 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcquisitionSynthesis: Targeted Data Generation using Acquisition Functions
May 13, 2026Data quality remains a critical bottleneck in developing capable, competitive models. Researchers have explored many ways to generate top quality samples. Some works rely on rejection sampling: generating lots of synthetic samples and filtering out low-quality samples. Other works rely on larger or closed-source models to extract model weaknesses, necessary skills, or a curriculum off of which to base data generation. These works have one common limitation: there is no quantitative approach to measure the impact of the generated samples on the downstream learner. Active learning literature provides exactly this, in the form of acquisition functions. Acquisition functions measure the informativeness and/or influence of data, providing interpretable, model-centric signals. Inspired by this, we propose AcquisitionSynthesis: using acquisition functions as reward models to train language models to generate higher-quality synthetic data. We conduct experiments on classic verifiable tasks of math, medical question-answering, and coding. Our experimental results indicate that (1) student models trained with AcquisitionSynthesis data achieve good performance on in-distribution tasks (2-7% gain) and is more robust to catastrophic forgetting, and (2) AcquisitionSynthesis models can generate data for other models and for low-to-high resource training paradigms. By leveraging acquisition rewards, we seek to demonstrate a principled path toward model-aware self-improvement that surpasses static datasets.
SoundWeaver: Semantic Warm-Starting for Text-to-Audio Diffusion Serving
Mar 09, 2026Text-to-audio diffusion models produce high-fidelity audio but require tens of function evaluations (NFEs), incurring multi-second latency and limited throughput. We present SoundWeaver, the first training-free, model-agnostic serving system that accelerates text-to-audio diffusion by warm-starting from semantically similar cached audio. SoundWeaver introduces three components: a Reference Selector that retrieves and temporally aligns cached candidates via semantic and duration-aware gating; a Skip Gater that dynamically determines the percentage of NFEs to skip; and a lightweight Cache Manager that maintains cache utility through quality-aware eviction and refinement. On real-world audio traces, SoundWeaver achieves 1.8--3.0$ \times $ latency reduction with a cache of only ${\sim}$1K entries while preserving or improving perceptual quality.
Perception-Aware Policy Optimization for Multimodal Reasoning
Jul 08, 2025
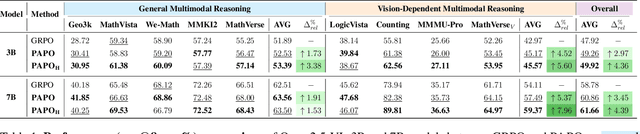
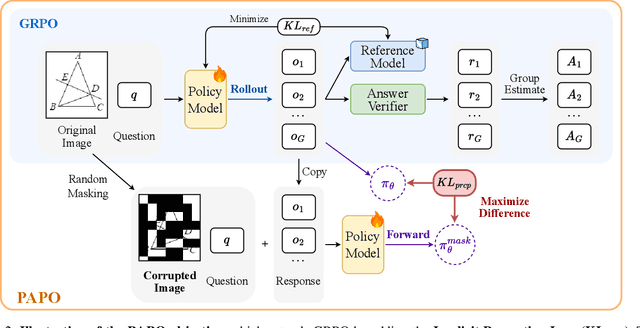
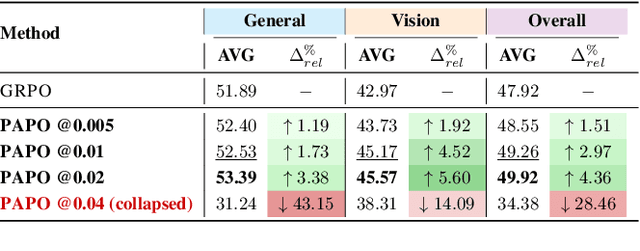
Reinforcement Learning with Verifiable Rewards (RLVR) has proven to be a highly effective strategy for endowing Large Language Models (LLMs) with robust multi-step reasoning abilities. However, its design and optimizations remain tailored to purely textual domains, resulting in suboptimal performance when applied to multimodal reasoning tasks. In particular, we observe that a major source of error in current multimodal reasoning lies in the perception of visual inputs. To address this bottleneck, we propose Perception-Aware Policy Optimization (PAPO), a simple yet effective extension of GRPO that encourages the model to learn to perceive while learning to reason, entirely from internal supervision signals. Notably, PAPO does not rely on additional data curation, external reward models, or proprietary models. Specifically, we introduce the Implicit Perception Loss in the form of a KL divergence term to the GRPO objective, which, despite its simplicity, yields significant overall improvements (4.4%) on diverse multimodal benchmarks. The improvements are more pronounced, approaching 8.0%, on tasks with high vision dependency. We also observe a substantial reduction (30.5%) in perception errors, indicating improved perceptual capabilities with PAPO. We conduct comprehensive analysis of PAPO and identify a unique loss hacking issue, which we rigorously analyze and mitigate through a Double Entropy Loss. Overall, our work introduces a deeper integration of perception-aware supervision into RLVR learning objectives and lays the groundwork for a new RL framework that encourages visually grounded reasoning. Project page: https://mikewangwzhl.github.io/PAPO.