 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCultureForest: Understanding and Evaluating Cultural Norm Grounded Reasoning in LLMs
Jun 01, 2026Existing research largely reduces cultural intelligence in LLMs to a knowledge-level problem, overlooking whether models can effectively utilize their acquired knowledge in realistic scenarios. To bridge this gap, we introduce CultureForest, a benchmark for \textit{Cultural Norm Grounded Reasoning}. Each question is grounded in a small set of atomic norms, enabling verifiable and attributable evaluation. CultureForest comprises 5,378 examples across 8 domains and 53 countries/regions, and supports a progressive evaluation from multiple-choice to open-ended generation. Extensive experiments reveal that even top-tier models degrade substantially in open-ended settings, accompanied by pronounced cross-region disparities. Through targeted analysis, we uncover several consistent patterns: (1) test-time reasoning yields limited gains and may exacerbate inequity; (2) models exhibit highly shared regional preference structures; (3) model responses are markedly conservative, especially under stricter cultural constraints; and (4) by disentangling cultural knowledge acquisition from cultural reasoning, we show that while LLMs possess substantial cultural knowledge, their performance is further bottlenecked by its effective use. These findings point to a necessary shift from knowledge-centric evaluation toward measuring knowledge-grounded reasoning.
Qwen-Scope: Turning Sparse Features into Development Tools for Large Language Models
May 12, 2026Large language models have achieved remarkable capabilities across diverse tasks, yet their internal decision-making processes remain largely opaque, limiting our ability to inspect, control, and systematically improve them. This opacity motivates a growing body of research in mechanistic interpretability, with sparse autoencoders (SAEs) emerging as one of the most promising tools for decomposing model activations into sparse, interpretable feature representations. We introduce Qwen-Scope, an open-source suite of SAEs built on the Qwen model family, comprising 14 groups of SAEs across 7 model variants from the Qwen3 and Qwen3.5 series, covering both dense and mixture-of-expert architectures. Built on top of these SAEs, we show that SAEs can go beyond post-hoc analysis to serve as practical interfaces for model development along four directions: (i) inference-time steering, where SAE feature directions control language, concepts, and preferences without modifying model weights; (ii) evaluation analysis, where activated SAE features provide a representation-level proxy for benchmark redundancy and capability coverage; (iii) data-centric workflows, where SAE features support multilingual toxicity classification and safety-oriented data synthesis; and (iv) post-training optimization, where SAE-derived signals are incorporated into supervised fine-tuning and reinforcement learning objectives to mitigate undesirable behaviors such as code-switching and repetition. Together, these results demonstrate that SAEs can serve not only as post-hoc analysis tools, but also as reusable representation-level interfaces for diagnosing, controlling, evaluating, and improving large language models. By open-sourcing Qwen-Scope, we aim to support mechanistic research and accelerate practical workflows that connect model internals to downstream behavior.
Language as a Latent Variable for Reasoning Optimization
Apr 23, 2026As LLMs reduce English-centric bias, a surprising trend emerges: non-English responses sometimes outperform English on reasoning tasks. We hypothesize that language functions as a latent variable that structurally modulates the model's internal inference pathways, rather than merely serving as an output medium. To test this, we conducted a Polyglot Thinking Experiment, in which models were prompted to solve identical problems under language-constrained and language-unconstrained conditions. Results show that non-English responses often achieve higher accuracy, and the best performance frequently occur when language is unconstrained, suggesting that multilinguality broadens the model's latent reasoning space. Based on this insight, we propose polyGRPO (Polyglot Group Relative Policy Optimization), an RL framework that treats language variation as an implicit exploration signal. It generates polyglot preference data online under language-constrained and unconstrained conditions, optimizing the policy with respect to both answer accuracy and reasoning structure. Trained on only 18.1K multilingual math problems without chain-of-thought annotations, polyGRPO improves the base model (Qwen2.5-7B-Instruct) by 6.72% absolute accuracy on four English reasoning testset and 6.89% in their multilingual benchmark. Remarkably, it is the only method that surpasses the base LLM on English commonsense reasoning task (4.9%), despite being trained solely on math data-highlighting its strong cross-task generalization. Further analysis reveals that treating language as a latent variable expands the model's latent reasoning space, yielding consistent and generalizable improvements in reasoning performance.
Judge Like Human Examiners: A Weighted Importance Multi-Point Evaluation Framework for Generative Tasks with Long-form Answers
Apr 14, 2026Evaluating the quality of model responses remains challenging in generative tasks with long-form answers, as the expected answers usually contain multiple semantically distinct yet complementary factors that should be factorized for fine-grained assessment. Recent evaluation methods resort to relying on either task-level rubrics or question-aware checklists. However, they still 1) struggle to assess whether a response is genuinely grounded in provided contexts; 2) fail to capture the heterogeneous importance of different aspects of reference answers. Inspired by human examiners, we propose a Weighted Importance Multi-Point Evaluation (WIMPE) framework, which factorizes each reference answer into weighted context-bound scoring points. Two complementary metrics, namely Weighted Point-wise Alignment (WPA) and Point-wise Conflict Penalty (PCP), are designed to measure the alignment and contradiction between model responses and reference answers. Extensive experiments on 10 generative tasks demonstrate that WIMPE achieves higher correlations with human annotations.
Towards Cross-lingual Values Assessment: A Consensus-Pluralism Perspective
Feb 19, 2026While large language models (LLMs) have become pivotal to content safety, current evaluation paradigms primarily focus on detecting explicit harms (e.g., violence or hate speech), neglecting the subtler value dimensions conveyed in digital content. To bridge this gap, we introduce X-Value, a novel Cross-lingual Values Assessment Benchmark designed to evaluate LLMs' ability to assess deep-level values of content from a global perspective. X-Value consists of more than 5,000 QA pairs across 18 languages, systematically organized into 7 core domains grounded in Schwartz's Theory of Basic Human Values and categorized into easy and hard levels for discriminative evaluation. We further propose a unique two-stage annotation framework that first identifies whether an issue falls under global consensus (e.g., human rights) or pluralism (e.g., religion), and subsequently conducts a multi-party evaluation of the latent values embedded within the content. Systematic evaluations on X-Value reveal that current SOTA LLMs exhibit deficiencies in cross-lingual values assessment ($Acc < 77\%$), with significant performance disparities across different languages ($ΔAcc > 20\%$). This work highlights the urgent need to improve the nuanced, values-aware content assessment capability of LLMs. Our X-Value is available at: https://huggingface.co/datasets/Whitolf/X-Value.
Qwen3Guard Technical Report
Oct 16, 2025As large language models (LLMs) become more capable and widely used, ensuring the safety of their outputs is increasingly critical. Existing guardrail models, though useful in static evaluation settings, face two major limitations in real-world applications: (1) they typically output only binary "safe/unsafe" labels, which can be interpreted inconsistently across diverse safety policies, rendering them incapable of accommodating varying safety tolerances across domains; and (2) they require complete model outputs before performing safety checks, making them fundamentally incompatible with streaming LLM inference, thereby preventing timely intervention during generation and increasing exposure to harmful partial outputs. To address these challenges, we present Qwen3Guard, a series of multilingual safety guardrail models with two specialized variants: Generative Qwen3Guard, which casts safety classification as an instruction-following task to enable fine-grained tri-class judgments (safe, controversial, unsafe); and Stream Qwen3Guard, which introduces a token-level classification head for real-time safety monitoring during incremental text generation. Both variants are available in three sizes (0.6B, 4B, and 8B parameters) and support up to 119 languages and dialects, providing comprehensive, scalable, and low-latency safety moderation for global LLM deployments. Evaluated across English, Chinese, and multilingual benchmarks, Qwen3Guard achieves state-of-the-art performance in both prompt and response safety classification. All models are released under the Apache 2.0 license for public use.
Direct Simultaneous Translation Activation for Large Audio-Language Models
Sep 19, 2025



Simultaneous speech-to-text translation (Simul-S2TT) aims to translate speech into target text in real time, outputting translations while receiving source speech input, rather than waiting for the entire utterance to be spoken. Simul-S2TT research often modifies model architectures to implement read-write strategies. However, with the rise of large audio-language models (LALMs), a key challenge is how to directly activate Simul-S2TT capabilities in base models without additional architectural changes. In this paper, we introduce {\bf Simul}taneous {\bf S}elf-{\bf A}ugmentation ({\bf SimulSA}), a strategy that utilizes LALMs' inherent capabilities to obtain simultaneous data by randomly truncating speech and constructing partially aligned translation. By incorporating them into offline SFT data, SimulSA effectively bridges the distribution gap between offline translation during pretraining and simultaneous translation during inference. Experimental results demonstrate that augmenting only about {\bf 1\%} of the simultaneous data, compared to the full offline SFT data, can significantly activate LALMs' Simul-S2TT capabilities without modifications to model architecture or decoding strategy.
Tool Graph Retriever: Exploring Dependency Graph-based Tool Retrieval for Large Language Models
Aug 07, 2025With the remarkable advancement of AI agents, the number of their equipped tools is increasing rapidly. However, integrating all tool information into the limited model context becomes impractical, highlighting the need for efficient tool retrieval methods. In this regard, dominant methods primarily rely on semantic similarities between tool descriptions and user queries to retrieve relevant tools. However, they often consider each tool independently, overlooking dependencies between tools, which may lead to the omission of prerequisite tools for successful task execution. To deal with this defect, in this paper, we propose Tool Graph Retriever (TGR), which exploits the dependencies among tools to learn better tool representations for retrieval. First, we construct a dataset termed TDI300K to train a discriminator for identifying tool dependencies. Then, we represent all candidate tools as a tool dependency graph and use graph convolution to integrate the dependencies into their representations. Finally, these updated tool representations are employed for online retrieval. Experimental results on several commonly used datasets show that our TGR can bring a performance improvement to existing dominant methods, achieving SOTA performance. Moreover, in-depth analyses also verify the importance of tool dependencies and the effectiveness of our TGR.
Translationese-index: Using Likelihood Ratios for Graded and Generalizable Measurement of Translationese
Jul 16, 2025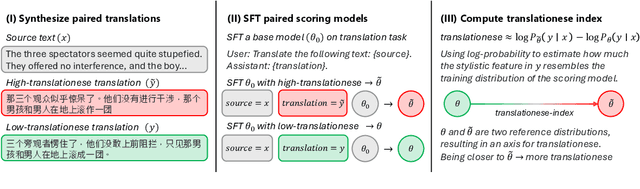
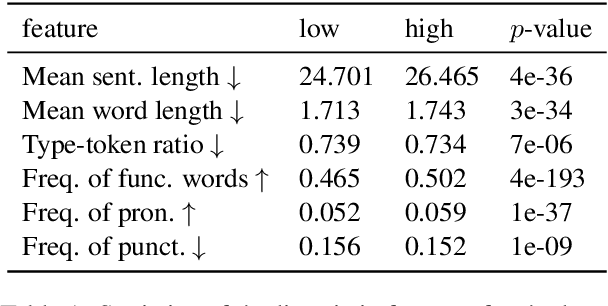
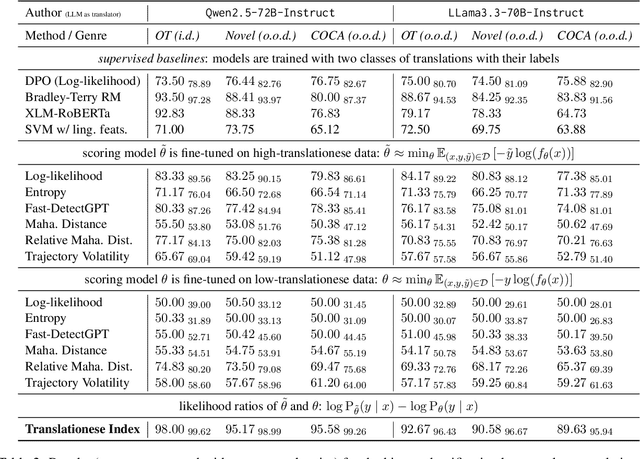
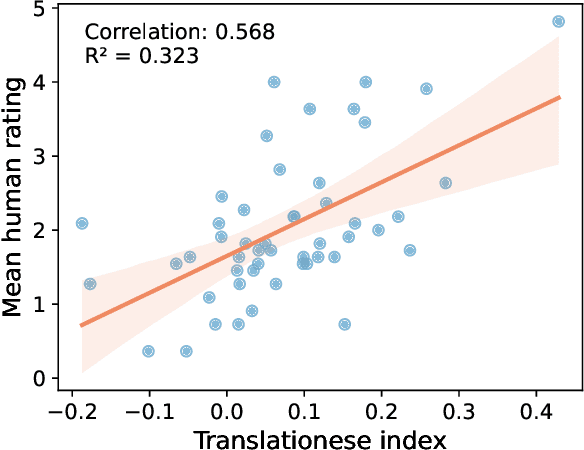
In this paper, we propose the first quantitative measure for translationese -- the translationese-index (T-index) for graded and generalizable measurement of translationese, computed from the likelihood ratios of two contrastively fine-tuned language models (LMs). We use a synthesized dataset and a dataset with translations in the wild to evaluate T-index's generalizability in cross-domain settings and its validity against human judgments. Our results show that T-index is both robust and efficient. T-index scored by two 0.5B LMs fine-tuned on only 1-5k pairs of synthetic data can well capture translationese in the wild. We find that the relative differences in T-indices between translations can well predict pairwise translationese annotations obtained from human annotators; and the absolute values of T-indices correlate well with human ratings of degrees of translationese (Pearson's $r = 0.568$). Additionally, the correlation between T-index and existing machine translation (MT) quality estimation (QE) metrics such as BLEU and COMET is low, suggesting that T-index is not covered by these metrics and can serve as a complementary metric in MT QE.
Qwen3 Technical Report
May 14, 2025



In this work, we present Qwen3, the latest version of the Qwen model family. Qwen3 comprises a series of large language models (LLMs) designed to advance performance, efficiency, and multilingual capabilities. The Qwen3 series includes models of both dense and Mixture-of-Expert (MoE) architectures, with parameter scales ranging from 0.6 to 235 billion. A key innovation in Qwen3 is the integration of thinking mode (for complex, multi-step reasoning) and non-thinking mode (for rapid, context-driven responses) into a unified framework. This eliminates the need to switch between different models--such as chat-optimized models (e.g., GPT-4o) and dedicated reasoning models (e.g., QwQ-32B)--and enables dynamic mode switching based on user queries or chat templates. Meanwhile, Qwen3 introduces a thinking budget mechanism, allowing users to allocate computational resources adaptively during inference, thereby balancing latency and performance based on task complexity. Moreover, by leveraging the knowledge from the flagship models, we significantly reduce the computational resources required to build smaller-scale models, while ensuring their highly competitive performance. Empirical evaluations demonstrate that Qwen3 achieves state-of-the-art results across diverse benchmarks, including tasks in code generation, mathematical reasoning, agent tasks, etc., competitive against larger MoE models and proprietary models. Compared to its predecessor Qwen2.5, Qwen3 expands multilingual support from 29 to 119 languages and dialects, enhancing global accessibility through improved cross-lingual understanding and generation capabilities. To facilitate reproducibility and community-driven research and development, all Qwen3 models are publicly accessible under Apache 2.0.