 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslationese-index: Using Likelihood Ratios for Graded and Generalizable Measurement of Translationese
Paper and Code
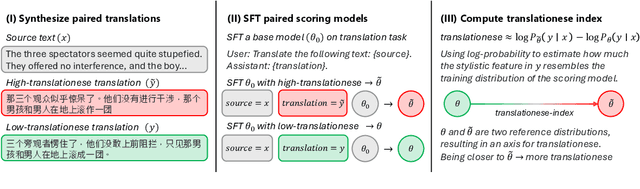
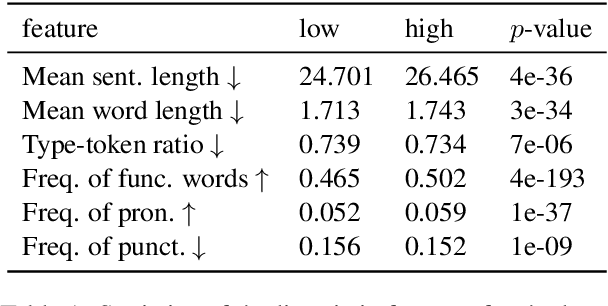
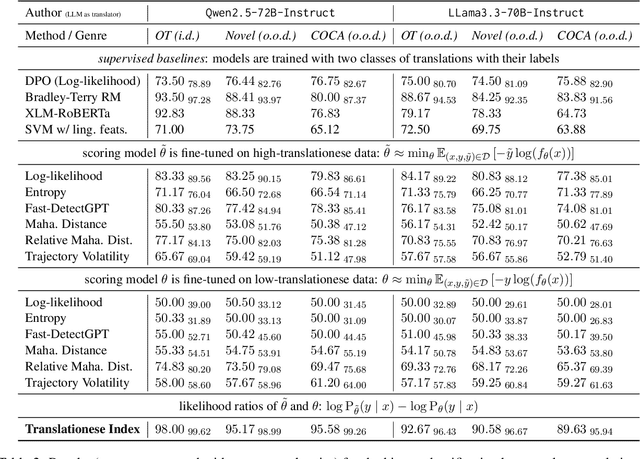
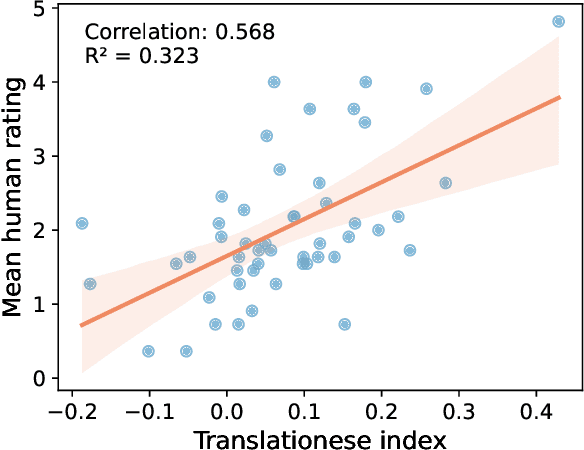
In this paper, we propose the first quantitative measure for translationese -- the translationese-index (T-index) for graded and generalizable measurement of translationese, computed from the likelihood ratios of two contrastively fine-tuned language models (LMs). We use a synthesized dataset and a dataset with translations in the wild to evaluate T-index's generalizability in cross-domain settings and its validity against human judgments. Our results show that T-index is both robust and efficient. T-index scored by two 0.5B LMs fine-tuned on only 1-5k pairs of synthetic data can well capture translationese in the wild. We find that the relative differences in T-indices between translations can well predict pairwise translationese annotations obtained from human annotators; and the absolute values of T-indices correlate well with human ratings of degrees of translationese (Pearson's $r = 0.568$). Additionally, the correlation between T-index and existing machine translation (MT) quality estimation (QE) metrics such as BLEU and COMET is low, suggesting that T-index is not covered by these metrics and can serve as a complementary metric in MT QE.