and treatments remains high. In collaboration with licensed psychotherapists, we propose a Conversational AI Therapist with psychotherapeutic Interventions (CaiTI), a platform that leverages large language models (LLM)s and smart devices to enable better mental health self-care. CaiTI can screen the day-to-day functioning using natural and psychotherapeutic conversations. CaiTI leverages reinforcement learning to provide personalized conversation flow. CaiTI can accurately understand and interpret user responses. When the user needs further attention during the conversation, CaiTI can provide conversational psychotherapeutic interventions, including cognitive behavioral therapy (CBT) and motivational interviewing (MI). Leveraging the datasets prepared by the licensed psychotherapists, we experiment and microbenchmark various LLMs' performance in tasks along CaiTI's conversation flow and discuss their strengths and weaknesses. With the psychotherapists, we implement CaiTI and conduct 14-day and 24-week studies. The study results, validated by therapists, demonstrate that CaiTI can converse with users naturally, accurately understand and interpret user responses, and provide psychotherapeutic interventions appropriately and effectively. We showcase the potential of CaiTI LLMs to assist the mental therapy diagnosis and treatment and improve day-to-day functioning screening and precautionary psychotherapeutic intervention systems.
Investigating salient representations and label Variance in Dimensional Speech Emotion Analysis
Dec 17, 2023



Representations derived from models such as BERT (Bidirectional Encoder Representations from Transformers) and HuBERT (Hidden units BERT), have helped to achieve state-of-the-art performance in dimensional speech emotion recognition. Despite their large dimensionality, and even though these representations are not tailored for emotion recognition tasks, they are frequently used to train large speech emotion models with high memory and computational costs. In this work, we show that there exist lower-dimensional subspaces within the these pre-trained representational spaces that offer a reduction in downstream model complexity without sacrificing performance on emotion estimation. In addition, we model label uncertainty in the form of grader opinion variance, and demonstrate that such information can improve the models generalization capacity and robustness. Finally, we compare the robustness of the emotion models against acoustic degradations and observed that the reduced dimensional representations were able to retain the performance similar to the full-dimensional representations without significant regression in dimensional emotion performance.
* 5 pages
Frequency-Aware Masked Autoencoders for Multimodal Pretraining on Biosignals
Sep 12, 2023



Leveraging multimodal information from biosignals is vital for building a comprehensive representation of people's physical and mental states. However, multimodal biosignals often exhibit substantial distributional shifts between pretraining and inference datasets, stemming from changes in task specification or variations in modality compositions. To achieve effective pretraining in the presence of potential distributional shifts, we propose a frequency-aware masked autoencoder ($\texttt{bio}$FAME) that learns to parameterize the representation of biosignals in the frequency space. $\texttt{bio}$FAME incorporates a frequency-aware transformer, which leverages a fixed-size Fourier-based operator for global token mixing, independent of the length and sampling rate of inputs. To maintain the frequency components within each input channel, we further employ a frequency-maintain pretraining strategy that performs masked autoencoding in the latent space. The resulting architecture effectively utilizes multimodal information during pretraining, and can be seamlessly adapted to diverse tasks and modalities at test time, regardless of input size and order. We evaluated our approach on a diverse set of transfer experiments on unimodal time series, achieving an average of $\uparrow$5.5% improvement in classification accuracy over the previous state-of-the-art. Furthermore, we demonstrated that our architecture is robust in modality mismatch scenarios, including unpredicted modality dropout or substitution, proving its practical utility in real-world applications. Code will be available soon.