 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Distillation for Detection Transformer with Consistent Distillation Points Sampling
Nov 16, 2022DETR is a novel end-to-end transformer architecture object detector, which significantly outperforms classic detectors when scaling up the model size. In this paper, we focus on the compression of DETR with knowledge distillation. While knowledge distillation has been well-studied in classic detectors, there is a lack of researches on how to make it work effectively on DETR. We first provide experimental and theoretical analysis to point out that the main challenge in DETR distillation is the lack of consistent distillation points. Distillation points refer to the corresponding inputs of the predictions for student to mimic, and reliable distillation requires sufficient distillation points which are consistent between teacher and student. Based on this observation, we propose a general knowledge distillation paradigm for DETR(KD-DETR) with consistent distillation points sampling. Specifically, we decouple detection and distillation tasks by introducing a set of specialized object queries to construct distillation points. In this paradigm, we further propose a general-to-specific distillation points sampling strategy to explore the extensibility of KD-DETR. Extensive experiments on different DETR architectures with various scales of backbones and transformer layers validate the effectiveness and generalization of KD-DETR. KD-DETR boosts the performance of DAB-DETR with ResNet-18 and ResNet-50 backbone to 41.4$\%$, 45.7$\%$ mAP, respectively, which are 5.2$\%$, 3.5$\%$ higher than the baseline, and ResNet-50 even surpasses the teacher model by $2.2\%$.
Group DETR v2: Strong Object Detector with Encoder-Decoder Pretraining
Nov 07, 2022

We present a strong object detector with encoder-decoder pretraining and finetuning. Our method, called Group DETR v2, is built upon a vision transformer encoder ViT-Huge~\cite{dosovitskiy2020image}, a DETR variant DINO~\cite{zhang2022dino}, and an efficient DETR training method Group DETR~\cite{chen2022group}. The training process consists of self-supervised pretraining and finetuning a ViT-Huge encoder on ImageNet-1K, pretraining the detector on Object365, and finally finetuning it on COCO. Group DETR v2 achieves $\textbf{64.5}$ mAP on COCO test-dev, and establishes a new SoTA on the COCO leaderboard https://paperswithcode.com/sota/object-detection-on-coco
RTFormer: Efficient Design for Real-Time Semantic Segmentation with Transformer
Oct 13, 2022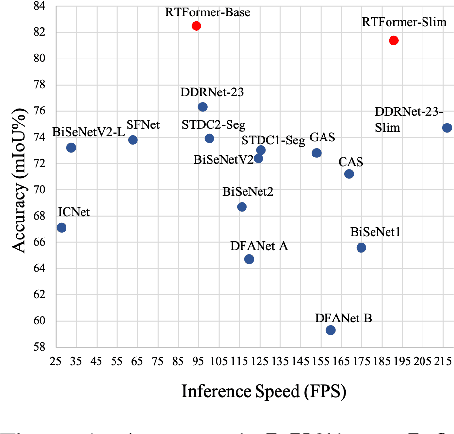

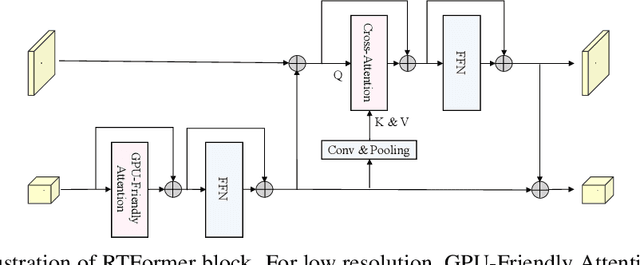
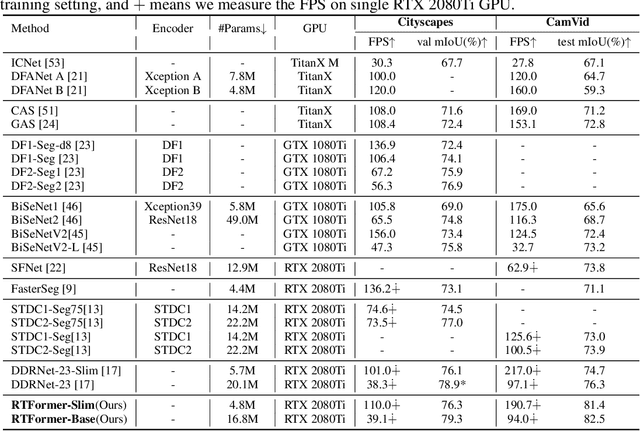
Recently, transformer-based networks have shown impressive results in semantic segmentation. Yet for real-time semantic segmentation, pure CNN-based approaches still dominate in this field, due to the time-consuming computation mechanism of transformer. We propose RTFormer, an efficient dual-resolution transformer for real-time semantic segmenation, which achieves better trade-off between performance and efficiency than CNN-based models. To achieve high inference efficiency on GPU-like devices, our RTFormer leverages GPU-Friendly Attention with linear complexity and discards the multi-head mechanism. Besides, we find that cross-resolution attention is more efficient to gather global context information for high-resolution branch by spreading the high level knowledge learned from low-resolution branch. Extensive experiments on mainstream benchmarks demonstrate the effectiveness of our proposed RTFormer, it achieves state-of-the-art on Cityscapes, CamVid and COCOStuff, and shows promising results on ADE20K. Code is available at PaddleSeg: https://github.com/PaddlePaddle/PaddleSeg.
U-HRNet: Delving into Improving Semantic Representation of High Resolution Network for Dense Prediction
Oct 13, 2022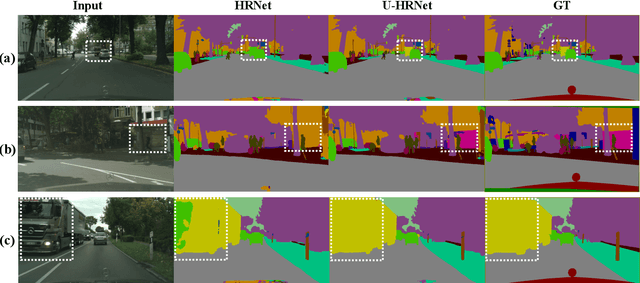

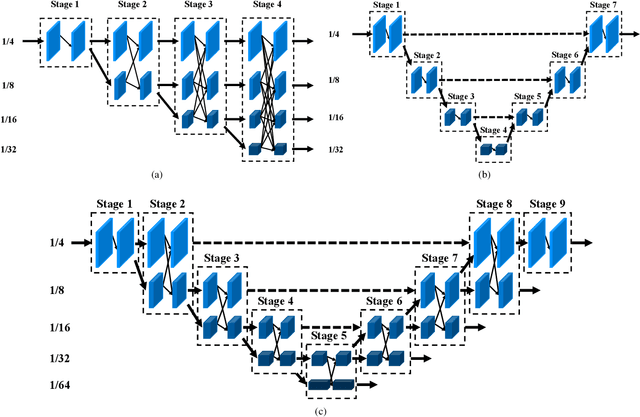
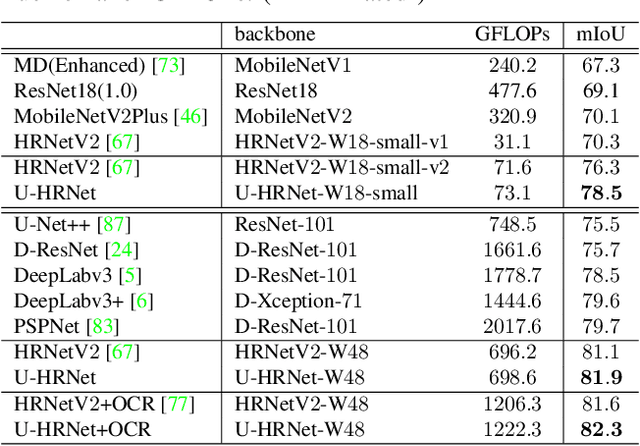
High resolution and advanced semantic representation are both vital for dense prediction. Empirically, low-resolution feature maps often achieve stronger semantic representation, and high-resolution feature maps generally can better identify local features such as edges, but contains weaker semantic information. Existing state-of-the-art frameworks such as HRNet has kept low-resolution and high-resolution feature maps in parallel, and repeatedly exchange the information across different resolutions. However, we believe that the lowest-resolution feature map often contains the strongest semantic information, and it is necessary to go through more layers to merge with high-resolution feature maps, while for high-resolution feature maps, the computational cost of each convolutional layer is very large, and there is no need to go through so many layers. Therefore, we designed a U-shaped High-Resolution Network (U-HRNet), which adds more stages after the feature map with strongest semantic representation and relaxes the constraint in HRNet that all resolutions need to be calculated parallel for a newly added stage. More calculations are allocated to low-resolution feature maps, which significantly improves the overall semantic representation. U-HRNet is a substitute for the HRNet backbone and can achieve significant improvement on multiple semantic segmentation and depth prediction datasets, under the exactly same training and inference setting, with almost no increasing in the amount of calculation. Code is available at PaddleSeg: https://github.com/PaddlePaddle/PaddleSeg.
Repainting and Imitating Learning for Lane Detection
Oct 11, 2022

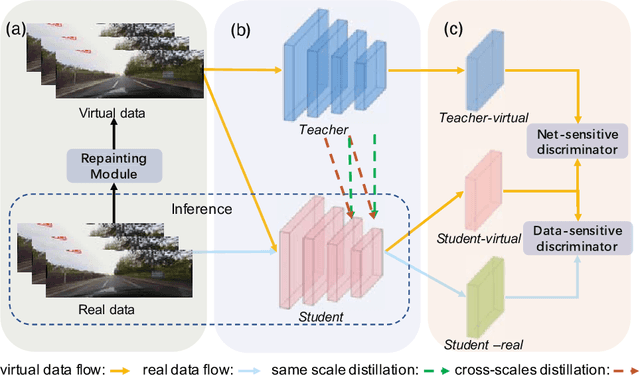
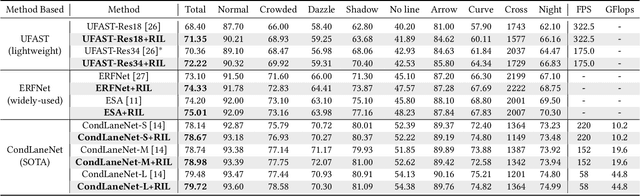
Current lane detection methods are struggling with the invisibility lane issue caused by heavy shadows, severe road mark degradation, and serious vehicle occlusion. As a result, discriminative lane features can be barely learned by the network despite elaborate designs due to the inherent invisibility of lanes in the wild. In this paper, we target at finding an enhanced feature space where the lane features are distinctive while maintaining a similar distribution of lanes in the wild. To achieve this, we propose a novel Repainting and Imitating Learning (RIL) framework containing a pair of teacher and student without any extra data or extra laborious labeling. Specifically, in the repainting step, an enhanced ideal virtual lane dataset is built in which only the lane regions are repainted while non-lane regions are kept unchanged, maintaining the similar distribution of lanes in the wild. The teacher model learns enhanced discriminative representation based on the virtual data and serves as the guidance for a student model to imitate. In the imitating learning step, through the scale-fusing distillation module, the student network is encouraged to generate features that mimic the teacher model both on the same scale and cross scales. Furthermore, the coupled adversarial module builds the bridge to connect not only teacher and student models but also virtual and real data, adjusting the imitating learning process dynamically. Note that our method introduces no extra time cost during inference and can be plug-and-play in various cutting-edge lane detection networks. Experimental results prove the effectiveness of the RIL framework both on CULane and TuSimple for four modern lane detection methods. The code and model will be available soon.
StyleSwap: Style-Based Generator Empowers Robust Face Swapping
Sep 27, 2022
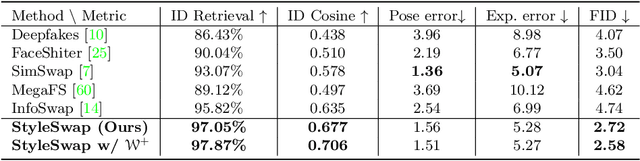
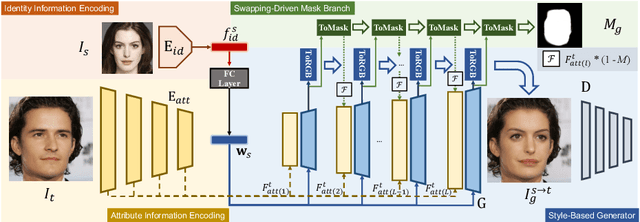

Numerous attempts have been made to the task of person-agnostic face swapping given its wide applications. While existing methods mostly rely on tedious network and loss designs, they still struggle in the information balancing between the source and target faces, and tend to produce visible artifacts. In this work, we introduce a concise and effective framework named StyleSwap. Our core idea is to leverage a style-based generator to empower high-fidelity and robust face swapping, thus the generator's advantage can be adopted for optimizing identity similarity. We identify that with only minimal modifications, a StyleGAN2 architecture can successfully handle the desired information from both source and target. Additionally, inspired by the ToRGB layers, a Swapping-Driven Mask Branch is further devised to improve information blending. Furthermore, the advantage of StyleGAN inversion can be adopted. Particularly, a Swapping-Guided ID Inversion strategy is proposed to optimize identity similarity. Extensive experiments validate that our framework generates high-quality face swapping results that outperform state-of-the-art methods both qualitatively and quantitatively.
Effective Invertible Arbitrary Image Rescaling
Sep 26, 2022
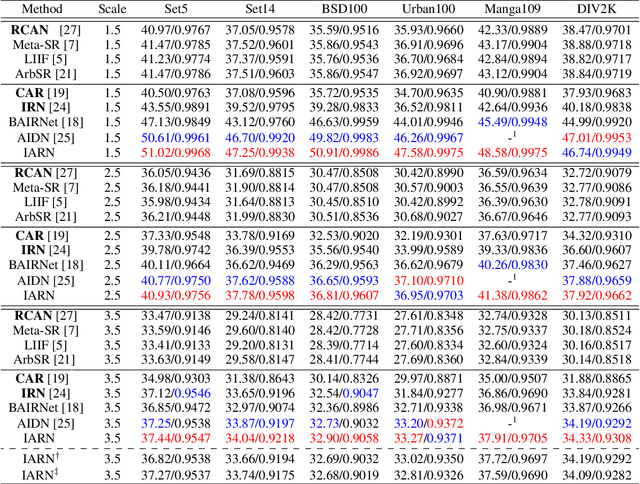
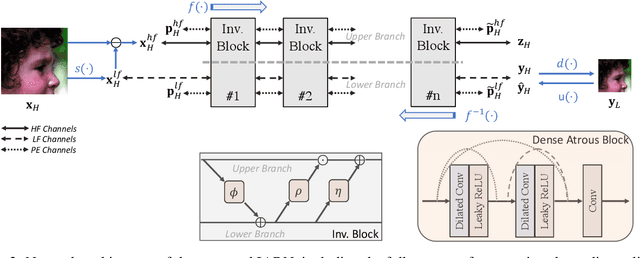
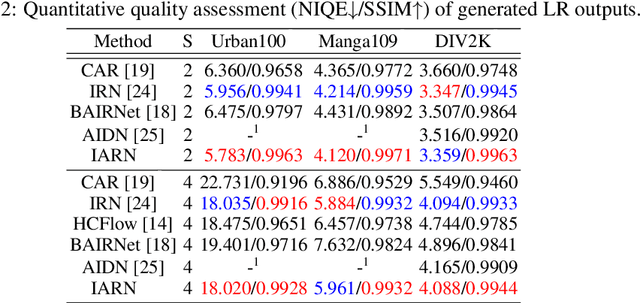
Great successes have been achieved using deep learning techniques for image super-resolution (SR) with fixed scales. To increase its real world applicability, numerous models have also been proposed to restore SR images with arbitrary scale factors, including asymmetric ones where images are resized to different scales along horizontal and vertical directions. Though most models are only optimized for the unidirectional upscaling task while assuming a predefined downscaling kernel for low-resolution (LR) inputs, recent models based on Invertible Neural Networks (INN) are able to increase upscaling accuracy significantly by optimizing the downscaling and upscaling cycle jointly. However, limited by the INN architecture, it is constrained to fixed integer scale factors and requires one model for each scale. Without increasing model complexity, a simple and effective invertible arbitrary rescaling network (IARN) is proposed to achieve arbitrary image rescaling by training only one model in this work. Using innovative components like position-aware scale encoding and preemptive channel splitting, the network is optimized to convert the non-invertible rescaling cycle to an effectively invertible process. It is shown to achieve a state-of-the-art (SOTA) performance in bidirectional arbitrary rescaling without compromising perceptual quality in LR outputs. It is also demonstrated to perform well on tests with asymmetric scales using the same network architecture.
AGO-Net: Association-Guided 3D Point Cloud Object Detection Network
Aug 24, 2022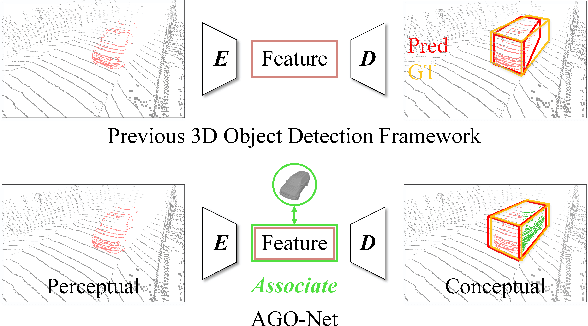
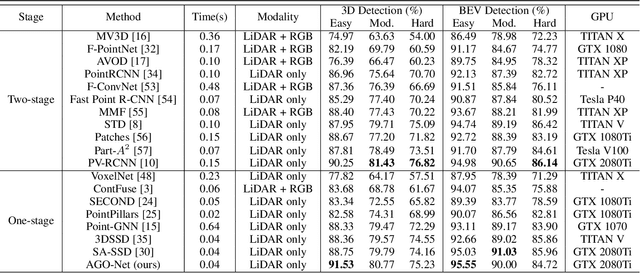
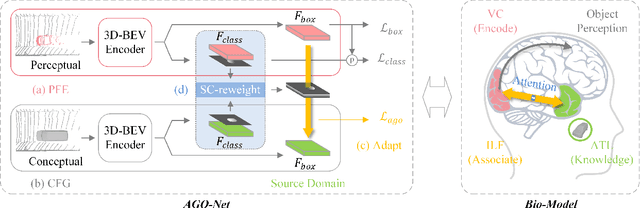
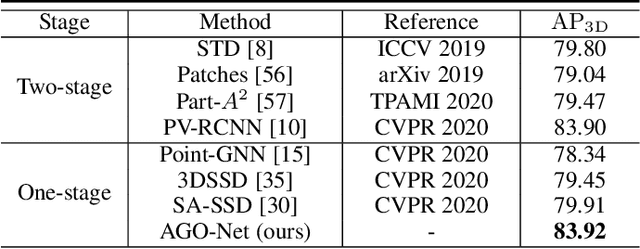
The human brain can effortlessly recognize and localize objects, whereas current 3D object detection methods based on LiDAR point clouds still report inferior performance for detecting occluded and distant objects: the point cloud appearance varies greatly due to occlusion, and has inherent variance in point densities along the distance to sensors. Therefore, designing feature representations robust to such point clouds is critical. Inspired by human associative recognition, we propose a novel 3D detection framework that associates intact features for objects via domain adaptation. We bridge the gap between the perceptual domain, where features are derived from real scenes with sub-optimal representations, and the conceptual domain, where features are extracted from augmented scenes that consist of non-occlusion objects with rich detailed information. A feasible method is investigated to construct conceptual scenes without external datasets. We further introduce an attention-based re-weighting module that adaptively strengthens the feature adaptation of more informative regions. The network's feature enhancement ability is exploited without introducing extra cost during inference, which is plug-and-play in various 3D detection frameworks. We achieve new state-of-the-art performance on the KITTI 3D detection benchmark in both accuracy and speed. Experiments on nuScenes and Waymo datasets also validate the versatility of our method.
CODER: Coupled Diversity-Sensitive Momentum Contrastive Learning for Image-Text Retrieval
Aug 21, 2022
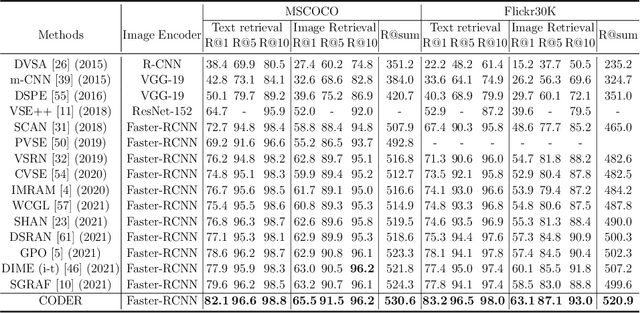
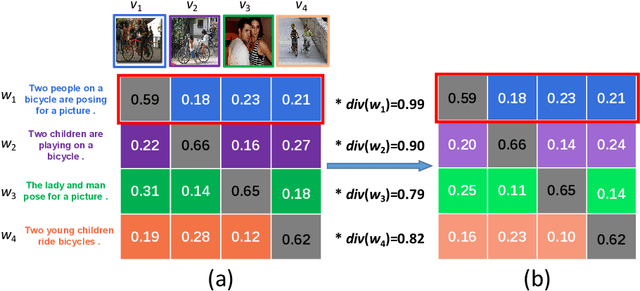
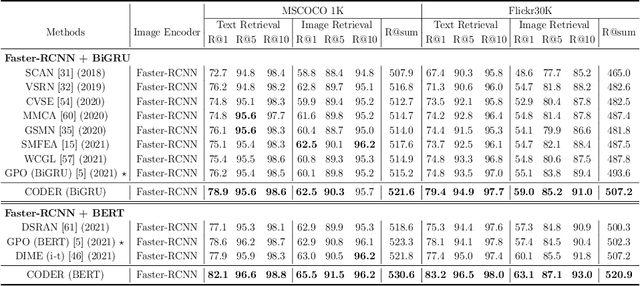
Image-Text Retrieval (ITR) is challenging in bridging visual and lingual modalities. Contrastive learning has been adopted by most prior arts. Except for limited amount of negative image-text pairs, the capability of constrastive learning is restricted by manually weighting negative pairs as well as unawareness of external knowledge. In this paper, we propose our novel Coupled Diversity-Sensitive Momentum Constrastive Learning (CODER) for improving cross-modal representation. Firstly, a novel diversity-sensitive contrastive learning (DCL) architecture is invented. We introduce dynamic dictionaries for both modalities to enlarge the scale of image-text pairs, and diversity-sensitiveness is achieved by adaptive negative pair weighting. Furthermore, two branches are designed in CODER. One learns instance-level embeddings from image/text, and it also generates pseudo online clustering labels for its input image/text based on their embeddings. Meanwhile, the other branch learns to query from commonsense knowledge graph to form concept-level descriptors for both modalities. Afterwards, both branches leverage DCL to align the cross-modal embedding spaces while an extra pseudo clustering label prediction loss is utilized to promote concept-level representation learning for the second branch. Extensive experiments conducted on two popular benchmarks, i.e. MSCOCO and Flicker30K, validate CODER remarkably outperforms the state-of-the-art approaches.
Part-aware Prototypical Graph Network for One-shot Skeleton-based Action Recognition
Aug 19, 2022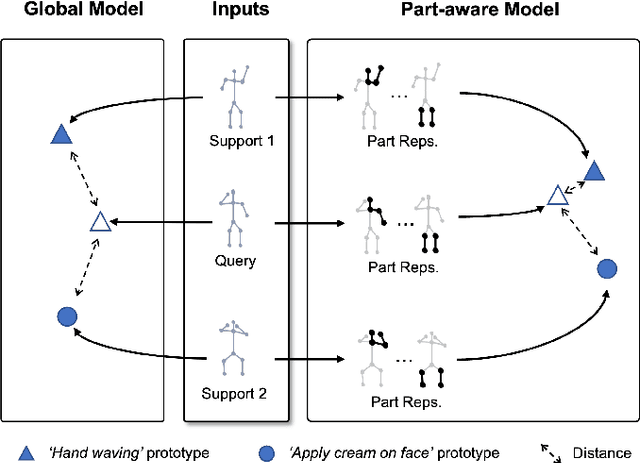
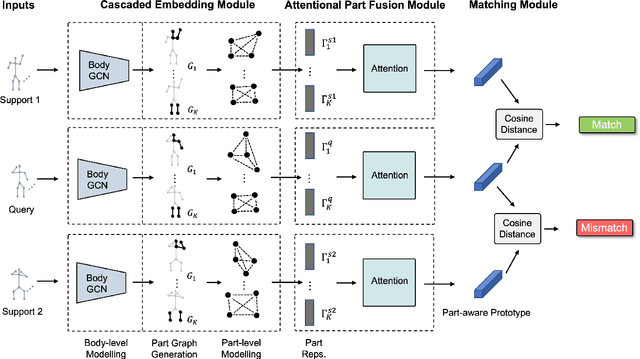
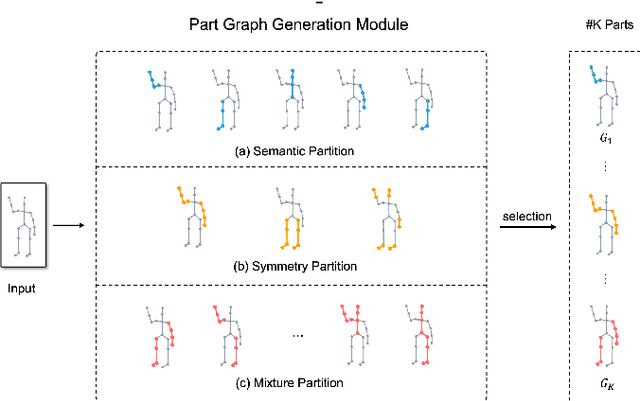
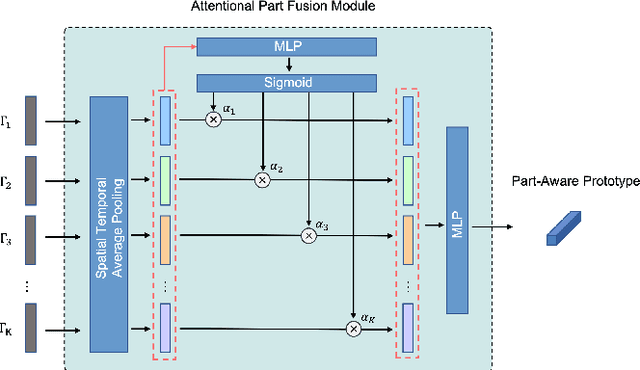
In this paper, we study the problem of one-shot skeleton-based action recognition, which poses unique challenges in learning transferable representation from base classes to novel classes, particularly for fine-grained actions. Existing meta-learning frameworks typically rely on the body-level representations in spatial dimension, which limits the generalisation to capture subtle visual differences in the fine-grained label space. To overcome the above limitation, we propose a part-aware prototypical representation for one-shot skeleton-based action recognition. Our method captures skeleton motion patterns at two distinctive spatial levels, one for global contexts among all body joints, referred to as body level, and the other attends to local spatial regions of body parts, referred to as the part level. We also devise a class-agnostic attention mechanism to highlight important parts for each action class. Specifically, we develop a part-aware prototypical graph network consisting of three modules: a cascaded embedding module for our dual-level modelling, an attention-based part fusion module to fuse parts and generate part-aware prototypes, and a matching module to perform classification with the part-aware representations. We demonstrate the effectiveness of our method on two public skeleton-based action recognition datasets: NTU RGB+D 120 and NW-UCLA.