 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePP-MobileSeg: Explore the Fast and Accurate Semantic Segmentation Model on Mobile Devices
Apr 11, 2023The success of transformers in computer vision has led to several attempts to adapt them for mobile devices, but their performance remains unsatisfactory in some real-world applications. To address this issue, we propose PP-MobileSeg, a semantic segmentation model that achieves state-of-the-art performance on mobile devices. PP-MobileSeg comprises three novel parts: the StrideFormer backbone, the Aggregated Attention Module (AAM), and the Valid Interpolate Module (VIM). The four-stage StrideFormer backbone is built with MV3 blocks and strided SEA attention, and it is able to extract rich semantic and detailed features with minimal parameter overhead. The AAM first filters the detailed features through semantic feature ensemble voting and then combines them with semantic features to enhance the semantic information. Furthermore, we proposed VIM to upsample the downsampled feature to the resolution of the input image. It significantly reduces model latency by only interpolating classes present in the final prediction, which is the most significant contributor to overall model latency. Extensive experiments show that PP-MobileSeg achieves a superior tradeoff between accuracy, model size, and latency compared to other methods. On the ADE20K dataset, PP-MobileSeg achieves 1.57% higher accuracy in mIoU than SeaFormer-Base with 32.9% fewer parameters and 42.3% faster acceleration on Qualcomm Snapdragon 855. Source codes are available at https://github.com/PaddlePaddle/PaddleSeg/tree/release/2.8.
EISeg: An Efficient Interactive Segmentation Tool based on PaddlePaddle
Oct 18, 2022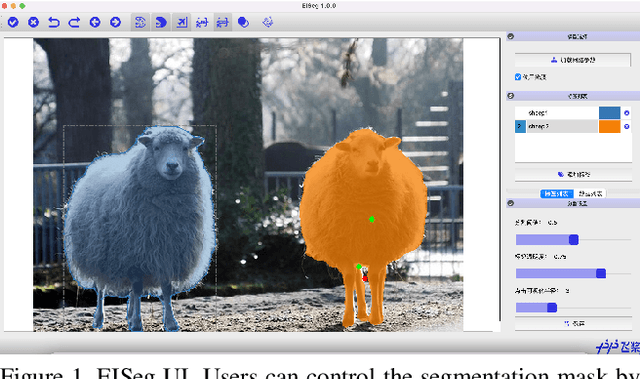

In recent years, the rapid development of deep learning has brought great advancements to image and video segmentation methods based on neural networks. However, to unleash the full potential of such models, large numbers of high-quality annotated images are necessary for model training. Currently, many widely used open-source image segmentation software relies heavily on manual annotation which is tedious and time-consuming. In this work, we introduce EISeg, an Efficient Interactive SEGmentation annotation tool that can drastically improve image segmentation annotation efficiency, generating highly accurate segmentation masks with only a few clicks. We also provide various domain-specific models for remote sensing, medical imaging, industrial quality inspections, human segmentation, and temporal aware models for video segmentation. The source code for our algorithm and user interface are available at: https://github.com/PaddlePaddle/PaddleSeg.
U-HRNet: Delving into Improving Semantic Representation of High Resolution Network for Dense Prediction
Oct 13, 2022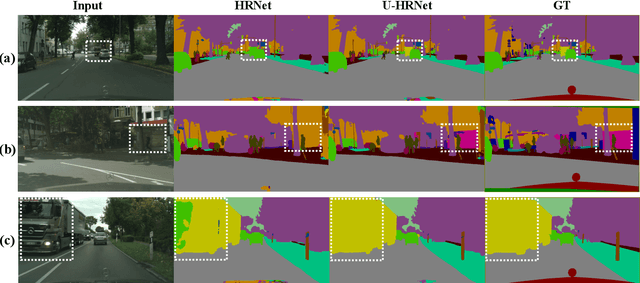

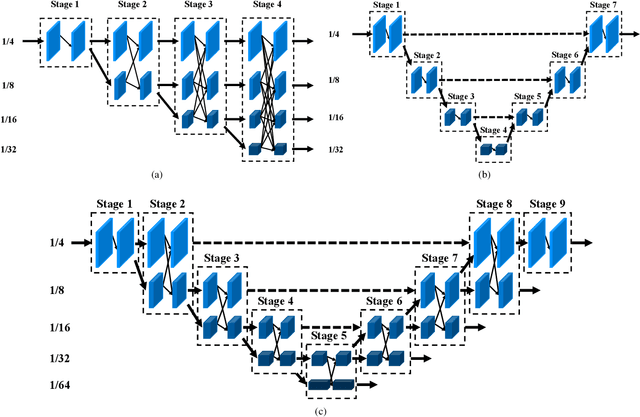
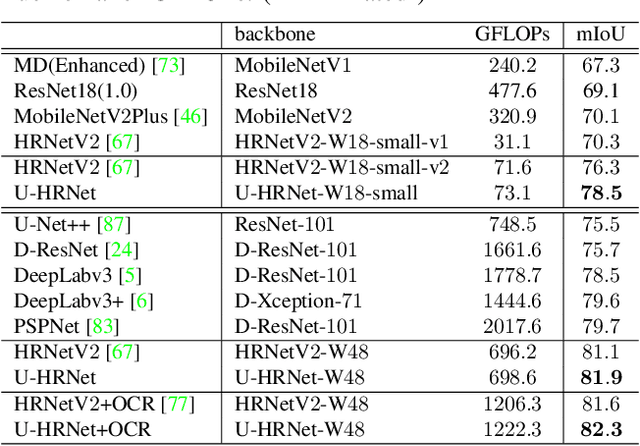
High resolution and advanced semantic representation are both vital for dense prediction. Empirically, low-resolution feature maps often achieve stronger semantic representation, and high-resolution feature maps generally can better identify local features such as edges, but contains weaker semantic information. Existing state-of-the-art frameworks such as HRNet has kept low-resolution and high-resolution feature maps in parallel, and repeatedly exchange the information across different resolutions. However, we believe that the lowest-resolution feature map often contains the strongest semantic information, and it is necessary to go through more layers to merge with high-resolution feature maps, while for high-resolution feature maps, the computational cost of each convolutional layer is very large, and there is no need to go through so many layers. Therefore, we designed a U-shaped High-Resolution Network (U-HRNet), which adds more stages after the feature map with strongest semantic representation and relaxes the constraint in HRNet that all resolutions need to be calculated parallel for a newly added stage. More calculations are allocated to low-resolution feature maps, which significantly improves the overall semantic representation. U-HRNet is a substitute for the HRNet backbone and can achieve significant improvement on multiple semantic segmentation and depth prediction datasets, under the exactly same training and inference setting, with almost no increasing in the amount of calculation. Code is available at PaddleSeg: https://github.com/PaddlePaddle/PaddleSeg.
PP-Matting: High-Accuracy Natural Image Matting
Apr 20, 2022
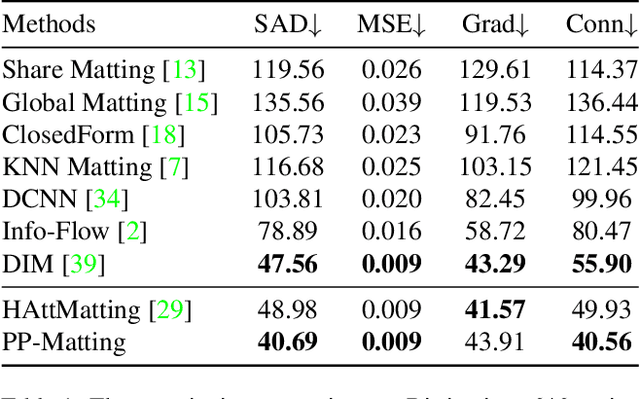
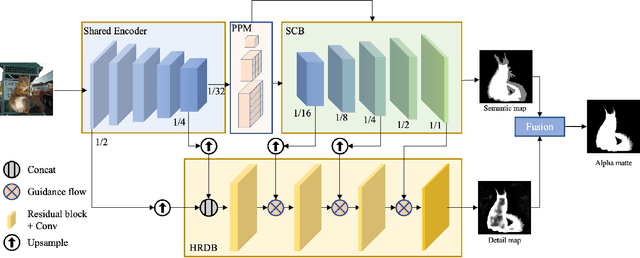
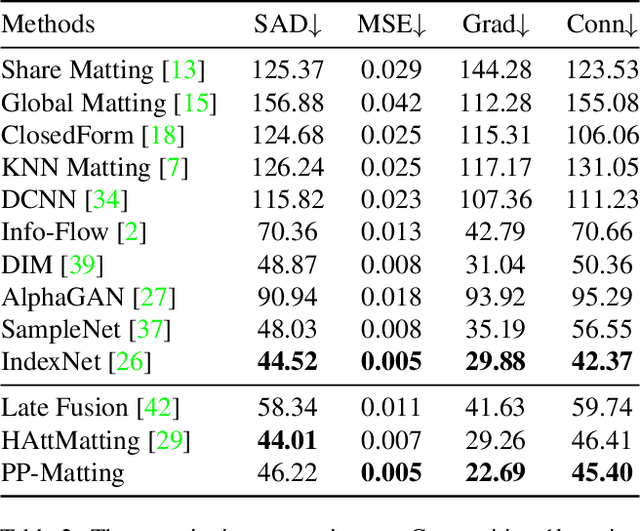
Natural image matting is a fundamental and challenging computer vision task. It has many applications in image editing and composition. Recently, deep learning-based approaches have achieved great improvements in image matting. However, most of them require a user-supplied trimap as an auxiliary input, which limits the matting applications in the real world. Although some trimap-free approaches have been proposed, the matting quality is still unsatisfactory compared to trimap-based ones. Without the trimap guidance, the matting models suffer from foreground-background ambiguity easily, and also generate blurry details in the transition area. In this work, we propose PP-Matting, a trimap-free architecture that can achieve high-accuracy natural image matting. Our method applies a high-resolution detail branch (HRDB) that extracts fine-grained details of the foreground with keeping feature resolution unchanged. Also, we propose a semantic context branch (SCB) that adopts a semantic segmentation subtask. It prevents the detail prediction from local ambiguity caused by semantic context missing. In addition, we conduct extensive experiments on two well-known benchmarks: Composition-1k and Distinctions-646. The results demonstrate the superiority of PP-Matting over previous methods. Furthermore, we provide a qualitative evaluation of our method on human matting which shows its outstanding performance in the practical application. The code and pre-trained models will be available at PaddleSeg: https://github.com/PaddlePaddle/PaddleSeg.
PP-LiteSeg: A Superior Real-Time Semantic Segmentation Model
Apr 06, 2022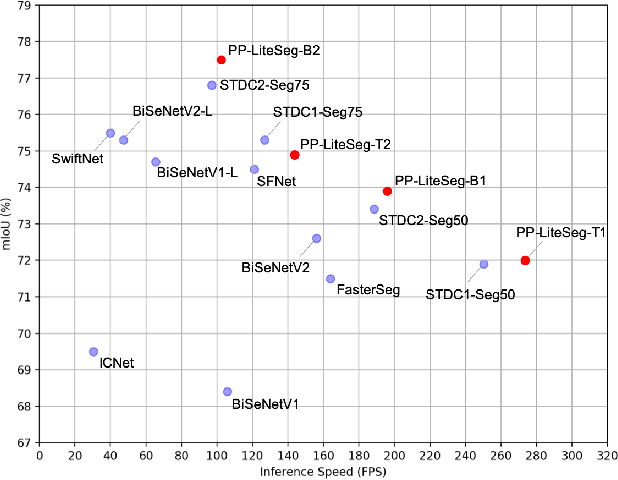

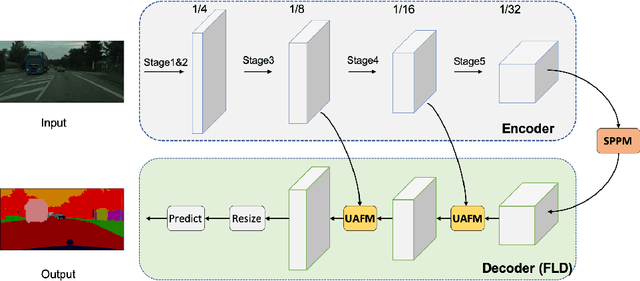
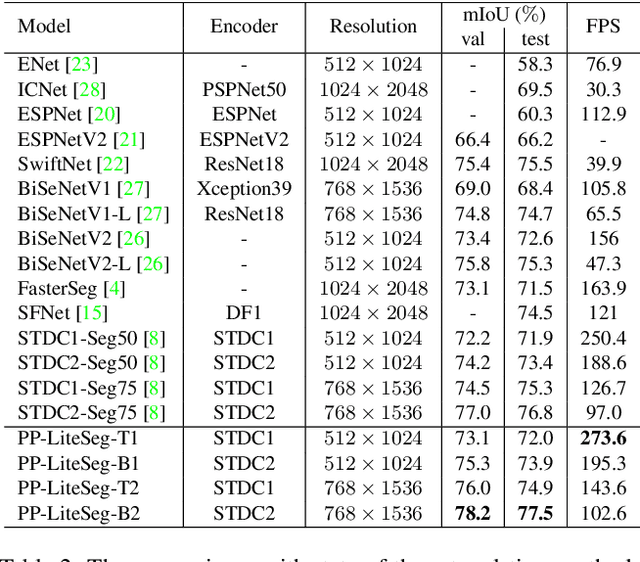
Real-world applications have high demands for semantic segmentation methods. Although semantic segmentation has made remarkable leap-forwards with deep learning, the performance of real-time methods is not satisfactory. In this work, we propose PP-LiteSeg, a novel lightweight model for the real-time semantic segmentation task. Specifically, we present a Flexible and Lightweight Decoder (FLD) to reduce computation overhead of previous decoder. To strengthen feature representations, we propose a Unified Attention Fusion Module (UAFM), which takes advantage of spatial and channel attention to produce a weight and then fuses the input features with the weight. Moreover, a Simple Pyramid Pooling Module (SPPM) is proposed to aggregate global context with low computation cost. Extensive evaluations demonstrate that PP-LiteSeg achieves a superior trade-off between accuracy and speed compared to other methods. On the Cityscapes test set, PP-LiteSeg achieves 72.0% mIoU/273.6 FPS and 77.5% mIoU/102.6 FPS on NVIDIA GTX 1080Ti. Source code and models are available at PaddleSeg: https://github.com/PaddlePaddle/PaddleSeg.
PP-HumanSeg: Connectivity-Aware Portrait Segmentation with a Large-Scale Teleconferencing Video Dataset
Dec 14, 2021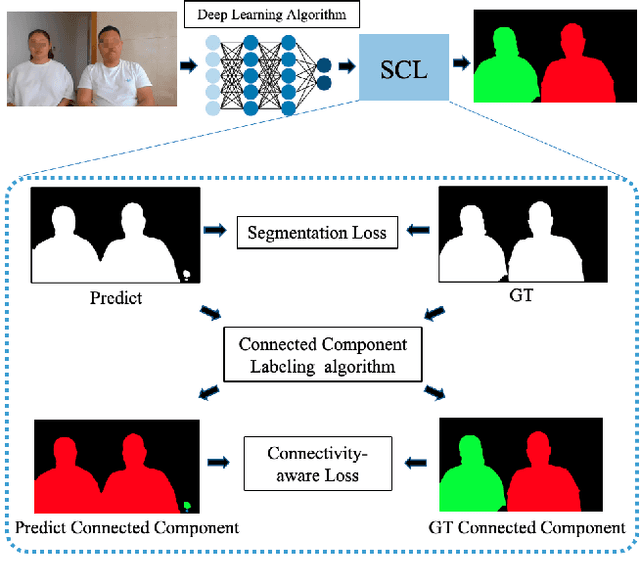


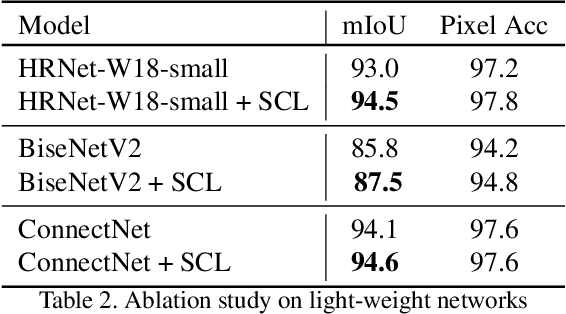
As the COVID-19 pandemic rampages across the world, the demands of video conferencing surge. To this end, real-time portrait segmentation becomes a popular feature to replace backgrounds of conferencing participants. While feature-rich datasets, models and algorithms have been offered for segmentation that extract body postures from life scenes, portrait segmentation has yet not been well covered in a video conferencing context. To facilitate the progress in this field, we introduce an open-source solution named PP-HumanSeg. This work is the first to construct a large-scale video portrait dataset that contains 291 videos from 23 conference scenes with 14K fine-labeled frames and extensions to multi-camera teleconferencing. Furthermore, we propose a novel Semantic Connectivity-aware Learning (SCL) for semantic segmentation, which introduces a semantic connectivity-aware loss to improve the quality of segmentation results from the perspective of connectivity. And we propose an ultra-lightweight model with SCL for practical portrait segmentation, which achieves the best trade-off between IoU and the speed of inference. Extensive evaluations on our dataset demonstrate the superiority of SCL and our model. The source code is available at https://github.com/PaddlePaddle/PaddleSeg.
EdgeFlow: Achieving Practical Interactive Segmentation with Edge-Guided Flow
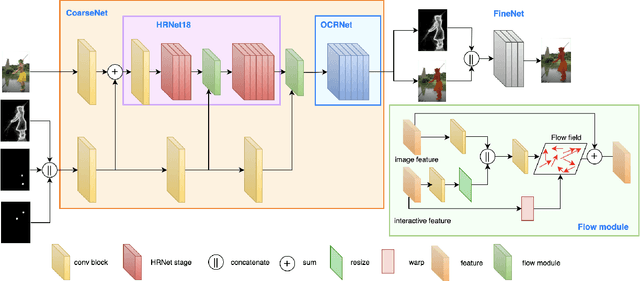
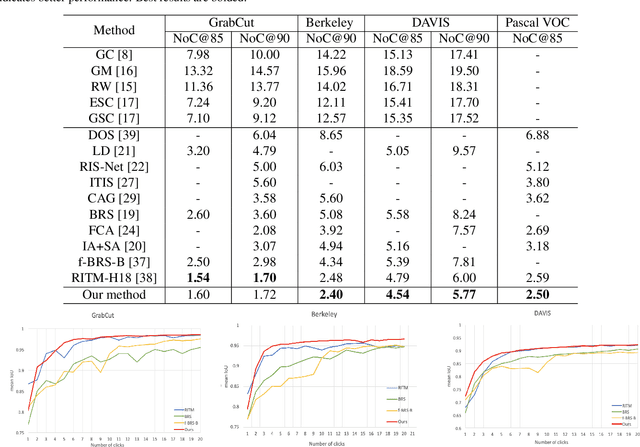
Sep 20, 2021
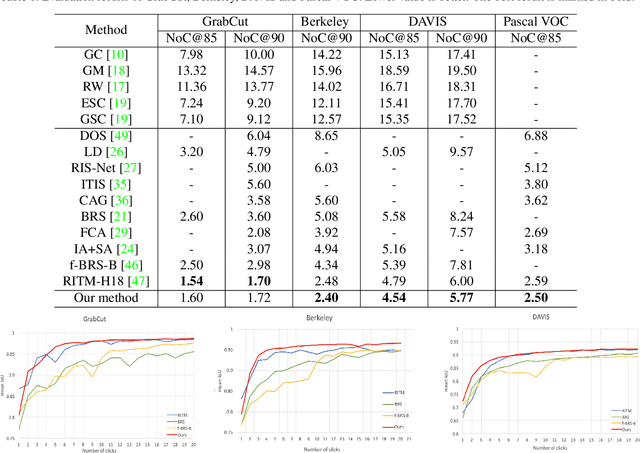
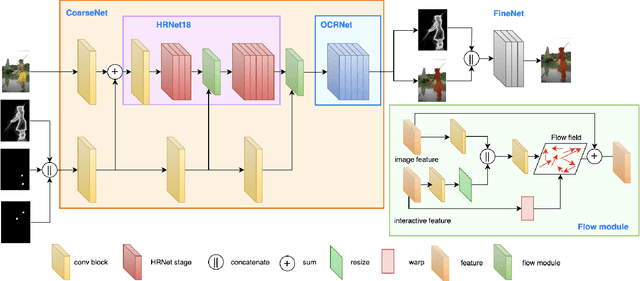

High-quality training data play a key role in image segmentation tasks. Usually, pixel-level annotations are expensive, laborious and time-consuming for the large volume of training data. To reduce labelling cost and improve segmentation quality, interactive segmentation methods have been proposed, which provide the result with just a few clicks. However, their performance does not meet the requirements of practical segmentation tasks in terms of speed and accuracy. In this work, we propose EdgeFlow, a novel architecture that fully utilizes interactive information of user clicks with edge-guided flow. Our method achieves state-of-the-art performance without any post-processing or iterative optimization scheme. Comprehensive experiments on benchmarks also demonstrate the superiority of our method. In addition, with the proposed method, we develop an efficient interactive segmentation tool for practical data annotation tasks. The source code and tool is avaliable at https://github.com/PaddlePaddle/PaddleSeg.
PaddleSeg: A High-Efficient Development Toolkit for Image Segmentation
Jan 15, 2021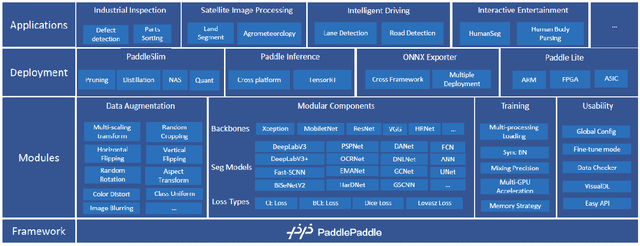
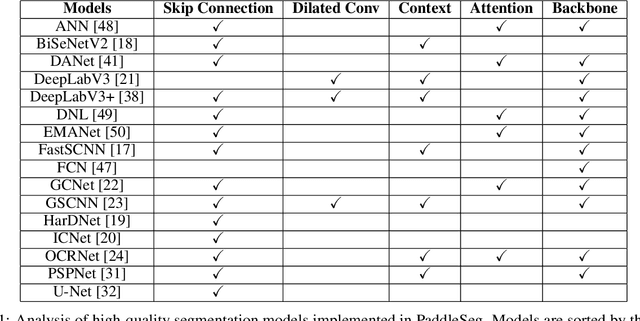

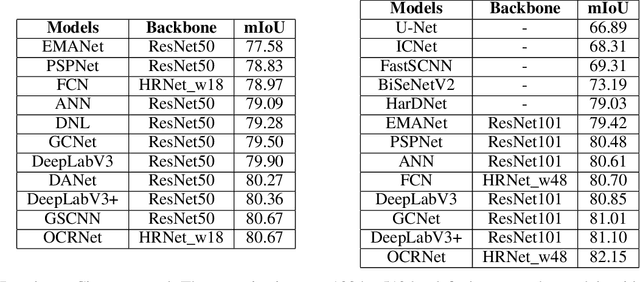
Image Segmentation plays an essential role in computer vision and image processing with various applications from medical diagnosis to autonomous car driving. A lot of segmentation algorithms have been proposed for addressing specific problems. In recent years, the success of deep learning techniques has tremendously influenced a wide range of computer vision areas, and the modern approaches of image segmentation based on deep learning are becoming prevalent. In this article, we introduce a high-efficient development toolkit for image segmentation, named PaddleSeg. The toolkit aims to help both developers and researchers in the whole process of designing segmentation models, training models, optimizing performance and inference speed, and deploying models. Currently, PaddleSeg supports around 20 popular segmentation models and more than 50 pre-trained models from real-time and high-accuracy levels. With modular components and backbone networks, users can easily build over one hundred models for different requirements. Furthermore, we provide comprehensive benchmarks and evaluations to show that these segmentation algorithms trained on our toolkit have more competitive accuracy. Also, we provide various real industrial applications and practical cases based on PaddleSeg. All codes and examples of PaddleSeg are available at https://github.com/PaddlePaddle/PaddleSeg.