 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQwen-AgentWorld: Language World Models for General Agents
Jun 23, 2026A world model predicts environment dynamics based on current observations and actions, serving as a core cognitive mechanism for reasoning and planning. In this work, we investigate how world modeling based on language models can further push the boundaries of general agents. (i) We first focus on building foundation models for agentic environment simulation. We introduce Qwen-AgentWorld-35B-A3B and Qwen-AgentWorld-397B-A17B, the first language world models capable of simulating agentic environments covering 7 domains via long chain-of-thought reasoning. Leveraging more than 10M environment interaction trajectories of 7 domains in real-world environments, we develop Qwen-AgentWorld through a three-stage training pipeline: CPT injects general-purpose world modeling capabilities from the state transition dynamics and augmented professional corpora, SFT activates next-state-prediction reasoning, and RL sharpens simulation fidelity through a tailored framework with hybrid rubric-and-rule rewards. To evaluate language world models, we present AgentWorldBench, a comprehensive benchmark constructed from real-world interactions of 5 frontier models on 9 established benchmarks. Empirical results demonstrate that Qwen-AgentWorld significantly outperforms existing frontier models. (ii) Beyond foundation models, we further investigate two complementary paradigms through which world modeling enhances general agents. First, as a decoupled environment simulator, Qwen-AgentWorld supports scalable and controllable simulation of thousands of real-world environments for agentic RL, yielding gains that surpass real-environment training alone. Second, as a unified agent foundation model, world-model training acts as a highly effective warm-up that improves downstream performance across 7 agentic benchmarks. Code: https://github.com/QwenLM/Qwen-AgentWorld
STAMP: Training Explicit Memory for Mobile GUI Agents in Controllable and Scalable Virtual Environments
May 28, 2026Mobile GUI agents excel at immediate reactive control but frequently fail in realistic, long-horizon tasks that require memory. This failure stems from a fundamental conflict between limited context windows and token-heavy screenshots. To save the limited context, agents must progressively discard older visual history, permanently losing crucial transient information. Furthermore, existing action-centric datasets fail to teach agents what or when to explicitly memorize, and augmenting static real-world data is prohibitively expensive and lacks interactive verification. To resolve this, we present STAMP, a framework that trains explicit memory in mobile agents through controllable virtual environments, where deterministic memory variables are programmatically injected into synthesized tasks to control what must be memorized, when it should be encoded, and when it must later be retrieved, thereby producing verifiable supervised data at scale and enabling online reinforcement learning through environment-driven reward feedback. Evaluated on our newly introduced Memory-World benchmark, the resulting Stamp-GUI agent achieves state-of-the-art performance among GUI-specialized models and sets a new high watermark on our Memory-World benchmark, demonstrating exceptional memory accuracy and task resilience while maintaining strong general mobile navigation capabilities.
Nice Fold or Hero Call: Learning Budget-Efficient Thinking for Adaptive Reasoning
May 12, 2026Large reasoning models (LRMs) improve problem solving through extended reasoning, but often misallocate test-time compute. Existing efficiency methods reduce cost by compressing reasoning traces or conditioning budget on perceived difficulty, yet largely overlook solvability. As a result, they may spend large budgets on queries beyond the model's capability while compressing hard-but-solvable queries that require deeper reasoning. In this work, we formulate adaptive reasoning as a computational investment under uncertainty, where budget should follow the expected return of reasoning rather than perceived difficulty alone. To instantiate this principle, we propose Budget-Efficient Thinking (BET), a two-stage framework that combines behavioral cold-start with GRPO under an investment-cost-aware reward. By aligning solve-or-fold decisions with rollout-derived solvability, BET learns three behaviors: (1) short solve, answering easy queries concisely; (2) nice fold, abstaining early when continued reasoning has near-zero expected return; and (3) hero call, preserving sufficient compute for hard-but-solvable queries. Across seven benchmarks and three base models, BET reduces reasoning tokens by ~55% on average while achieving overall performance improvements, and transfers zero-shot from mathematical reasoning to scientific QA and logical reasoning with comparable efficiency gains.
IoT-Brain: Grounding LLMs for Semantic-Spatial Sensor Scheduling
Apr 09, 2026Intelligent systems powered by large-scale sensor networks are shifting from predefined monitoring to intent-driven operation, revealing a critical Semantic-to-Physical Mapping Gap. While large language models (LLMs) excel at semantic understanding, existing perception-centric pipelines operate retrospectively, overlooking the fundamental decision of what to sense and when. We formalize this proactive decision as Semantic-Spatial Sensor Scheduling (S3) and demonstrate that direct LLM planning is unreliable due to inherent gaps in representation, reasoning, and optimization. To bridge these gaps, we introduce the Spatial Trajectory Graph (STG), a neuro-symbolic paradigm governed by a verify-before-commit discipline that transforms open-ended planning into a verifiable graph optimization problem. Based on STG, we implement IoT-Brain, a concrete system embodiment, and construct TopoSense-Bench, a campus-scale benchmark with 5,250 natural-language queries across 2,510 cameras. Evaluations show that IoT-Brain boosts task success rate by 37.6% over the strongest search-intensive methods while running nearly 2 times faster and using 6.6 times fewer prompt tokens. In real-world deployment, it approaches the reliability upper bound while reducing 4.1 times network bandwidth, providing a foundational framework for LLMs to interact with the physical world with unprecedented reliability and efficiency.
Mobile-Agent-v3.5: Multi-platform Fundamental GUI Agents
Feb 15, 2026The paper introduces GUI-Owl-1.5, the latest native GUI agent model that features instruct/thinking variants in multiple sizes (2B/4B/8B/32B/235B) and supports a range of platforms (desktop, mobile, browser, and more) to enable cloud-edge collaboration and real-time interaction. GUI-Owl-1.5 achieves state-of-the-art results on more than 20+ GUI benchmarks on open-source models: (1) on GUI automation tasks, it obtains 56.5 on OSWorld, 71.6 on AndroidWorld, and 48.4 on WebArena; (2) on grounding tasks, it obtains 80.3 on ScreenSpotPro; (3) on tool-calling tasks, it obtains 47.6 on OSWorld-MCP, and 46.8 on MobileWorld; (4) on memory and knowledge tasks, it obtains 75.5 on GUI-Knowledge Bench. GUI-Owl-1.5 incorporates several key innovations: (1) Hybird Data Flywheel: we construct the data pipeline for UI understanding and trajectory generation based on a combination of simulated environments and cloud-based sandbox environments, in order to improve the efficiency and quality of data collection. (2) Unified Enhancement of Agent Capabilities: we use a unified thought-synthesis pipeline to enhance the model's reasoning capabilities, while placing particular emphasis on improving key agent abilities, including Tool/MCP use, memory and multi-agent adaptation; (3) Multi-platform Environment RL Scaling: We propose a new environment RL algorithm, MRPO, to address the challenges of multi-platform conflicts and the low training efficiency of long-horizon tasks. The GUI-Owl-1.5 models are open-sourced, and an online cloud-sandbox demo is available at https://github.com/X-PLUG/MobileAgent.
Mobile-Agent-v3: Foundamental Agents for GUI Automation
Aug 21, 2025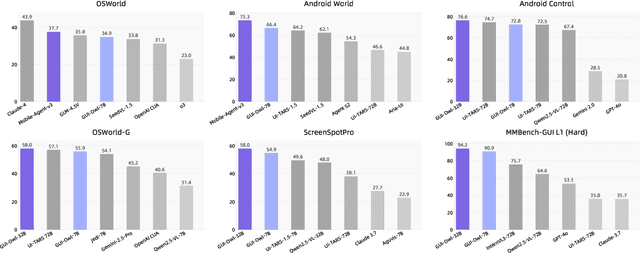
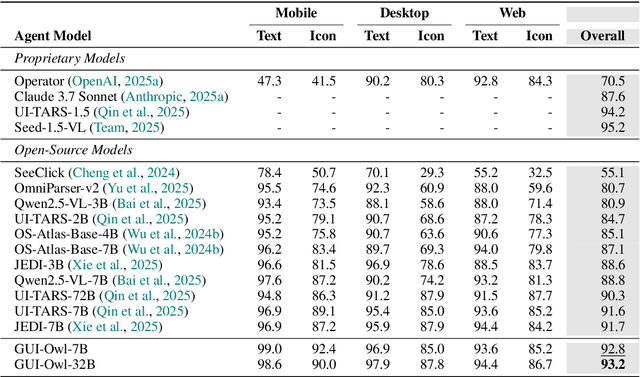
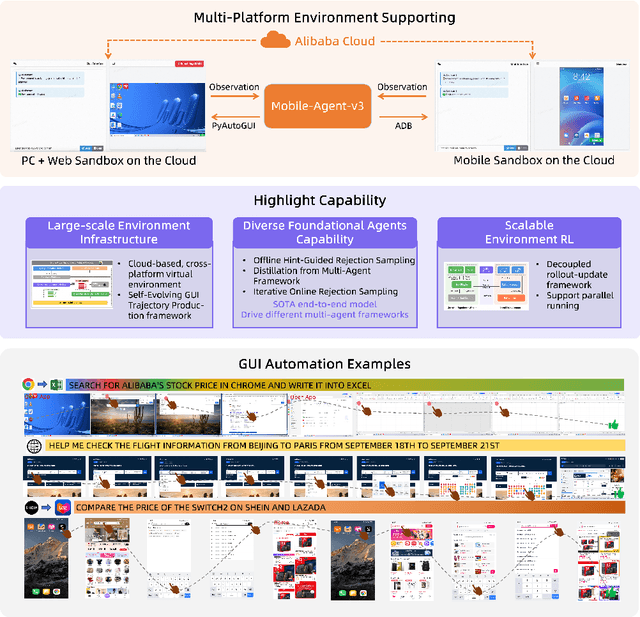
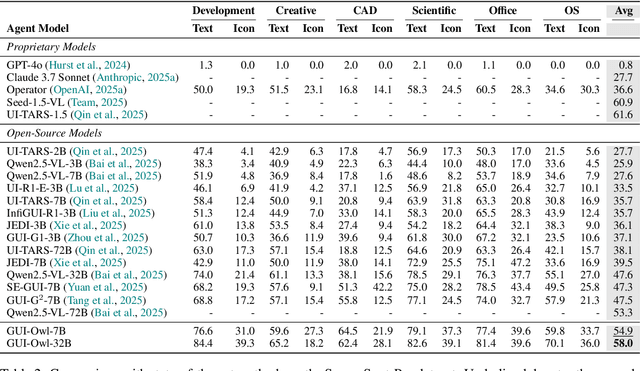
This paper introduces GUI-Owl, a foundational GUI agent model that achieves state-of-the-art performance among open-source end-to-end models on ten GUI benchmarks across desktop and mobile environments, covering grounding, question answering, planning, decision-making, and procedural knowledge. GUI-Owl-7B achieves 66.4 on AndroidWorld and 29.4 on OSWorld. Building on this, we propose Mobile-Agent-v3, a general-purpose GUI agent framework that further improves performance to 73.3 on AndroidWorld and 37.7 on OSWorld, setting a new state-of-the-art for open-source GUI agent frameworks. GUI-Owl incorporates three key innovations: (1) Large-scale Environment Infrastructure: a cloud-based virtual environment spanning Android, Ubuntu, macOS, and Windows, enabling our Self-Evolving GUI Trajectory Production framework. This generates high-quality interaction data via automated query generation and correctness validation, leveraging GUI-Owl to refine trajectories iteratively, forming a self-improving loop. It supports diverse data pipelines and reduces manual annotation. (2) Diverse Foundational Agent Capabilities: by integrating UI grounding, planning, action semantics, and reasoning patterns, GUI-Owl supports end-to-end decision-making and can act as a modular component in multi-agent systems. (3) Scalable Environment RL: we develop a scalable reinforcement learning framework with fully asynchronous training for real-world alignment. We also introduce Trajectory-aware Relative Policy Optimization (TRPO) for online RL, achieving 34.9 on OSWorld. GUI-Owl and Mobile-Agent-v3 are open-sourced at https://github.com/X-PLUG/MobileAgent.
Look Before You Leap: A GUI-Critic-R1 Model for Pre-Operative Error Diagnosis in GUI Automation
Jun 05, 2025In recent years, Multimodal Large Language Models (MLLMs) have been extensively utilized for multimodal reasoning tasks, including Graphical User Interface (GUI) automation. Unlike general offline multimodal tasks, GUI automation is executed in online interactive environments, necessitating step-by-step decision-making based on real-time status of the environment. This task has a lower tolerance for decision-making errors at each step, as any mistakes may cumulatively disrupt the process and potentially lead to irreversible outcomes like deletions or payments. To address these issues, we introduce a pre-operative critic mechanism that provides effective feedback prior to the actual execution, by reasoning about the potential outcome and correctness of actions. Specifically, we propose a Suggestion-aware Gradient Relative Policy Optimization (S-GRPO) strategy to construct our pre-operative critic model GUI-Critic-R1, incorporating a novel suggestion reward to enhance the reliability of the model's feedback. Furthermore, we develop a reasoning-bootstrapping based data collection pipeline to create a GUI-Critic-Train and a GUI-Critic-Test, filling existing gaps in GUI critic data. Static experiments on the GUI-Critic-Test across both mobile and web domains reveal that our GUI-Critic-R1 offers significant advantages in critic accuracy compared to current MLLMs. Dynamic evaluation on GUI automation benchmark further highlights the effectiveness and superiority of our model, as evidenced by improved success rates and operational efficiency.
Mobile-Agent-V: A Video-Guided Approach for Effortless and Efficient Operational Knowledge Injection in Mobile Automation
May 21, 2025



The exponential rise in mobile device usage necessitates streamlined automation for effective task management, yet many AI frameworks fall short due to inadequate operational expertise. While manually written knowledge can bridge this gap, it is often burdensome and inefficient. We introduce Mobile-Agent-V, an innovative framework that utilizes video as a guiding tool to effortlessly and efficiently inject operational knowledge into mobile automation processes. By deriving knowledge directly from video content, Mobile-Agent-V eliminates manual intervention, significantly reducing the effort and time required for knowledge acquisition. To rigorously evaluate this approach, we propose Mobile-Knowledge, a benchmark tailored to assess the impact of external knowledge on mobile agent performance. Our experimental findings demonstrate that Mobile-Agent-V enhances performance by 36% compared to existing methods, underscoring its effortless and efficient advantages in mobile automation.
Mobile-Agent-V: Learning Mobile Device Operation Through Video-Guided Multi-Agent Collaboration
Feb 25, 2025The rapid increase in mobile device usage necessitates improved automation for seamless task management. However, many AI-driven frameworks struggle due to insufficient operational knowledge. Manually written knowledge helps but is labor-intensive and inefficient. To address these challenges, we introduce Mobile-Agent-V, a framework that leverages video guidance to provide rich and cost-effective operational knowledge for mobile automation. Mobile-Agent-V enhances task execution capabilities by leveraging video inputs without requiring specialized sampling or preprocessing. Mobile-Agent-V integrates a sliding window strategy and incorporates a video agent and deep-reflection agent to ensure that actions align with user instructions. Through this innovative approach, users can record task processes with guidance, enabling the system to autonomously learn and execute tasks efficiently. Experimental results show that Mobile-Agent-V achieves a 30% performance improvement compared to existing frameworks. The code will be open-sourced at https://github.com/X-PLUG/MobileAgent.
PC-Agent: A Hierarchical Multi-Agent Collaboration Framework for Complex Task Automation on PC
Feb 21, 2025In the field of MLLM-based GUI agents, compared to smartphones, the PC scenario not only features a more complex interactive environment, but also involves more intricate intra- and inter-app workflows. To address these issues, we propose a hierarchical agent framework named PC-Agent. Specifically, from the perception perspective, we devise an Active Perception Module (APM) to overcome the inadequate abilities of current MLLMs in perceiving screenshot content. From the decision-making perspective, to handle complex user instructions and interdependent subtasks more effectively, we propose a hierarchical multi-agent collaboration architecture that decomposes decision-making processes into Instruction-Subtask-Action levels. Within this architecture, three agents (i.e., Manager, Progress and Decision) are set up for instruction decomposition, progress tracking and step-by-step decision-making respectively. Additionally, a Reflection agent is adopted to enable timely bottom-up error feedback and adjustment. We also introduce a new benchmark PC-Eval with 25 real-world complex instructions. Empirical results on PC-Eval show that our PC-Agent achieves a 32% absolute improvement of task success rate over previous state-of-the-art methods. The code is available at https://github.com/X-PLUG/MobileAgent/tree/main/PC-Agent.