 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Agents via Continual Pre-training
Sep 16, 2025Large language models (LLMs) have evolved into agentic systems capable of autonomous tool use and multi-step reasoning for complex problem-solving. However, post-training approaches building upon general-purpose foundation models consistently underperform in agentic tasks, particularly in open-source implementations. We identify the root cause: the absence of robust agentic foundation models forces models during post-training to simultaneously learn diverse agentic behaviors while aligning them to expert demonstrations, thereby creating fundamental optimization tensions. To this end, we are the first to propose incorporating Agentic Continual Pre-training (Agentic CPT) into the deep research agents training pipeline to build powerful agentic foundational models. Based on this approach, we develop a deep research agent model named AgentFounder. We evaluate our AgentFounder-30B on 10 benchmarks and achieve state-of-the-art performance while retains strong tool-use ability, notably 39.9% on BrowseComp-en, 43.3% on BrowseComp-zh, and 31.5% Pass@1 on HLE.
WebResearcher: Unleashing unbounded reasoning capability in Long-Horizon Agents
Sep 16, 2025



Recent advances in deep-research systems have demonstrated the potential for AI agents to autonomously discover and synthesize knowledge from external sources. In this paper, we introduce WebResearcher, a novel framework for building such agents through two key components: (1) WebResearcher, an iterative deep-research paradigm that reformulates deep research as a Markov Decision Process, where agents periodically consolidate findings into evolving reports while maintaining focused workspaces, overcoming the context suffocation and noise contamination that plague existing mono-contextual approaches; and (2) WebFrontier, a scalable data synthesis engine that generates high-quality training data through tool-augmented complexity escalation, enabling systematic creation of research tasks that bridge the gap between passive knowledge recall and active knowledge construction. Notably, we find that the training data from our paradigm significantly enhances tool-use capabilities even for traditional mono-contextual methods. Furthermore, our paradigm naturally scales through parallel thinking, enabling concurrent multi-agent exploration for more comprehensive conclusions. Extensive experiments across 6 challenging benchmarks demonstrate that WebResearcher achieves state-of-the-art performance, even surpassing frontier proprietary systems.
Mobile-Agent-v3: Foundamental Agents for GUI Automation
Aug 21, 2025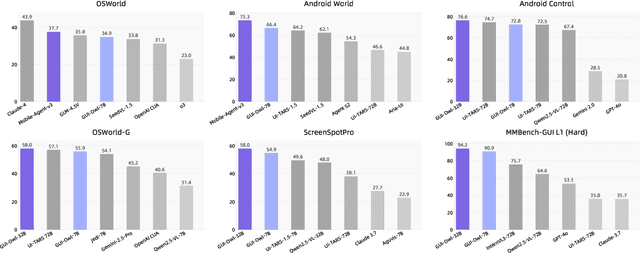
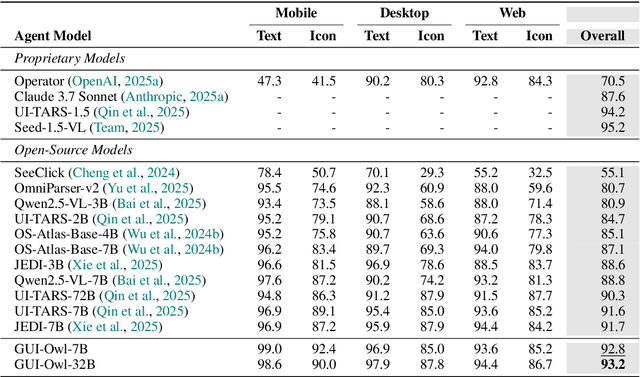
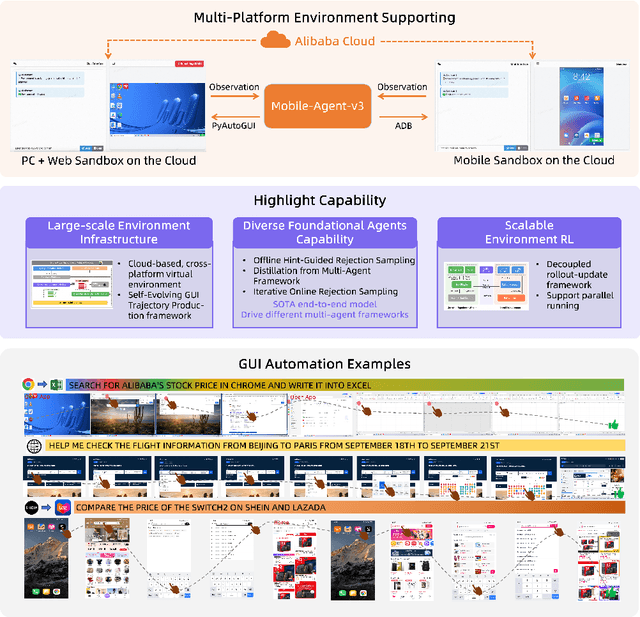
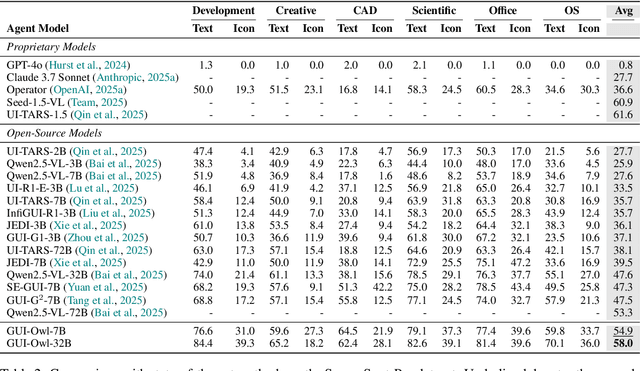
This paper introduces GUI-Owl, a foundational GUI agent model that achieves state-of-the-art performance among open-source end-to-end models on ten GUI benchmarks across desktop and mobile environments, covering grounding, question answering, planning, decision-making, and procedural knowledge. GUI-Owl-7B achieves 66.4 on AndroidWorld and 29.4 on OSWorld. Building on this, we propose Mobile-Agent-v3, a general-purpose GUI agent framework that further improves performance to 73.3 on AndroidWorld and 37.7 on OSWorld, setting a new state-of-the-art for open-source GUI agent frameworks. GUI-Owl incorporates three key innovations: (1) Large-scale Environment Infrastructure: a cloud-based virtual environment spanning Android, Ubuntu, macOS, and Windows, enabling our Self-Evolving GUI Trajectory Production framework. This generates high-quality interaction data via automated query generation and correctness validation, leveraging GUI-Owl to refine trajectories iteratively, forming a self-improving loop. It supports diverse data pipelines and reduces manual annotation. (2) Diverse Foundational Agent Capabilities: by integrating UI grounding, planning, action semantics, and reasoning patterns, GUI-Owl supports end-to-end decision-making and can act as a modular component in multi-agent systems. (3) Scalable Environment RL: we develop a scalable reinforcement learning framework with fully asynchronous training for real-world alignment. We also introduce Trajectory-aware Relative Policy Optimization (TRPO) for online RL, achieving 34.9 on OSWorld. GUI-Owl and Mobile-Agent-v3 are open-sourced at https://github.com/X-PLUG/MobileAgent.
CPO: Addressing Reward Ambiguity in Role-playing Dialogue via Comparative Policy Optimization
Aug 12, 2025Reinforcement Learning Fine-Tuning (RLFT) has achieved notable success in tasks with objectively verifiable answers (e.g., code generation, mathematical reasoning), yet struggles with open-ended subjective tasks like role-playing dialogue. Traditional reward modeling approaches, which rely on independent sample-wise scoring, face dual challenges: subjective evaluation criteria and unstable reward signals.Motivated by the insight that human evaluation inherently combines explicit criteria with implicit comparative judgments, we propose Comparative Policy Optimization (CPO). CPO redefines the reward evaluation paradigm by shifting from sample-wise scoring to comparative group-wise scoring.Building on the same principle, we introduce the CharacterArena evaluation framework, which comprises two stages:(1) Contextualized Multi-turn Role-playing Simulation, and (2) Trajectory-level Comparative Evaluation. By operationalizing subjective scoring via objective trajectory comparisons, CharacterArena minimizes contextual bias and enables more robust and fair performance evaluation. Empirical results on CharacterEval, CharacterBench, and CharacterArena confirm that CPO effectively mitigates reward ambiguity and leads to substantial improvements in dialogue quality.
Memp: Exploring Agent Procedural Memory
Aug 08, 2025Large Language Models (LLMs) based agents excel at diverse tasks, yet they suffer from brittle procedural memory that is manually engineered or entangled in static parameters. In this work, we investigate strategies to endow agents with a learnable, updatable, and lifelong procedural memory. We propose Memp that distills past agent trajectories into both fine-grained, step-by-step instructions and higher-level, script-like abstractions, and explore the impact of different strategies for Build, Retrieval, and Update of procedural memory. Coupled with a dynamic regimen that continuously updates, corrects, and deprecates its contents, this repository evolves in lockstep with new experience. Empirical evaluation on TravelPlanner and ALFWorld shows that as the memory repository is refined, agents achieve steadily higher success rates and greater efficiency on analogous tasks. Moreover, procedural memory built from a stronger model retains its value: migrating the procedural memory to a weaker model yields substantial performance gains.
RL-PLUS: Countering Capability Boundary Collapse of LLMs in Reinforcement Learning with Hybrid-policy Optimization
Jul 31, 2025Reinforcement Learning with Verifiable Reward (RLVR) has significantly advanced the complex reasoning abilities of Large Language Models (LLMs). However, it struggles to break through the inherent capability boundaries of the base LLM, due to its inherently on-policy strategy with LLM's immense action space and sparse reward. Further, RLVR can lead to the capability boundary collapse, narrowing the LLM's problem-solving scope. To address this problem, we propose RL-PLUS, a novel approach that synergizes internal exploitation (i.e., Thinking) with external data (i.e., Learning) to achieve stronger reasoning capabilities and surpass the boundaries of base models. RL-PLUS integrates two core components: Multiple Importance Sampling to address for distributional mismatch from external data, and an Exploration-Based Advantage Function to guide the model towards high-value, unexplored reasoning paths. We provide both theoretical analysis and extensive experiments to demonstrate the superiority and generalizability of our approach. The results show that RL-PLUS achieves state-of-the-art performance compared with existing RLVR methods on six math reasoning benchmarks and exhibits superior performance on six out-of-distribution reasoning tasks. It also achieves consistent and significant gains across diverse model families, with average relative improvements ranging from 21.1\% to 69.2\%. Moreover, Pass@k curves across multiple benchmarks indicate that RL-PLUS effectively resolves the capability boundary collapse problem.
RMTBench: Benchmarking LLMs Through Multi-Turn User-Centric Role-Playing
Jul 27, 2025Recent advancements in Large Language Models (LLMs) have shown outstanding potential for role-playing applications. Evaluating these capabilities is becoming crucial yet remains challenging. Existing benchmarks mostly adopt a \textbf{character-centric} approach, simplify user-character interactions to isolated Q&A tasks, and fail to reflect real-world applications. To address this limitation, we introduce RMTBench, a comprehensive \textbf{user-centric} bilingual role-playing benchmark featuring 80 diverse characters and over 8,000 dialogue rounds. RMTBench includes custom characters with detailed backgrounds and abstract characters defined by simple traits, enabling evaluation across various user scenarios. Our benchmark constructs dialogues based on explicit user motivations rather than character descriptions, ensuring alignment with practical user applications. Furthermore, we construct an authentic multi-turn dialogue simulation mechanism. With carefully selected evaluation dimensions and LLM-based scoring, this mechanism captures the complex intention of conversations between the user and the character. By shifting focus from character background to user intention fulfillment, RMTBench bridges the gap between academic evaluation and practical deployment requirements, offering a more effective framework for assessing role-playing capabilities in LLMs. All code and datasets will be released soon.
Translationese-index: Using Likelihood Ratios for Graded and Generalizable Measurement of Translationese
Jul 16, 2025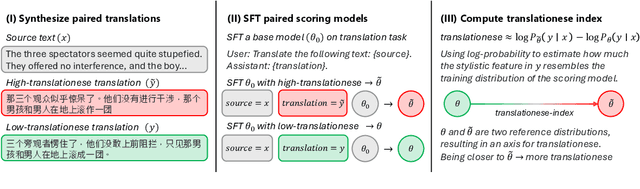
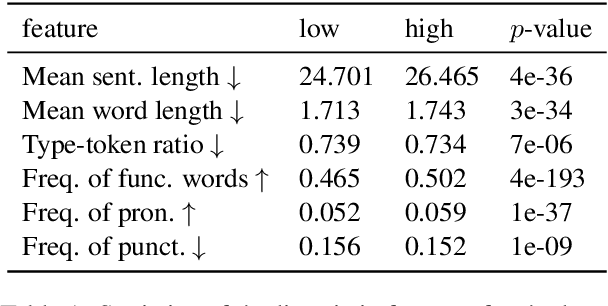
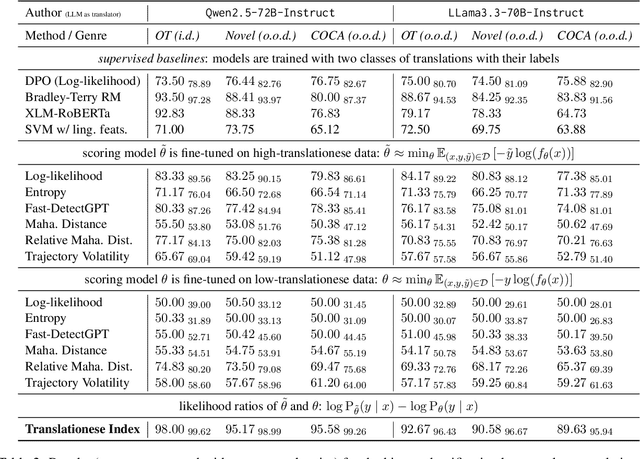
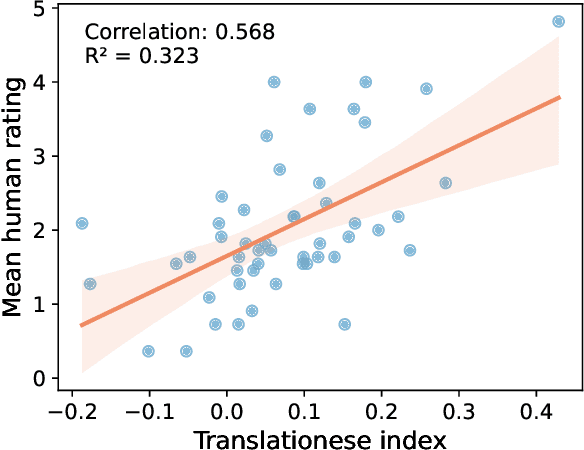
In this paper, we propose the first quantitative measure for translationese -- the translationese-index (T-index) for graded and generalizable measurement of translationese, computed from the likelihood ratios of two contrastively fine-tuned language models (LMs). We use a synthesized dataset and a dataset with translations in the wild to evaluate T-index's generalizability in cross-domain settings and its validity against human judgments. Our results show that T-index is both robust and efficient. T-index scored by two 0.5B LMs fine-tuned on only 1-5k pairs of synthetic data can well capture translationese in the wild. We find that the relative differences in T-indices between translations can well predict pairwise translationese annotations obtained from human annotators; and the absolute values of T-indices correlate well with human ratings of degrees of translationese (Pearson's $r = 0.568$). Additionally, the correlation between T-index and existing machine translation (MT) quality estimation (QE) metrics such as BLEU and COMET is low, suggesting that T-index is not covered by these metrics and can serve as a complementary metric in MT QE.
Perception-Aware Policy Optimization for Multimodal Reasoning
Jul 08, 2025
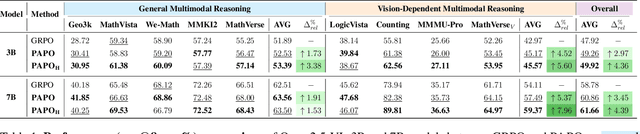
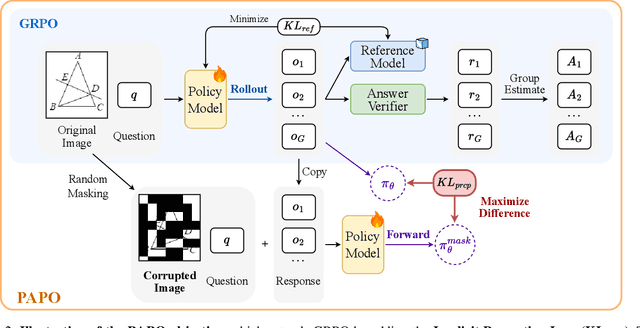
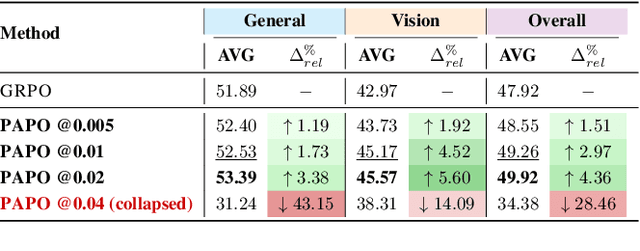
Reinforcement Learning with Verifiable Rewards (RLVR) has proven to be a highly effective strategy for endowing Large Language Models (LLMs) with robust multi-step reasoning abilities. However, its design and optimizations remain tailored to purely textual domains, resulting in suboptimal performance when applied to multimodal reasoning tasks. In particular, we observe that a major source of error in current multimodal reasoning lies in the perception of visual inputs. To address this bottleneck, we propose Perception-Aware Policy Optimization (PAPO), a simple yet effective extension of GRPO that encourages the model to learn to perceive while learning to reason, entirely from internal supervision signals. Notably, PAPO does not rely on additional data curation, external reward models, or proprietary models. Specifically, we introduce the Implicit Perception Loss in the form of a KL divergence term to the GRPO objective, which, despite its simplicity, yields significant overall improvements (4.4%) on diverse multimodal benchmarks. The improvements are more pronounced, approaching 8.0%, on tasks with high vision dependency. We also observe a substantial reduction (30.5%) in perception errors, indicating improved perceptual capabilities with PAPO. We conduct comprehensive analysis of PAPO and identify a unique loss hacking issue, which we rigorously analyze and mitigate through a Double Entropy Loss. Overall, our work introduces a deeper integration of perception-aware supervision into RLVR learning objectives and lays the groundwork for a new RL framework that encourages visually grounded reasoning. Project page: https://mikewangwzhl.github.io/PAPO.
WebSailor: Navigating Super-human Reasoning for Web Agent
Jul 03, 2025



Transcending human cognitive limitations represents a critical frontier in LLM training. Proprietary agentic systems like DeepResearch have demonstrated superhuman capabilities on extremely complex information-seeking benchmarks such as BrowseComp, a feat previously unattainable. We posit that their success hinges on a sophisticated reasoning pattern absent in open-source models: the ability to systematically reduce extreme uncertainty when navigating vast information landscapes. Based on this insight, we introduce WebSailor, a complete post-training methodology designed to instill this crucial capability. Our approach involves generating novel, high-uncertainty tasks through structured sampling and information obfuscation, RFT cold start, and an efficient agentic RL training algorithm, Duplicating Sampling Policy Optimization (DUPO). With this integrated pipeline, WebSailor significantly outperforms all opensource agents in complex information-seeking tasks, matching proprietary agents' performance and closing the capability gap.