 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEAD: Liberal Feature-based Distillation for Dense Retrieval
Dec 10, 2022



Knowledge distillation is often used to transfer knowledge from a strong teacher model to a relatively weak student model. Traditional knowledge distillation methods include response-based methods and feature-based methods. Response-based methods are used the most widely but suffer from lower upper limit of model performance, while feature-based methods have constraints on the vocabularies and tokenizers. In this paper, we propose a tokenizer-free method liberal feature-based distillation (LEAD). LEAD aligns the distribution between teacher model and student model, which is effective, extendable, portable and has no requirements on vocabularies, tokenizer, or model architecture. Extensive experiments show the effectiveness of LEAD on several widely-used benchmarks, including MS MARCO Passage, TREC Passage 19, TREC Passage 20, MS MARCO Document, TREC Document 19 and TREC Document 20.
Text Embeddings by Weakly-Supervised Contrastive Pre-training
Dec 07, 2022This paper presents E5, a family of state-of-the-art text embeddings that transfer well to a wide range of tasks. The model is trained in a contrastive manner with weak supervision signals from our curated large-scale text pair dataset (called CCPairs). E5 can be readily used as a general-purpose embedding model for any tasks requiring a single-vector representation of texts such as retrieval, clustering, and classification, achieving strong performance in both zero-shot and fine-tuned settings. We conduct extensive evaluations on 56 datasets from the BEIR and MTEB benchmarks. For zero-shot settings, E5 is the first model that outperforms the strong BM25 baseline on the BEIR retrieval benchmark without using any labeled data. When fine-tuned, E5 obtains the best results on the MTEB benchmark, beating existing embedding models with 40x more parameters.
VATLM: Visual-Audio-Text Pre-Training with Unified Masked Prediction for Speech Representation Learning
Nov 21, 2022



Although speech is a simple and effective way for humans to communicate with the outside world, a more realistic speech interaction contains multimodal information, e.g., vision, text. How to design a unified framework to integrate different modal information and leverage different resources (e.g., visual-audio pairs, audio-text pairs, unlabeled speech, and unlabeled text) to facilitate speech representation learning was not well explored. In this paper, we propose a unified cross-modal representation learning framework VATLM (Visual-Audio-Text Language Model). The proposed VATLM employs a unified backbone network to model the modality-independent information and utilizes three simple modality-dependent modules to preprocess visual, speech, and text inputs. In order to integrate these three modalities into one shared semantic space, VATLM is optimized with a masked prediction task of unified tokens, given by our proposed unified tokenizer. We evaluate the pre-trained VATLM on audio-visual related downstream tasks, including audio-visual speech recognition (AVSR), visual speech recognition (VSR) tasks. Results show that the proposed VATLM outperforms previous the state-of-the-art models, such as audio-visual pre-trained AV-HuBERT model, and analysis also demonstrates that VATLM is capable of aligning different modalities into the same space. To facilitate future research, we release the code and pre-trained models at https://aka.ms/vatlm.
Soft-Labeled Contrastive Pre-training for Function-level Code Representation
Oct 18, 2022
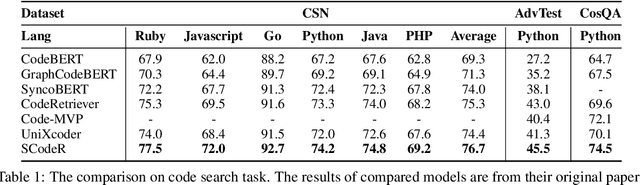
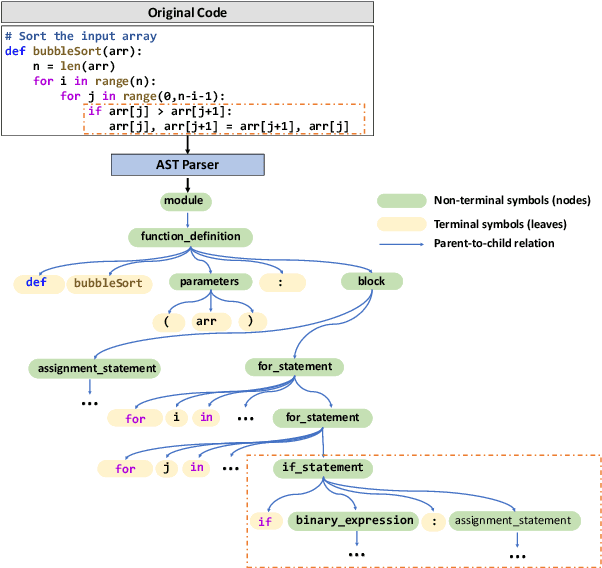
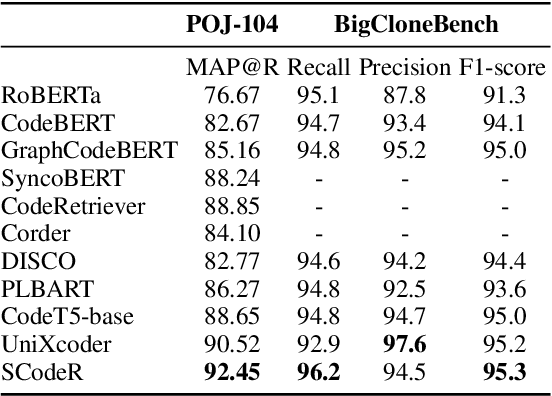
Code contrastive pre-training has recently achieved significant progress on code-related tasks. In this paper, we present \textbf{SCodeR}, a \textbf{S}oft-labeled contrastive pre-training framework with two positive sample construction methods to learn functional-level \textbf{Code} \textbf{R}epresentation. Considering the relevance between codes in a large-scale code corpus, the soft-labeled contrastive pre-training can obtain fine-grained soft-labels through an iterative adversarial manner and use them to learn better code representation. The positive sample construction is another key for contrastive pre-training. Previous works use transformation-based methods like variable renaming to generate semantically equal positive codes. However, they usually result in the generated code with a highly similar surface form, and thus mislead the model to focus on superficial code structure instead of code semantics. To encourage SCodeR to capture semantic information from the code, we utilize code comments and abstract syntax sub-trees of the code to build positive samples. We conduct experiments on four code-related tasks over seven datasets. Extensive experimental results show that SCodeR achieves new state-of-the-art performance on all of them, which illustrates the effectiveness of the proposed pre-training method.
Mixed-modality Representation Learning and Pre-training for Joint Table-and-Text Retrieval in OpenQA
Oct 11, 2022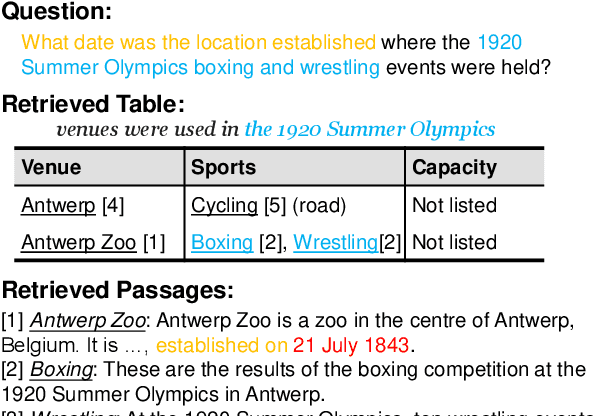

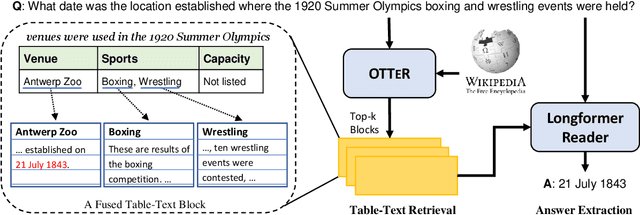
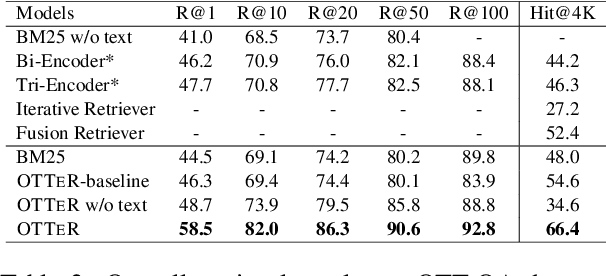
Retrieving evidences from tabular and textual resources is essential for open-domain question answering (OpenQA), which provides more comprehensive information. However, training an effective dense table-text retriever is difficult due to the challenges of table-text discrepancy and data sparsity problem. To address the above challenges, we introduce an optimized OpenQA Table-Text Retriever (OTTeR) to jointly retrieve tabular and textual evidences. Firstly, we propose to enhance mixed-modality representation learning via two mechanisms: modality-enhanced representation and mixed-modality negative sampling strategy. Secondly, to alleviate data sparsity problem and enhance the general retrieval ability, we conduct retrieval-centric mixed-modality synthetic pre-training. Experimental results demonstrate that OTTeR substantially improves the performance of table-and-text retrieval on the OTT-QA dataset. Comprehensive analyses examine the effectiveness of all the proposed mechanisms. Besides, equipped with OTTeR, our OpenQA system achieves the state-of-the-art result on the downstream QA task, with 10.1\% absolute improvement in terms of the exact match over the previous best system. \footnote{All the code and data are available at \url{https://github.com/Jun-jie-Huang/OTTeR}.}
PROD: Progressive Distillation for Dense Retrieval
Sep 27, 2022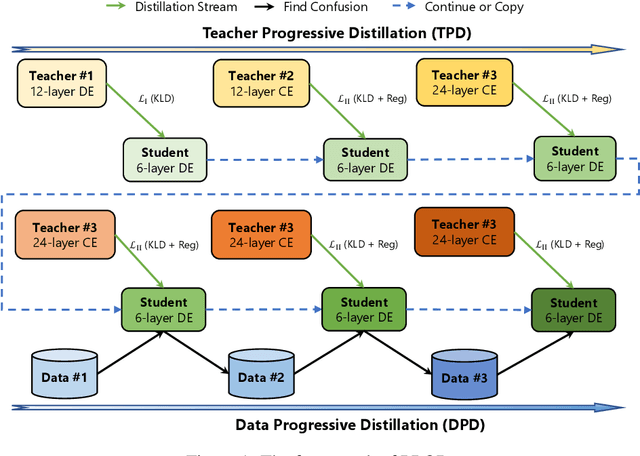
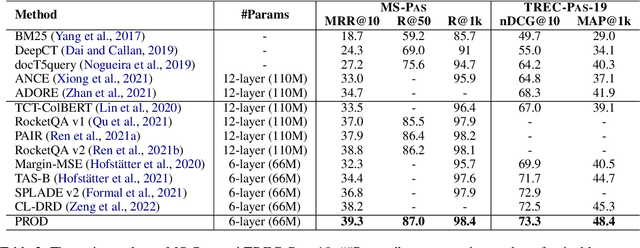
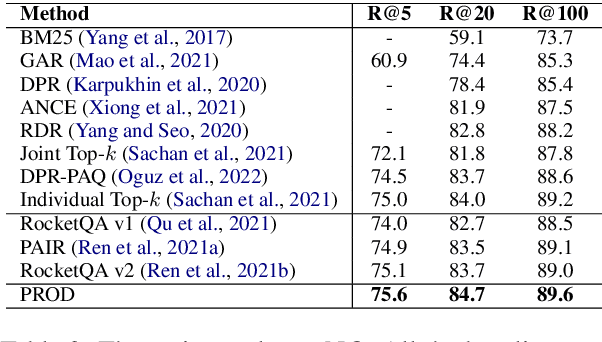
Knowledge distillation is an effective way to transfer knowledge from a strong teacher to an efficient student model. Ideally, we expect the better the teacher is, the better the student. However, this expectation does not always come true. It is common that a better teacher model results in a bad student via distillation due to the nonnegligible gap between teacher and student. To bridge the gap, we propose PROD, a PROgressive Distillation method, for dense retrieval. PROD consists of a teacher progressive distillation and a data progressive distillation to gradually improve the student. We conduct extensive experiments on five widely-used benchmarks, MS MARCO Passage, TREC Passage 19, TREC Document 19, MS MARCO Document and Natural Questions, where PROD achieves the state-of-the-art within the distillation methods for dense retrieval. The code and models will be released.
LexMAE: Lexicon-Bottlenecked Pretraining for Large-Scale Retrieval
Aug 31, 2022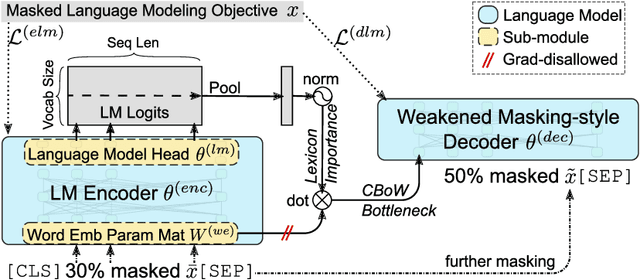
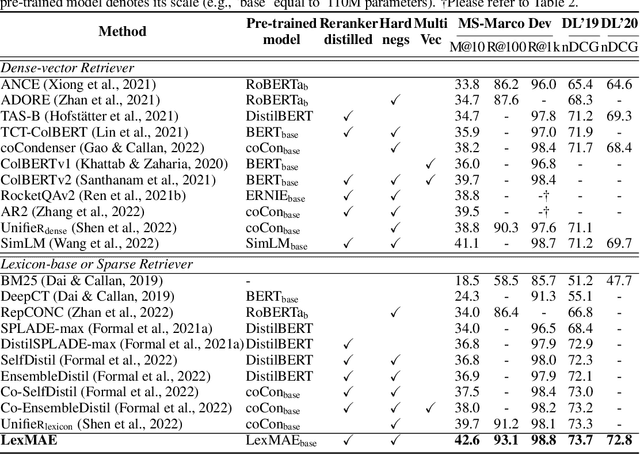
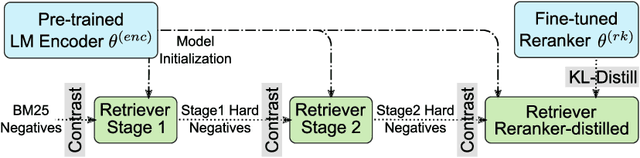
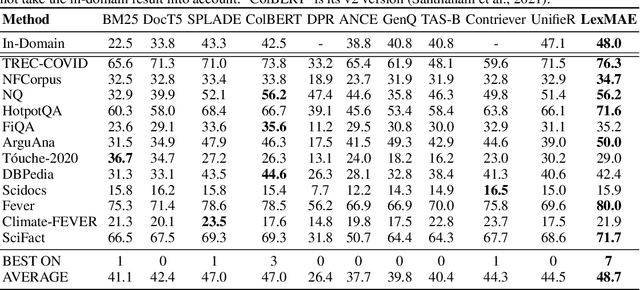
In large-scale retrieval, the lexicon-weighting paradigm, learning weighted sparse representations in vocabulary space, has shown promising results with high quality and low latency. Despite it deeply exploiting the lexicon-representing capability of pre-trained language models, a crucial gap remains between language modeling and lexicon-weighting retrieval -- the former preferring certain or low-entropy words whereas the latter favoring pivot or high-entropy words -- becoming the main barrier to lexicon-weighting performance for large-scale retrieval. To bridge this gap, we propose a brand-new pre-training framework, lexicon-bottlenecked masked autoencoder (LexMAE), to learn importance-aware lexicon representations. Essentially, we present a lexicon-bottlenecked module between a normal language modeling encoder and a weakened decoder, where a continuous bag-of-words bottleneck is constructed to learn a lexicon-importance distribution in an unsupervised fashion. The pre-trained LexMAE is readily transferred to the lexicon-weighting retrieval via fine-tuning, achieving 42.6\% MRR@10 with 45.83 QPS on a CPU machine for the passage retrieval benchmark, MS-Marco. And LexMAE shows state-of-the-art zero-shot transfer capability on BEIR benchmark with 12 datasets.
LED: Lexicon-Enlightened Dense Retriever for Large-Scale Retrieval
Aug 29, 2022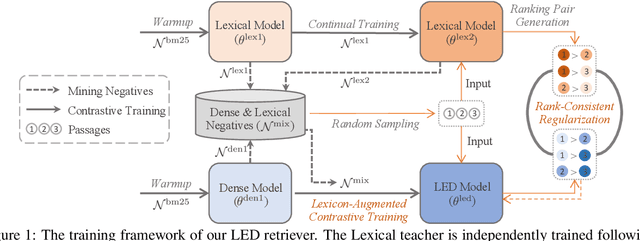
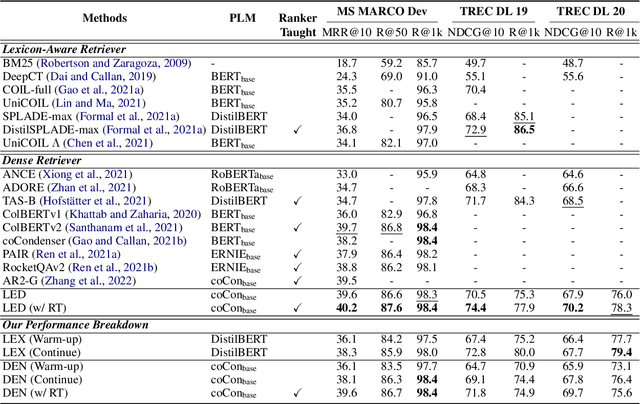
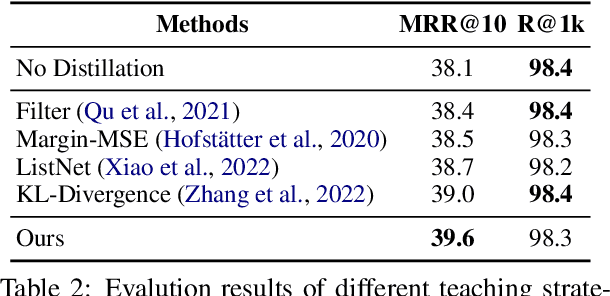
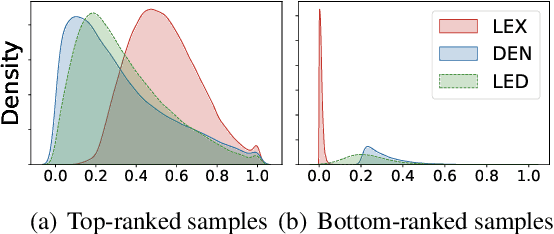
Retrieval models based on dense representations in semantic space have become an indispensable branch for first-stage retrieval. These retrievers benefit from surging advances in representation learning towards compressive global sequence-level embeddings. However, they are prone to overlook local salient phrases and entity mentions in texts, which usually play pivot roles in first-stage retrieval. To mitigate this weakness, we propose to make a dense retriever align a well-performing lexicon-aware representation model. The alignment is achieved by weakened knowledge distillations to enlighten the retriever via two aspects -- 1) a lexicon-augmented contrastive objective to challenge the dense encoder and 2) a pair-wise rank-consistent regularization to make dense model's behavior incline to the other. We evaluate our model on three public benchmarks, which shows that with a comparable lexicon-aware retriever as the teacher, our proposed dense one can bring consistent and significant improvements, and even outdo its teacher. In addition, we found our improvement on the dense retriever is complementary to the standard ranker distillation, which can further lift state-of-the-art performance.
Rethinking the Value of Gazetteer in Chinese Named Entity Recognition
Jul 18, 2022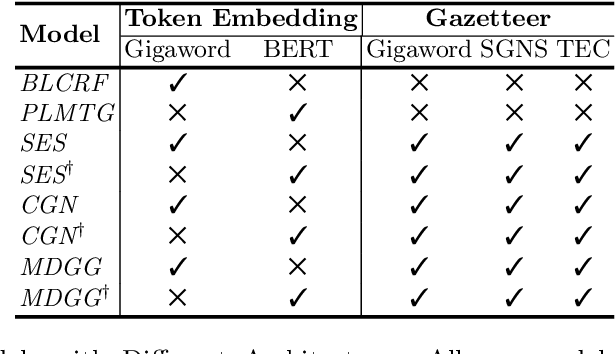


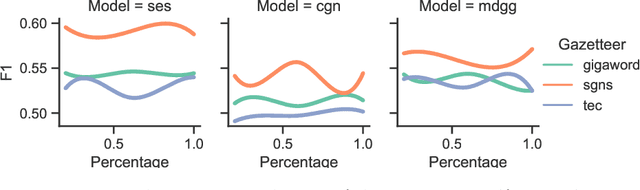
Gazetteer is widely used in Chinese named entity recognition (NER) to enhance span boundary detection and type classification. However, to further understand the generalizability and effectiveness of gazetteers, the NLP community still lacks a systematic analysis of the gazetteer-enhanced NER model. In this paper, we first re-examine the effectiveness several common practices of the gazetteer-enhanced NER models and carry out a series of detailed analysis to evaluate the relationship between the model performance and the gazetteer characteristics, which can guide us to build a more suitable gazetteer. The findings of this paper are as follows: (1) the gazetteer improves most of the situations that the traditional NER model datasets are difficult to learn. (2) the performance of model greatly benefits from the high-quality pre-trained lexeme embeddings. (3) a good gazetteer should cover more entities that can be matched in both the training set and testing set.
SimLM: Pre-training with Representation Bottleneck for Dense Passage Retrieval
Jul 06, 2022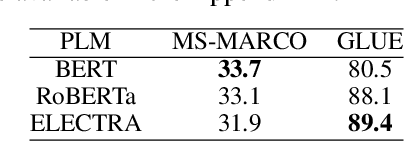
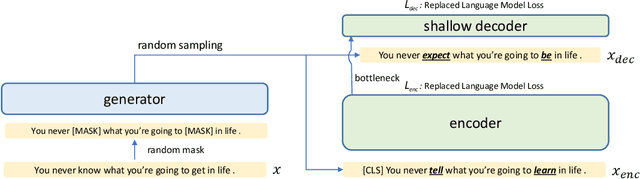
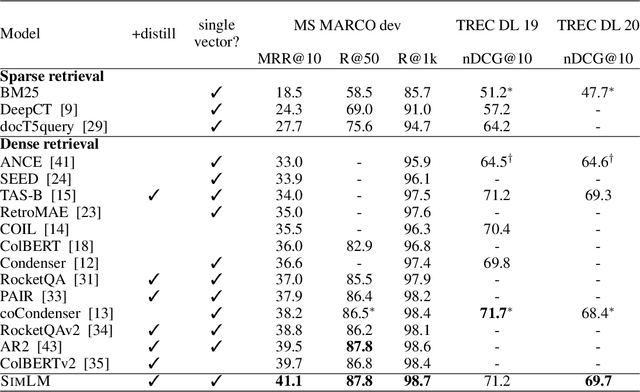
In this paper, we propose SimLM (Similarity matching with Language Model pre-training), a simple yet effective pre-training method for dense passage retrieval. It employs a simple bottleneck architecture that learns to compress the passage information into a dense vector through self-supervised pre-training. We use a replaced language modeling objective, which is inspired by ELECTRA, to improve the sample efficiency and reduce the mismatch of the input distribution between pre-training and fine-tuning. SimLM only requires access to unlabeled corpus, and is more broadly applicable when there are no labeled data or queries. We conduct experiments on several large-scale passage retrieval datasets, and show substantial improvements over strong baselines under various settings. Remarkably, SimLM even outperforms multi-vector approaches such as ColBERTv2 which incurs significantly more storage cost.