 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTAMP: Training Explicit Memory for Mobile GUI Agents in Controllable and Scalable Virtual Environments
May 28, 2026Mobile GUI agents excel at immediate reactive control but frequently fail in realistic, long-horizon tasks that require memory. This failure stems from a fundamental conflict between limited context windows and token-heavy screenshots. To save the limited context, agents must progressively discard older visual history, permanently losing crucial transient information. Furthermore, existing action-centric datasets fail to teach agents what or when to explicitly memorize, and augmenting static real-world data is prohibitively expensive and lacks interactive verification. To resolve this, we present STAMP, a framework that trains explicit memory in mobile agents through controllable virtual environments, where deterministic memory variables are programmatically injected into synthesized tasks to control what must be memorized, when it should be encoded, and when it must later be retrieved, thereby producing verifiable supervised data at scale and enabling online reinforcement learning through environment-driven reward feedback. Evaluated on our newly introduced Memory-World benchmark, the resulting Stamp-GUI agent achieves state-of-the-art performance among GUI-specialized models and sets a new high watermark on our Memory-World benchmark, demonstrating exceptional memory accuracy and task resilience while maintaining strong general mobile navigation capabilities.
Mobile-Agent-v3: Foundamental Agents for GUI Automation
Aug 21, 2025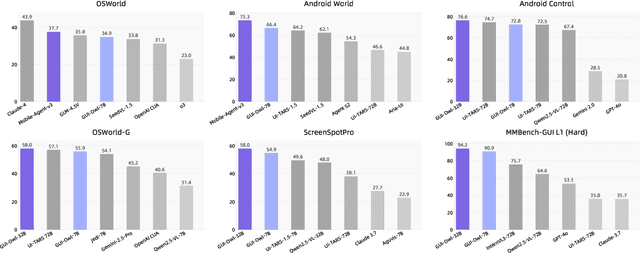
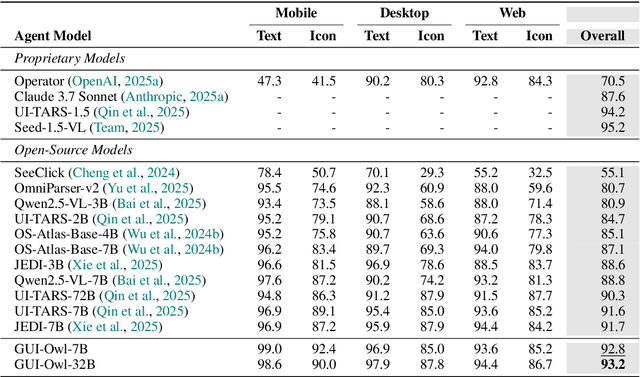
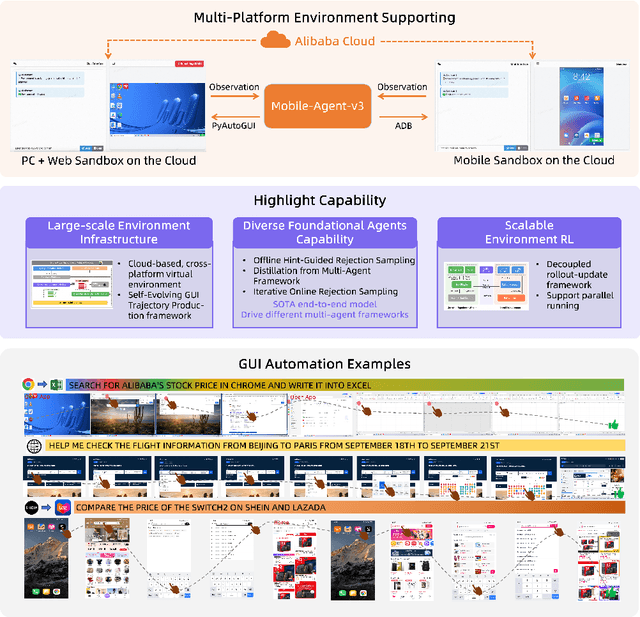
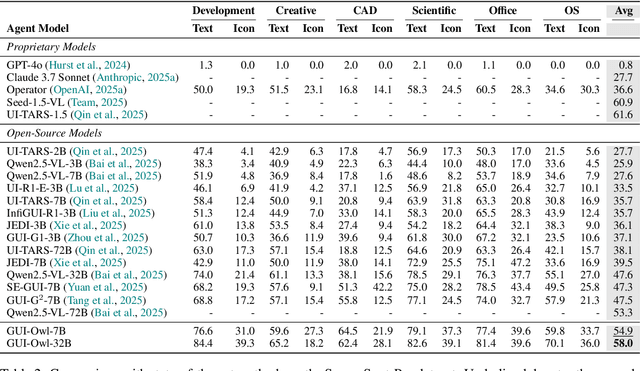
This paper introduces GUI-Owl, a foundational GUI agent model that achieves state-of-the-art performance among open-source end-to-end models on ten GUI benchmarks across desktop and mobile environments, covering grounding, question answering, planning, decision-making, and procedural knowledge. GUI-Owl-7B achieves 66.4 on AndroidWorld and 29.4 on OSWorld. Building on this, we propose Mobile-Agent-v3, a general-purpose GUI agent framework that further improves performance to 73.3 on AndroidWorld and 37.7 on OSWorld, setting a new state-of-the-art for open-source GUI agent frameworks. GUI-Owl incorporates three key innovations: (1) Large-scale Environment Infrastructure: a cloud-based virtual environment spanning Android, Ubuntu, macOS, and Windows, enabling our Self-Evolving GUI Trajectory Production framework. This generates high-quality interaction data via automated query generation and correctness validation, leveraging GUI-Owl to refine trajectories iteratively, forming a self-improving loop. It supports diverse data pipelines and reduces manual annotation. (2) Diverse Foundational Agent Capabilities: by integrating UI grounding, planning, action semantics, and reasoning patterns, GUI-Owl supports end-to-end decision-making and can act as a modular component in multi-agent systems. (3) Scalable Environment RL: we develop a scalable reinforcement learning framework with fully asynchronous training for real-world alignment. We also introduce Trajectory-aware Relative Policy Optimization (TRPO) for online RL, achieving 34.9 on OSWorld. GUI-Owl and Mobile-Agent-v3 are open-sourced at https://github.com/X-PLUG/MobileAgent.
Is Cognition consistent with Perception? Assessing and Mitigating Multimodal Knowledge Conflicts in Document Understanding
Nov 12, 2024



Multimodal large language models (MLLMs) have shown impressive capabilities in document understanding, a rapidly growing research area with significant industrial demand in recent years. As a multimodal task, document understanding requires models to possess both perceptual and cognitive abilities. However, current MLLMs often face conflicts between perception and cognition. Taking a document VQA task (cognition) as an example, an MLLM might generate answers that do not match the corresponding visual content identified by its OCR (perception). This conflict suggests that the MLLM might struggle to establish an intrinsic connection between the information it "sees" and what it "understands." Such conflicts challenge the intuitive notion that cognition is consistent with perception, hindering the performance and explainability of MLLMs. In this paper, we define the conflicts between cognition and perception as Cognition and Perception (C&P) knowledge conflicts, a form of multimodal knowledge conflicts, and systematically assess them with a focus on document understanding. Our analysis reveals that even GPT-4o, a leading MLLM, achieves only 68.6% C&P consistency. To mitigate the C&P knowledge conflicts, we propose a novel method called Multimodal Knowledge Consistency Fine-tuning. This method first ensures task-specific consistency and then connects the cognitive and perceptual knowledge. Our method significantly reduces C&P knowledge conflicts across all tested MLLMs and enhances their performance in both cognitive and perceptual tasks in most scenarios.
ProcTag: Process Tagging for Assessing the Efficacy of Document Instruction Data
Jul 17, 2024



Recently, large language models (LLMs) and multimodal large language models (MLLMs) have demonstrated promising results on document visual question answering (VQA) task, particularly after training on document instruction datasets. An effective evaluation method for document instruction data is crucial in constructing instruction data with high efficacy, which, in turn, facilitates the training of LLMs and MLLMs for document VQA. However, most existing evaluation methods for instruction data are limited to the textual content of the instructions themselves, thereby hindering the effective assessment of document instruction datasets and constraining their construction. In this paper, we propose ProcTag, a data-oriented method that assesses the efficacy of document instruction data. ProcTag innovatively performs tagging on the execution process of instructions rather than the instruction text itself. By leveraging the diversity and complexity of these tags to assess the efficacy of the given dataset, ProcTag enables selective sampling or filtering of document instructions. Furthermore, DocLayPrompt, a novel semi-structured layout-aware document prompting strategy, is proposed for effectively representing documents. Experiments demonstrate that sampling existing open-sourced and generated document VQA/instruction datasets with ProcTag significantly outperforms current methods for evaluating instruction data. Impressively, with ProcTag-based sampling in the generated document datasets, only 30.5\% of the document instructions are required to achieve 100\% efficacy compared to the complete dataset. The code is publicly available at https://github.com/AlibabaResearch/AdvancedLiterateMachinery/tree/main/DocumentUnderstanding/ProcTag.
LayoutLLM: Layout Instruction Tuning with Large Language Models for Document Understanding
Apr 08, 2024Recently, leveraging large language models (LLMs) or multimodal large language models (MLLMs) for document understanding has been proven very promising. However, previous works that employ LLMs/MLLMs for document understanding have not fully explored and utilized the document layout information, which is vital for precise document understanding. In this paper, we propose LayoutLLM, an LLM/MLLM based method for document understanding. The core of LayoutLLM is a layout instruction tuning strategy, which is specially designed to enhance the comprehension and utilization of document layouts. The proposed layout instruction tuning strategy consists of two components: Layout-aware Pre-training and Layout-aware Supervised Fine-tuning. To capture the characteristics of document layout in Layout-aware Pre-training, three groups of pre-training tasks, corresponding to document-level, region-level and segment-level information, are introduced. Furthermore, a novel module called layout chain-of-thought (LayoutCoT) is devised to enable LayoutLLM to focus on regions relevant to the question and generate accurate answers. LayoutCoT is effective for boosting the performance of document understanding. Meanwhile, it brings a certain degree of interpretability, which could facilitate manual inspection and correction. Experiments on standard benchmarks show that the proposed LayoutLLM significantly outperforms existing methods that adopt open-source 7B LLMs/MLLMs for document understanding. The training data of the LayoutLLM is publicly available at https://github.com/AlibabaResearch/AdvancedLiterateMachinery/tree/main/DocumentUnderstanding/LayoutLLM
CLIPER: A Unified Vision-Language Framework for In-the-Wild Facial Expression Recognition
Mar 01, 2023Facial expression recognition (FER) is an essential task for understanding human behaviors. As one of the most informative behaviors of humans, facial expressions are often compound and variable, which is manifested by the fact that different people may express the same expression in very different ways. However, most FER methods still use one-hot or soft labels as the supervision, which lack sufficient semantic descriptions of facial expressions and are less interpretable. Recently, contrastive vision-language pre-training (VLP) models (e.g., CLIP) use text as supervision and have injected new vitality into various computer vision tasks, benefiting from the rich semantics in text. Therefore, in this work, we propose CLIPER, a unified framework for both static and dynamic facial Expression Recognition based on CLIP. Besides, we introduce multiple expression text descriptors (METD) to learn fine-grained expression representations that make CLIPER more interpretable. We conduct extensive experiments on several popular FER benchmarks and achieve state-of-the-art performance, which demonstrates the effectiveness of CLIPER.
Intensity-Aware Loss for Dynamic Facial Expression Recognition in the Wild
Aug 19, 2022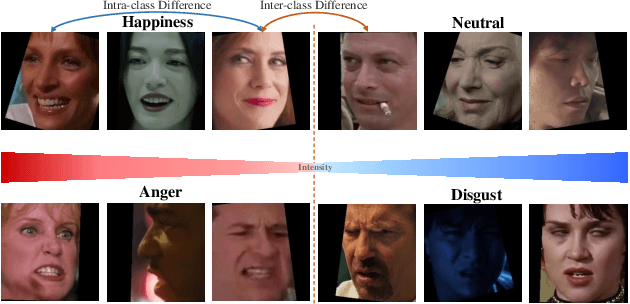
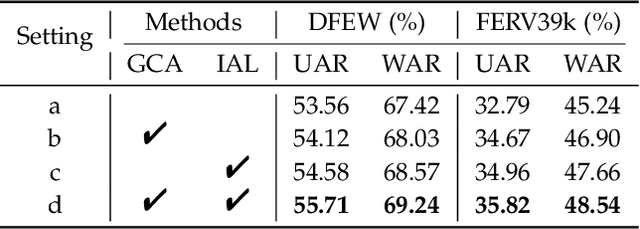
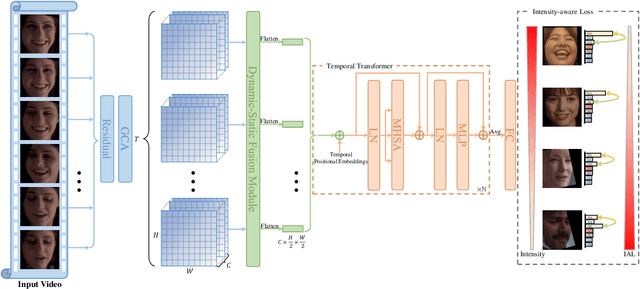
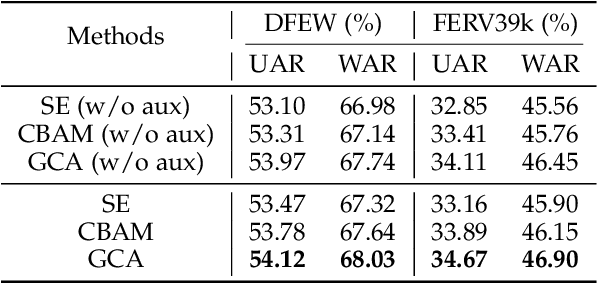
Compared with the image-based static facial expression recognition (SFER) task, the dynamic facial expression recognition (DFER) task based on video sequences is closer to the natural expression recognition scene. However, DFER is often more challenging. One of the main reasons is that video sequences often contain frames with different expression intensities, especially for the facial expressions in the real-world scenarios, while the images in SFER frequently present uniform and high expression intensities. However, if the expressions with different intensities are treated equally, the features learned by the networks will have large intra-class and small inter-class differences, which is harmful to DFER. To tackle this problem, we propose the global convolution-attention block (GCA) to rescale the channels of the feature maps. In addition, we introduce the intensity-aware loss (IAL) in the training process to help the network distinguish the samples with relatively low expression intensities. Experiments on two in-the-wild dynamic facial expression datasets (i.e., DFEW and FERV39k) indicate that our method outperforms the state-of-the-art DFER approaches. The source code will be made publicly available.
NR-DFERNet: Noise-Robust Network for Dynamic Facial Expression Recognition
Jun 10, 2022
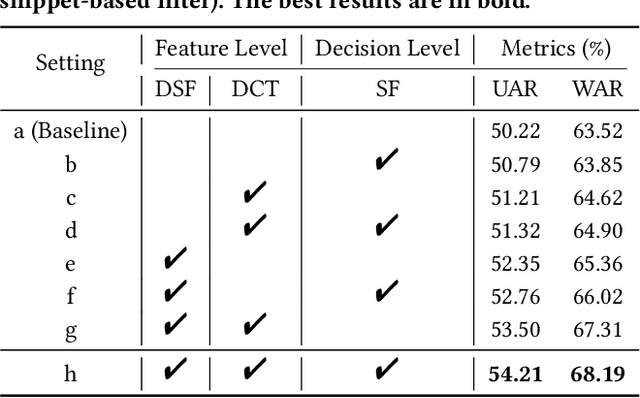
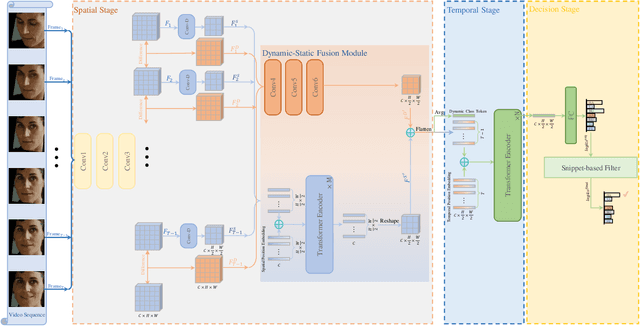
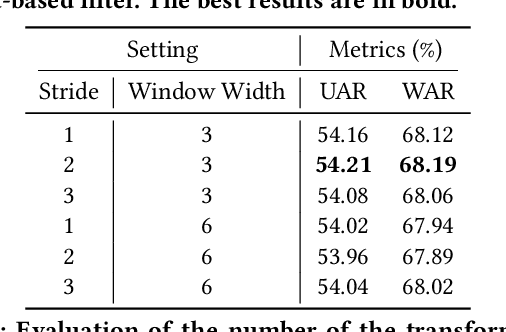
Dynamic facial expression recognition (DFER) in the wild is an extremely challenging task, due to a large number of noisy frames in the video sequences. Previous works focus on extracting more discriminative features, but ignore distinguishing the key frames from the noisy frames. To tackle this problem, we propose a noise-robust dynamic facial expression recognition network (NR-DFERNet), which can effectively reduce the interference of noisy frames on the DFER task. Specifically, at the spatial stage, we devise a dynamic-static fusion module (DSF) that introduces dynamic features to static features for learning more discriminative spatial features. To suppress the impact of target irrelevant frames, we introduce a novel dynamic class token (DCT) for the transformer at the temporal stage. Moreover, we design a snippet-based filter (SF) at the decision stage to reduce the effect of too many neutral frames on non-neutral sequence classification. Extensive experimental results demonstrate that our NR-DFERNet outperforms the state-of-the-art methods on both the DFEW and AFEW benchmarks.
AFNet-M: Adaptive Fusion Network with Masks for 2D+3D Facial Expression Recognition
May 24, 2022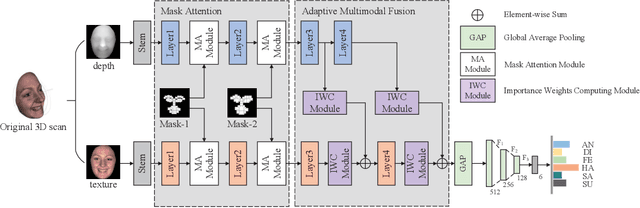
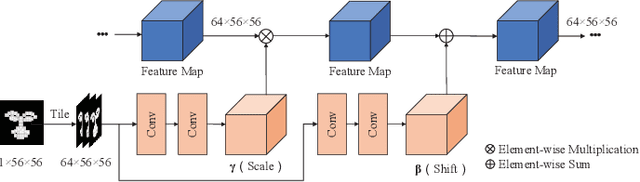
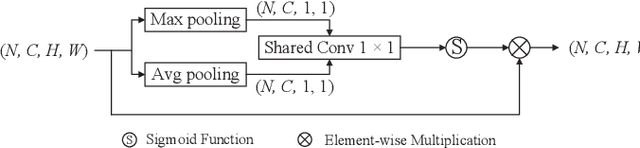
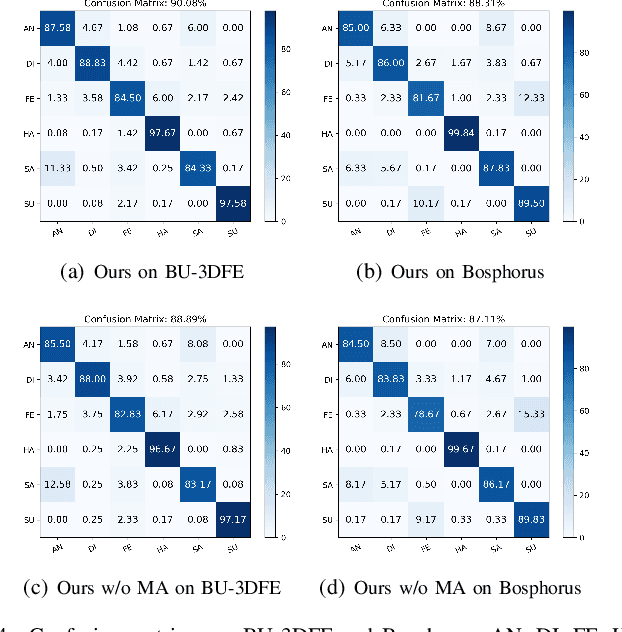
2D+3D facial expression recognition (FER) can effectively cope with illumination changes and pose variations by simultaneously merging 2D texture and more robust 3D depth information. Most deep learning-based approaches employ the simple fusion strategy that concatenates the multimodal features directly after fully-connected layers, without considering the different degrees of significance for each modality. Meanwhile, how to focus on both 2D and 3D local features in salient regions is still a great challenge. In this letter, we propose the adaptive fusion network with masks (AFNet-M) for 2D+3D FER. To enhance 2D and 3D local features, we take the masks annotating salient regions of the face as prior knowledge and design the mask attention module (MA) which can automatically learn two modulation vectors to adjust the feature maps. Moreover, we introduce a novel fusion strategy that can perform adaptive fusion at convolutional layers through the designed importance weights computing module (IWC). Experimental results demonstrate that our AFNet-M achieves the state-of-the-art performance on BU-3DFE and Bosphorus datasets and requires fewer parameters in comparison with other models.
MMNet: Muscle motion-guided network for micro-expression recognition
Jan 14, 2022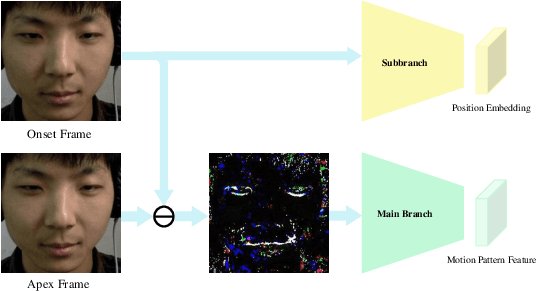
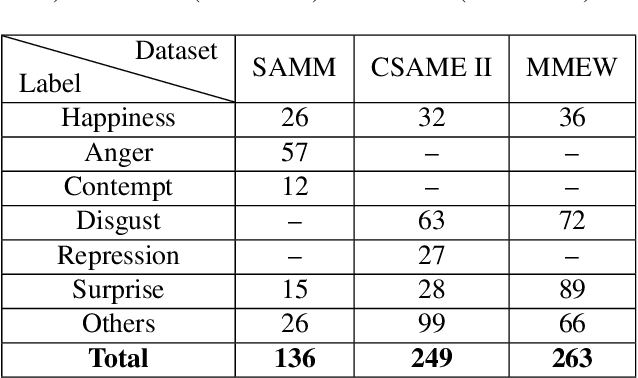
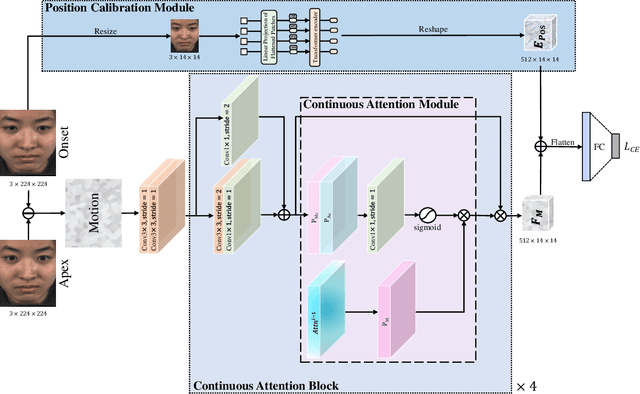
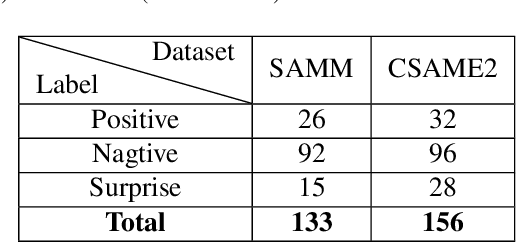
Facial micro-expressions (MEs) are involuntary facial motions revealing peoples real feelings and play an important role in the early intervention of mental illness, the national security, and many human-computer interaction systems. However, existing micro-expression datasets are limited and usually pose some challenges for training good classifiers. To model the subtle facial muscle motions, we propose a robust micro-expression recognition (MER) framework, namely muscle motion-guided network (MMNet). Specifically, a continuous attention (CA) block is introduced to focus on modeling local subtle muscle motion patterns with little identity information, which is different from most previous methods that directly extract features from complete video frames with much identity information. Besides, we design a position calibration (PC) module based on the vision transformer. By adding the position embeddings of the face generated by PC module at the end of the two branches, the PC module can help to add position information to facial muscle motion pattern features for the MER. Extensive experiments on three public micro-expression datasets demonstrate that our approach outperforms state-of-the-art methods by a large margin.