 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Forensics of Manipulated Segments in Untrimmed Long Videos
Jun 01, 2026The rapid advancement of AI-driven video generation has transformed content creation, while simultaneously increasing the risk of misinformation through localized manipulations in long-form videos. Existing video forensic methods predominantly operate on short, independent clips, and thus fail to capture realistic scenarios where AI-generated content is sparsely embedded within otherwise authentic footage. To bridge this gap, we formulate the task of Temporal AI-Generated Segment Localization and Explanation, which targets authenticity detection, temporal localization, and interpretable analysis of manipulated segments in untrimmed long videos. We further introduce TASLE, a large-scale benchmark comprising 12,472 untrimmed videos with diverse manipulation patterns and rich annotation signals, including temporal boundaries, authenticity labels, and segment-level rationales. In addition, we propose MSLoc, a coarse-to-fine forensic baseline that combines a boundary-sensitive proposal generation module for efficient long-video scanning with an MLLM-based refinement module for precise boundary localization and interpretable reasoning. Experiments validate the effectiveness of the proposed baseline, highlighting the importance of segment-level explainable forensics for long-form AI-generated video analysis. Our dataset and code are publicly available at https://debby-0527.github.io/TASLE.
Detect by Yourself: Self-Designing Agentic Workflows for Few-Shot Graph Anomaly Detection
May 26, 2026Graph anomaly detection aims to identify anomaly nodes in attributed graphs and plays an important role in real-world applications. However, existing graph anomaly detection methods still face two key challenges: 1) fixed pipelines, which restrict their adaptability across different graph tasks under limited supervision; 2) weak evidence, which prevents them from explicitly incorporating contextual and structural anomaly signals into the detection process. In this paper, we propose a novel framework, self-designing agentic workflows for few-shot graph anomaly detection (SignGAD). Specifically, we propose a novel paradigm that reformulates graph anomaly detection task from training a fixed anomaly detector to designing task-conditioned detection workflows. By constructing detection workflows, SignGAD selects suitable graph encodings and detector designs to exploit task-specific anomaly evidence. Meanwhile, we introduce a guarded final refit strategy to refine the selected workflow by calibrating refit acceptance, enhancing reliability under limited supervision. Extensive experiments conducted on several real-world datasets demonstrate that SignGAD achieves strong performance against state-of-the-art methods, highlighting its effectiveness on graph anomaly detection tasks.
TubiFM: Unified Item, Carousel, and Search Ranking for Streaming Discovery
May 22, 2026Personalized discovery systems often train separate models for item ranking, carousel ranking, and search, even though these tasks expose complementary signals from the same viewer journey: watches shape carousel and item ranking, search queries reveal intent even when they do not lead to a catalog match, and watch history helps interpret search as rewatching, continuation, or new discovery. We introduce the user story, a serialized representation that turns a user's cross-surface history - attributes, sessions, watch events with surface and carousel context, and search events - into a single token sequence. By interleaving pretrained language tokens with domain-specific event tokens, user stories let heterogeneous recommendation and search tasks be expressed as prompted next-token prediction over a shared grammar. TubiFM is one instantiation of this approach: a Llama 3.2 1B-based model trained on user stories and prompted to rank items, carousels, or search results without task-specific architectures. In offline evaluation, this single model outperforms specialist baselines across item, carousel, and search ranking. In online A/B tests, TubiFM significantly improves search total viewing time (TVT) by $+3.9\%$ and carousel TVT by $+0.30\%$. Item ranking is statistically neutral on TVT ($+0.14\%$), but matches a mature production stack; across all three tasks, TubiFM serves on L40S GPUs and reduces p99 ranking latency from 500ms to 200ms. These results show that shared user stories can improve discovery while simplifying ranking systems.
Latent-WAM: Latent World Action Modeling for End-to-End Autonomous Driving
Mar 25, 2026We introduce Latent-WAM, an efficient end-to-end autonomous driving framework that achieves strong trajectory planning through spatially-aware and dynamics-informed latent world representations. Existing world-model-based planners suffer from inadequately compressed representations, limited spatial understanding, and underutilized temporal dynamics, resulting in sub-optimal planning under constrained data and compute budgets. Latent-WAM addresses these limitations with two core modules: a Spatial-Aware Compressive World Encoder (SCWE) that distills geometric knowledge from a foundation model and compresses multi-view images into compact scene tokens via learnable queries, and a Dynamic Latent World Model (DLWM) that employs a causal Transformer to autoregressively predict future world status conditioned on historical visual and motion representations. Extensive experiments on NAVSIM v2 and HUGSIM demonstrate new state-of-the-art results: 89.3 EPDMS on NAVSIM v2 and 28.9 HD-Score on HUGSIM, surpassing the best prior perception-free method by 3.2 EPDMS with significantly less training data and a compact 104M-parameter model.
DreamerAD: Efficient Reinforcement Learning via Latent World Model for Autonomous Driving
Mar 25, 2026We introduce DreamerAD, the first latent world model framework that enables efficient reinforcement learning for autonomous driving by compressing diffusion sampling from 100 steps to 1 - achieving 80x speedup while maintaining visual interpretability. Training RL policies on real-world driving data incurs prohibitive costs and safety risks. While existing pixel-level diffusion world models enable safe imagination-based training, they suffer from multi-step diffusion inference latency (2s/frame) that prevents high-frequency RL interaction. Our approach leverages denoised latent features from video generation models through three key mechanisms: (1) shortcut forcing that reduces sampling complexity via recursive multi-resolution step compression, (2) an autoregressive dense reward model operating directly on latent representations for fine-grained credit assignment, and (3) Gaussian vocabulary sampling for GRPO that constrains exploration to physically plausible trajectories. DreamerAD achieves 87.7 EPDMS on NavSim v2, establishing state-of-the-art performance and demonstrating that latent-space RL is effective for autonomous driving.
LEGATO: Good Identity Unlearning Is Continuous
Jan 07, 2026Machine unlearning has become a crucial role in enabling generative models trained on large datasets to remove sensitive, private, or copyright-protected data. However, existing machine unlearning methods face three challenges in learning to forget identity of generative models: 1) inefficient, where identity erasure requires fine-tuning all the model's parameters; 2) limited controllability, where forgetting intensity cannot be controlled and explainability is lacking; 3) catastrophic collapse, where the model's retention capability undergoes drastic degradation as forgetting progresses. Forgetting has typically been handled through discrete and unstable updates, often requiring full-model fine-tuning and leading to catastrophic collapse. In this work, we argue that identity forgetting should be modeled as a continuous trajectory, and introduce LEGATO - Learn to ForgEt Identity in GenerAtive Models via Trajectory-consistent Neural Ordinary Differential Equations. LEGATO augments pre-trained generators with fine-tunable lightweight Neural ODE adapters, enabling smooth, controllable forgetting while keeping the original model weights frozen. This formulation allows forgetting intensity to be precisely modulated via ODE step size, offering interpretability and robustness. To further ensure stability, we introduce trajectory consistency constraints that explicitly prevent catastrophic collapse during unlearning. Extensive experiments across in-domain and out-of-domain identity unlearning benchmarks show that LEGATO achieves state-of-the-art forgetting performance, avoids catastrophic collapse and reduces fine-tuned parameters.
Inference Time Feature Injection: A Lightweight Approach for Real-Time Recommendation Freshness
Dec 11, 2025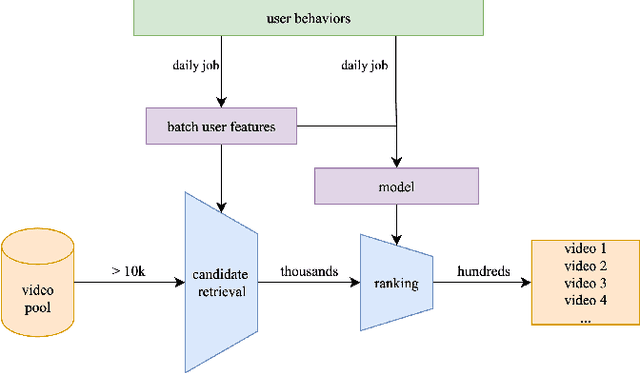
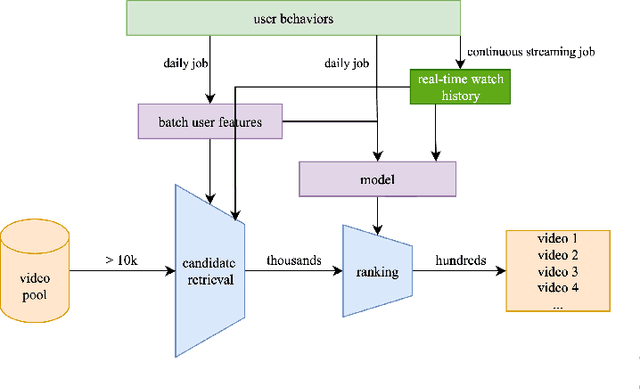
Many recommender systems in long-form video streaming reply on batch-trained models and batch-updated features, where user features are updated daily and served statically throughout the day. While efficient, this approach fails to incorporate a user's most recent actions, often resulting in stale recommendations. In this work, we present a lightweight, model-agnostic approach for intra-day personalization that selectively injects recent watch history at inference time without requiring model retraining. Our approach selectively overrides stale user features at inference time using the recent watch history, allowing the system to adapt instantly to evolving preferences. By reducing the personalization feedback loop from daily to intra-day, we observed a statistically significant 0.47% increase in key user engagement metrics which ranked among the most substantial engagement gains observed in recent experimentation cycles. To our knowledge, this is the first published evidence that intra-day personalization can drive meaningful impact in long-form video streaming service, providing a compelling alternative to full real-time architectures where model retraining is required.
Where to Explore: A Reach and Cost-Aware Approach for Unbiased Data Collection in Recommender Systems
Dec 11, 2025Exploration is essential to improve long-term recommendation quality, but it often degrades short-term business performance, especially in remote-first TV environments where users engage passively, expect instant relevance, and offer few chances for correction. This paper introduces an approach for delivering content-level exploration safely and efficiently by optimizing its placement based on reach and opportunity cost. Deployed on a large-scale streaming platform with over 100 million monthly active users, our approach identifies scroll-depth regions with lower engagement and strategically introduces a dedicated container, the "Something Completely Different" row containing randomized content. Rather than enforcing exploration uniformly across the user interface (UI), we condition its appearance on empirically low-cost, high-reach positions to ensure minimal tradeoff against platform-level watch time goals. Extensive A/B testing shows that this strategy preserves business metrics while collecting unbiased interaction data. Our method complements existing intra-row diversification and bandit-based exploration techniques by introducing a deployable, behaviorally informed mechanism for surfacing exploratory content at scale. Moreover, we demonstrate that the collected unbiased data, integrated into downstream candidate generation, significantly improves user engagement, validating its value for recommender systems.
A Closer Look at Edema Area Segmentation in SD-OCT Images Using Adversarial Framework
Aug 26, 2025The development of artificial intelligence models for macular edema (ME) analy-sis always relies on expert-annotated pixel-level image datasets which are expen-sive to collect prospectively. While anomaly-detection-based weakly-supervised methods have shown promise in edema area (EA) segmentation task, their per-formance still lags behind fully-supervised approaches. In this paper, we leverage the strong correlation between EA and retinal layers in spectral-domain optical coherence tomography (SD-OCT) images, along with the update characteristics of weakly-supervised learning, to enhance an off-the-shelf adversarial framework for EA segmentation with a novel layer-structure-guided post-processing step and a test-time-adaptation (TTA) strategy. By incorporating additional retinal lay-er information, our framework reframes the dense EA prediction task as one of confirming intersection points between the EA contour and retinal layers, result-ing in predictions that better align with the shape prior of EA. Besides, the TTA framework further helps address discrepancies in the manifestations and presen-tations of EA between training and test sets. Extensive experiments on two pub-licly available datasets demonstrate that these two proposed ingredients can im-prove the accuracy and robustness of EA segmentation, bridging the gap between weakly-supervised and fully-supervised models.
Runtime Failure Hunting for Physics Engine Based Software Systems: How Far Can We Go?
Jul 29, 2025Physics Engines (PEs) are fundamental software frameworks that simulate physical interactions in applications ranging from entertainment to safety-critical systems. Despite their importance, PEs suffer from physics failures, deviations from expected physical behaviors that can compromise software reliability, degrade user experience, and potentially cause critical failures in autonomous vehicles or medical robotics. Current testing approaches for PE-based software are inadequate, typically requiring white-box access and focusing on crash detection rather than semantically complex physics failures. This paper presents the first large-scale empirical study characterizing physics failures in PE-based software. We investigate three research questions addressing the manifestations of physics failures, the effectiveness of detection techniques, and developer perceptions of current detection practices. Our contributions include: (1) a taxonomy of physics failure manifestations; (2) a comprehensive evaluation of detection methods including deep learning, prompt-based techniques, and large multimodal models; and (3) actionable insights from developer experiences for improving detection approaches. To support future research, we release PhysiXFails, code, and other materials at https://sites.google.com/view/physics-failure-detection.