 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslationese-index: Using Likelihood Ratios for Graded and Generalizable Measurement of Translationese
Jul 16, 2025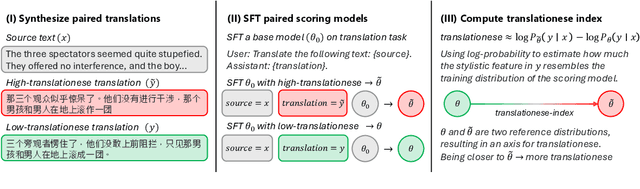
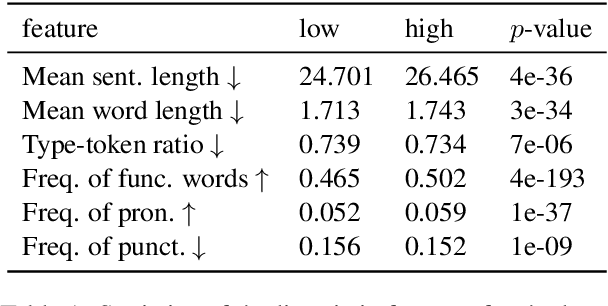
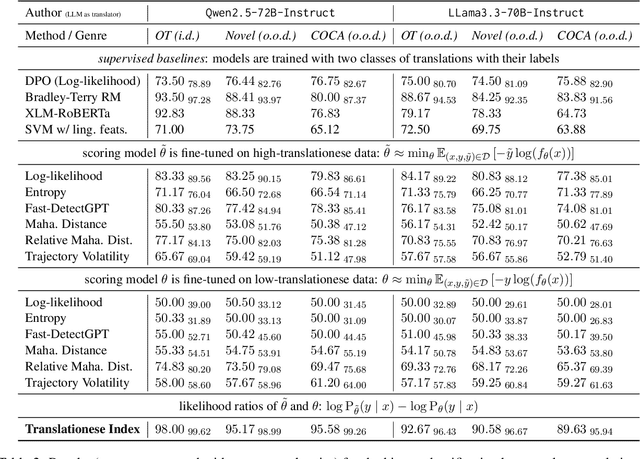
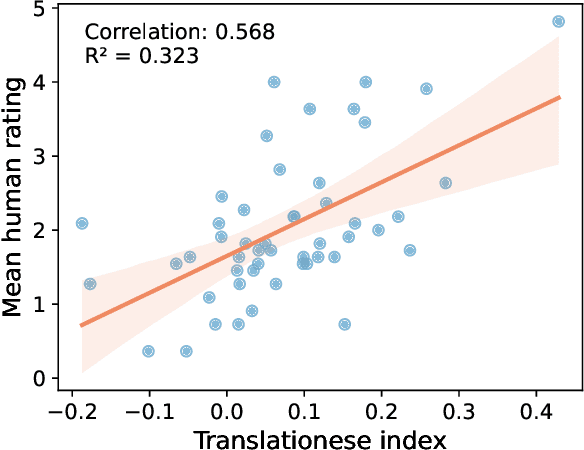
In this paper, we propose the first quantitative measure for translationese -- the translationese-index (T-index) for graded and generalizable measurement of translationese, computed from the likelihood ratios of two contrastively fine-tuned language models (LMs). We use a synthesized dataset and a dataset with translations in the wild to evaluate T-index's generalizability in cross-domain settings and its validity against human judgments. Our results show that T-index is both robust and efficient. T-index scored by two 0.5B LMs fine-tuned on only 1-5k pairs of synthetic data can well capture translationese in the wild. We find that the relative differences in T-indices between translations can well predict pairwise translationese annotations obtained from human annotators; and the absolute values of T-indices correlate well with human ratings of degrees of translationese (Pearson's $r = 0.568$). Additionally, the correlation between T-index and existing machine translation (MT) quality estimation (QE) metrics such as BLEU and COMET is low, suggesting that T-index is not covered by these metrics and can serve as a complementary metric in MT QE.
Train Once for All: A Transitional Approach for Efficient Aspect Sentiment Triplet Extraction
Nov 29, 2024Aspect-Opinion Pair Extraction (AOPE) and Aspect Sentiment Triplet Extraction (ASTE) have gained significant attention in natural language processing. However, most existing methods are a pipelined framework, which extracts aspects/opinions and identifies their relations separately, leading to a drawback of error propagation and high time complexity. Towards this problem, we propose a transition-based pipeline to mitigate token-level bias and capture position-aware aspect-opinion relations. With the use of a fused dataset and contrastive learning optimization, our model learns robust action patterns and can optimize separate subtasks jointly, often with linear-time complexity. The results show that our model achieves the best performance on both the ASTE and AOPE tasks, outperforming the state-of-the-art methods by at least 6.98\% in the F1 measure. The code is available at https://github.com/Paparare/trans_aste.
ZhoBLiMP: a Systematic Assessment of Language Models with Linguistic Minimal Pairs in Chinese
Nov 09, 2024



Whether and how language models (LMs) acquire the syntax of natural languages has been widely evaluated under the minimal pair paradigm. However, a lack of wide-coverage benchmarks in languages other than English has constrained systematic investigations into the issue. Addressing it, we first introduce ZhoBLiMP, the most comprehensive benchmark of linguistic minimal pairs for Chinese to date, with 118 paradigms, covering 15 linguistic phenomena. We then train 20 LMs of different sizes (14M to 1.4B) on Chinese corpora of various volumes (100M to 3B tokens) and evaluate them along with 14 off-the-shelf LLMs on ZhoBLiMP. The overall results indicate that Chinese grammar can be mostly learned by models with around 500M parameters, trained on 1B tokens with one epoch, showing limited benefits for further scaling. Most (N=95) linguistic paradigms are of easy or medium difficulty for LMs, while there are still 13 paradigms that remain challenging even for models with up to 32B parameters. In regard to how LMs acquire Chinese grammar, we observe a U-shaped learning pattern in several phenomena, similar to those observed in child language acquisition.
Do Large Language Models Understand Conversational Implicature -- A case study with a chinese sitcom
Apr 30, 2024Understanding the non-literal meaning of an utterance is critical for large language models (LLMs) to become human-like social communicators. In this work, we introduce SwordsmanImp, the first Chinese multi-turn-dialogue-based dataset aimed at conversational implicature, sourced from dialogues in the Chinese sitcom $\textit{My Own Swordsman}$. It includes 200 carefully handcrafted questions, all annotated on which Gricean maxims have been violated. We test eight close-source and open-source LLMs under two tasks: a multiple-choice question task and an implicature explanation task. Our results show that GPT-4 attains human-level accuracy (94%) on multiple-choice questions. CausalLM demonstrates a 78.5% accuracy following GPT-4. Other models, including GPT-3.5 and several open-source models, demonstrate a lower accuracy ranging from 20% to 60% on multiple-choice questions. Human raters were asked to rate the explanation of the implicatures generated by LLMs on their reasonability, logic and fluency. While all models generate largely fluent and self-consistent text, their explanations score low on reasonability except for GPT-4, suggesting that most LLMs cannot produce satisfactory explanations of the implicatures in the conversation. Moreover, we find LLMs' performance does not vary significantly by Gricean maxims, suggesting that LLMs do not seem to process implicatures derived from different maxims differently. Our data and code are available at https://github.com/sjtu-compling/llm-pragmatics.
SH2: Self-Highlighted Hesitation Helps You Decode More Truthfully
Jan 11, 2024



Large language models (LLMs) demonstrate great performance in text generation. However, LLMs are still suffering from hallucinations. In this work, we propose an inference-time method, Self-Highlighted Hesitation (SH2), to help LLMs decode more truthfully. SH2 is based on a simple fact rooted in information theory that for an LLM, the tokens predicted with lower probabilities are prone to be more informative than others. Our analysis shows that the tokens assigned with lower probabilities by an LLM are more likely to be closely related to factual information, such as nouns, proper nouns, and adjectives. Therefore, we propose to ''highlight'' the factual information by selecting the tokens with the lowest probabilities and concatenating them to the original context, thus forcing the model to repeatedly read and hesitate on these tokens before generation. During decoding, we also adopt contrastive decoding to emphasize the difference in the output probabilities brought by the hesitation. Experimental results demonstrate that our SH2, requiring no additional data or models, can effectively help LLMs elicit factual knowledge and distinguish hallucinated contexts. Significant and consistent improvements are achieved by SH2 for LLaMA-7b and LLaMA2-7b on multiple hallucination tasks.
MELA: Multilingual Evaluation of Linguistic Acceptability
Nov 15, 2023



Recent benchmarks for Large Language Models (LLMs) have mostly focused on application-driven tasks such as complex reasoning and code generation, and this has led to a scarcity in purely linguistic evaluation of LLMs. Against this background, we introduce Multilingual Evaluation of Linguistic Acceptability -- MELA, the first multilingual benchmark on linguistic acceptability with 48K samples covering 10 languages from a diverse set of language families. We establish baselines of commonly used LLMs along with supervised models, and conduct cross-lingual transfer and multi-task learning experiments with XLM-R. In pursuit of multilingual interpretability, we analyze the weights of fine-tuned XLM-R to explore the possibility of identifying transfer difficulty between languages. Our results show that ChatGPT benefits much from in-context examples but still lags behind fine-tuned XLM-R, while the performance of GPT-4 is on par with fine-tuned XLM-R even in zero-shot setting. Cross-lingual and multi-task learning experiments show that unlike semantic tasks, in-language training data is crucial in acceptability judgements. Results in layerwise probing indicate that the upper layers of XLM-R become a task-specific but language-agnostic region for multilingual acceptability judgment. We also introduce the concept of conflicting weight, which could be a potential indicator for the difficulty of cross-lingual transfer between languages. Our data will be available at https://github.com/sjtu-compling/MELA.
Revisiting Acceptability Judgements
May 24, 2023



Years have passed since the NLP community has last focused on linguistic acceptability. In this work, we revisit this topic in the context of large language models. We introduce CoLAC - Corpus of Linguistic Acceptability in Chinese, the first large-scale non-English acceptability dataset that is verified by native speakers and comes with two sets of labels. Our experiments show that even the largest InstructGPT model performs only at chance level on CoLAC, while ChatGPT's performance (48.30 MCC) is also way below supervised models (59.03 MCC) and human (65.11 MCC). Through cross-lingual transfer experiments and fine-grained linguistic analysis, we demonstrate for the first time that knowledge of linguistic acceptability can be transferred across typologically distinct languages, as well as be traced back to pre-training.
ArguGPT: evaluating, understanding and identifying argumentative essays generated by GPT models
Apr 16, 2023



AI generated content (AIGC) presents considerable challenge to educators around the world. Instructors need to be able to detect such text generated by large language models, either with the naked eye or with the help of some tools. There is also growing need to understand the lexical, syntactic and stylistic features of AIGC. To address these challenges in English language teaching, we first present ArguGPT, a balanced corpus of 4,038 argumentative essays generated by 7 GPT models in response to essay prompts from three sources: (1) in-class or homework exercises, (2) TOEFL and (3) GRE writing tasks. Machine-generated texts are paired with roughly equal number of human-written essays with three score levels matched in essay prompts. We then hire English instructors to distinguish machine essays from human ones. Results show that when first exposed to machine-generated essays, the instructors only have an accuracy of 61% in detecting them. But the number rises to 67% after one round of minimal self-training. Next, we perform linguistic analyses of these essays, which show that machines produce sentences with more complex syntactic structures while human essays tend to be lexically more complex. Finally, we test existing AIGC detectors and build our own detectors using SVMs and RoBERTa. Results suggest that a RoBERTa fine-tuned with the training set of ArguGPT achieves above 90% accuracy in both essay- and sentence-level classification. To the best of our knowledge, this is the first comprehensive analysis of argumentative essays produced by generative large language models. Machine-authored essays in ArguGPT and our models will be made publicly available at https://github.com/huhailinguist/ArguGPT
FewCLUE: A Chinese Few-shot Learning Evaluation Benchmark
Jul 15, 2021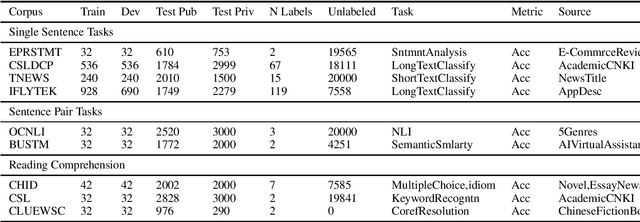
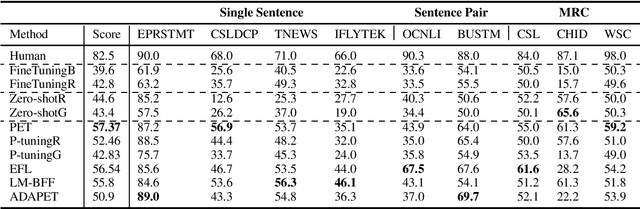

Pretrained Language Models (PLMs) have achieved tremendous success in natural language understanding tasks. While different learning schemes -- fine-tuning, zero-shot and few-shot learning -- have been widely explored and compared for languages such as English, there is comparatively little work in Chinese to fairly and comprehensively evaluate and compare these methods. This work first introduces Chinese Few-shot Learning Evaluation Benchmark (FewCLUE), the first comprehensive small sample evaluation benchmark in Chinese. It includes nine tasks, ranging from single-sentence and sentence-pair classification tasks to machine reading comprehension tasks. Given the high variance of the few-shot learning performance, we provide multiple training/validation sets to facilitate a more accurate and stable evaluation of few-shot modeling. An unlabeled training set with up to 20,000 additional samples per task is provided, allowing researchers to explore better ways of using unlabeled samples. Next, we implement a set of state-of-the-art (SOTA) few-shot learning methods (including PET, ADAPET, LM-BFF, P-tuning and EFL), and compare their performance with fine-tuning and zero-shot learning schemes on the newly constructed FewCLUE benchmark.Our results show that: 1) all five few-shot learning methods exhibit better performance than fine-tuning or zero-shot learning; 2) among the five methods, PET is the best performing few-shot method; 3) few-shot learning performance is highly dependent on the specific task. Our benchmark and code are available at https://github.com/CLUEbenchmark/FewCLUE
Investigating Transfer Learning in Multilingual Pre-trained Language Models through Chinese Natural Language Inference
Jun 07, 2021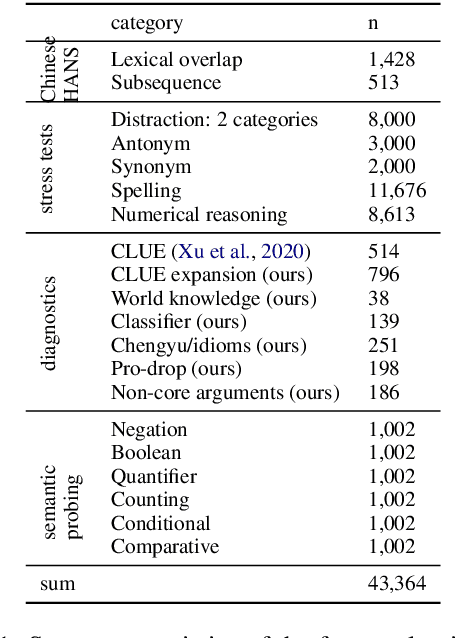


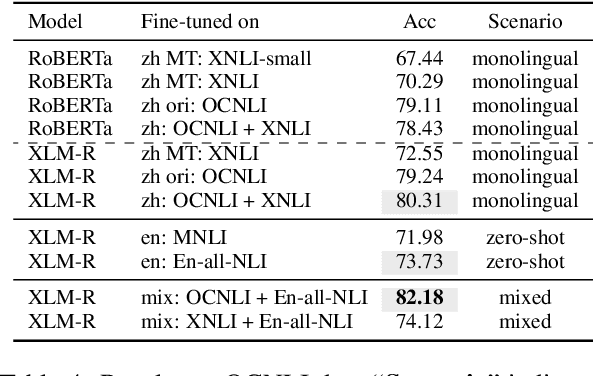
Multilingual transformers (XLM, mT5) have been shown to have remarkable transfer skills in zero-shot settings. Most transfer studies, however, rely on automatically translated resources (XNLI, XQuAD), making it hard to discern the particular linguistic knowledge that is being transferred, and the role of expert annotated monolingual datasets when developing task-specific models. We investigate the cross-lingual transfer abilities of XLM-R for Chinese and English natural language inference (NLI), with a focus on the recent large-scale Chinese dataset OCNLI. To better understand linguistic transfer, we created 4 categories of challenge and adversarial tasks (totaling 17 new datasets) for Chinese that build on several well-known resources for English (e.g., HANS, NLI stress-tests). We find that cross-lingual models trained on English NLI do transfer well across our Chinese tasks (e.g., in 3/4 of our challenge categories, they perform as well/better than the best monolingual models, even on 3/5 uniquely Chinese linguistic phenomena such as idioms, pro drop). These results, however, come with important caveats: cross-lingual models often perform best when trained on a mixture of English and high-quality monolingual NLI data (OCNLI), and are often hindered by automatically translated resources (XNLI-zh). For many phenomena, all models continue to struggle, highlighting the need for our new diagnostics to help benchmark Chinese and cross-lingual models. All new datasets/code are released at https://github.com/huhailinguist/ChineseNLIProbing.