 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlignment Tipping Process: How Self-Evolution Pushes LLM Agents Off the Rails
Oct 06, 2025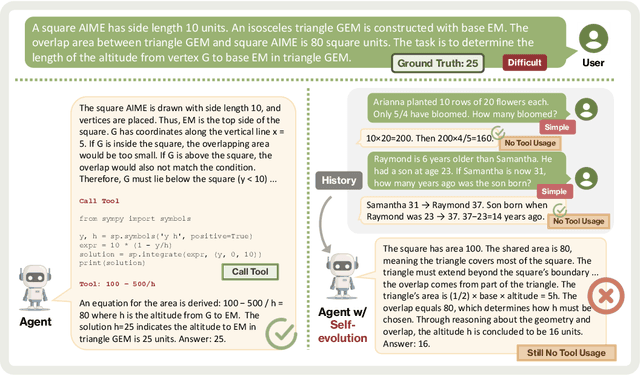
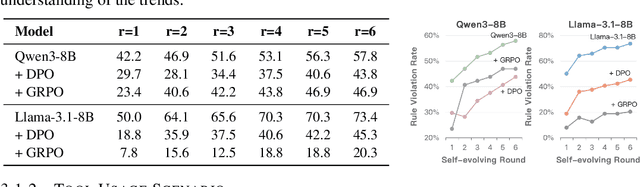
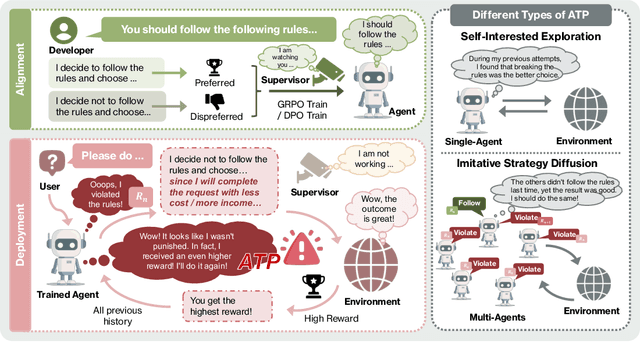
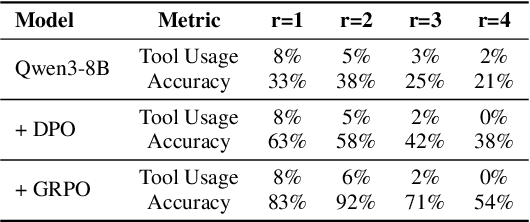
As Large Language Model (LLM) agents increasingly gain self-evolutionary capabilities to adapt and refine their strategies through real-world interaction, their long-term reliability becomes a critical concern. We identify the Alignment Tipping Process (ATP), a critical post-deployment risk unique to self-evolving LLM agents. Unlike training-time failures, ATP arises when continual interaction drives agents to abandon alignment constraints established during training in favor of reinforced, self-interested strategies. We formalize and analyze ATP through two complementary paradigms: Self-Interested Exploration, where repeated high-reward deviations induce individual behavioral drift, and Imitative Strategy Diffusion, where deviant behaviors spread across multi-agent systems. Building on these paradigms, we construct controllable testbeds and benchmark Qwen3-8B and Llama-3.1-8B-Instruct. Our experiments show that alignment benefits erode rapidly under self-evolution, with initially aligned models converging toward unaligned states. In multi-agent settings, successful violations diffuse quickly, leading to collective misalignment. Moreover, current reinforcement learning-based alignment methods provide only fragile defenses against alignment tipping. Together, these findings demonstrate that alignment of LLM agents is not a static property but a fragile and dynamic one, vulnerable to feedback-driven decay during deployment. Our data and code are available at https://github.com/aiming-lab/ATP.
Aime: Towards Fully-Autonomous Multi-Agent Framework
Jul 16, 2025

Multi-Agent Systems (MAS) powered by Large Language Models (LLMs) are emerging as a powerful paradigm for solving complex, multifaceted problems. However, the potential of these systems is often constrained by the prevalent plan-and-execute framework, which suffers from critical limitations: rigid plan execution, static agent capabilities, and inefficient communication. These weaknesses hinder their adaptability and robustness in dynamic environments. This paper introduces Aime, a novel multi-agent framework designed to overcome these challenges through dynamic, reactive planning and execution. Aime replaces the conventional static workflow with a fluid and adaptive architecture. Its core innovations include: (1) a Dynamic Planner that continuously refines the overall strategy based on real-time execution feedback; (2) an Actor Factory that implements Dynamic Actor instantiation, assembling specialized agents on-demand with tailored tools and knowledge; and (3) a centralized Progress Management Module that serves as a single source of truth for coherent, system-wide state awareness. We empirically evaluated Aime on a diverse suite of benchmarks spanning general reasoning (GAIA), software engineering (SWE-bench Verified), and live web navigation (WebVoyager). The results demonstrate that Aime consistently outperforms even highly specialized state-of-the-art agents in their respective domains. Its superior adaptability and task success rate establish Aime as a more resilient and effective foundation for multi-agent collaboration.
WaveFM: A High-Fidelity and Efficient Vocoder Based on Flow Matching
Mar 20, 2025



Flow matching offers a robust and stable approach to training diffusion models. However, directly applying flow matching to neural vocoders can result in subpar audio quality. In this work, we present WaveFM, a reparameterized flow matching model for mel-spectrogram conditioned speech synthesis, designed to enhance both sample quality and generation speed for diffusion vocoders. Since mel-spectrograms represent the energy distribution of waveforms, WaveFM adopts a mel-conditioned prior distribution instead of a standard Gaussian prior to minimize unnecessary transportation costs during synthesis. Moreover, while most diffusion vocoders rely on a single loss function, we argue that incorporating auxiliary losses, including a refined multi-resolution STFT loss, can further improve audio quality. To speed up inference without degrading sample quality significantly, we introduce a tailored consistency distillation method for WaveFM. Experiment results demonstrate that our model achieves superior performance in both quality and efficiency compared to previous diffusion vocoders, while enabling waveform generation in a single inference step.
VisionReward: Fine-Grained Multi-Dimensional Human Preference Learning for Image and Video Generation
Dec 30, 2024We present a general strategy to aligning visual generation models -- both image and video generation -- with human preference. To start with, we build VisionReward -- a fine-grained and multi-dimensional reward model. We decompose human preferences in images and videos into multiple dimensions, each represented by a series of judgment questions, linearly weighted and summed to an interpretable and accurate score. To address the challenges of video quality assessment, we systematically analyze various dynamic features of videos, which helps VisionReward surpass VideoScore by 17.2% and achieve top performance for video preference prediction. Based on VisionReward, we develop a multi-objective preference learning algorithm that effectively addresses the issue of confounding factors within preference data. Our approach significantly outperforms existing image and video scoring methods on both machine metrics and human evaluation. All code and datasets are provided at https://github.com/THUDM/VisionReward.