 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMPO: Automatic Multi-Branched Prompt Optimization
Oct 11, 2024



Prompt engineering is very important to enhance the performance of large language models (LLMs). When dealing with complex issues, prompt engineers tend to distill multiple patterns from examples and inject relevant solutions to optimize the prompts, achieving satisfying results. However, existing automatic prompt optimization techniques are only limited to producing single flow instructions, struggling with handling diverse patterns. In this paper, we present AMPO, an automatic prompt optimization method that can iteratively develop a multi-branched prompt using failure cases as feedback. Our goal is to explore a novel way of structuring prompts with multi-branches to better handle multiple patterns in complex tasks, for which we introduce three modules: Pattern Recognition, Branch Adjustment, and Branch Pruning. In experiments across five tasks, AMPO consistently achieves the best results. Additionally, our approach demonstrates significant optimization efficiency due to our adoption of a minimal search strategy.
StraGo: Harnessing Strategic Guidance for Prompt Optimization
Oct 11, 2024



Prompt engineering is pivotal for harnessing the capabilities of large language models (LLMs) across diverse applications. While existing prompt optimization methods improve prompt effectiveness, they often lead to prompt drifting, where newly generated prompts can adversely impact previously successful cases while addressing failures. Furthermore, these methods tend to rely heavily on LLMs' intrinsic capabilities for prompt optimization tasks. In this paper, we introduce StraGo (Strategic-Guided Optimization), a novel approach designed to mitigate prompt drifting by leveraging insights from both successful and failed cases to identify critical factors for achieving optimization objectives. StraGo employs a how-to-do methodology, integrating in-context learning to formulate specific, actionable strategies that provide detailed, step-by-step guidance for prompt optimization. Extensive experiments conducted across a range of tasks, including reasoning, natural language understanding, domain-specific knowledge, and industrial applications, demonstrate StraGo's superior performance. It establishes a new state-of-the-art in prompt optimization, showcasing its ability to deliver stable and effective prompt improvements.
MS MARCO Web Search: a Large-scale Information-rich Web Dataset with Millions of Real Click Labels
May 13, 2024



Recent breakthroughs in large models have highlighted the critical significance of data scale, labels and modals. In this paper, we introduce MS MARCO Web Search, the first large-scale information-rich web dataset, featuring millions of real clicked query-document labels. This dataset closely mimics real-world web document and query distribution, provides rich information for various kinds of downstream tasks and encourages research in various areas, such as generic end-to-end neural indexer models, generic embedding models, and next generation information access system with large language models. MS MARCO Web Search offers a retrieval benchmark with three web retrieval challenge tasks that demand innovations in both machine learning and information retrieval system research domains. As the first dataset that meets large, real and rich data requirements, MS MARCO Web Search paves the way for future advancements in AI and system research. MS MARCO Web Search dataset is available at: https://github.com/microsoft/MS-MARCO-Web-Search.
Multilingual E5 Text Embeddings: A Technical Report
Feb 08, 2024This technical report presents the training methodology and evaluation results of the open-source multilingual E5 text embedding models, released in mid-2023. Three embedding models of different sizes (small / base / large) are provided, offering a balance between the inference efficiency and embedding quality. The training procedure adheres to the English E5 model recipe, involving contrastive pre-training on 1 billion multilingual text pairs, followed by fine-tuning on a combination of labeled datasets. Additionally, we introduce a new instruction-tuned embedding model, whose performance is on par with state-of-the-art, English-only models of similar sizes. Information regarding the model release can be found at https://github.com/microsoft/unilm/tree/master/e5 .
Improving Text Embeddings with Large Language Models
Dec 31, 2023



In this paper, we introduce a novel and simple method for obtaining high-quality text embeddings using only synthetic data and less than 1k training steps. Unlike existing methods that often depend on multi-stage intermediate pre-training with billions of weakly-supervised text pairs, followed by fine-tuning with a few labeled datasets, our method does not require building complex training pipelines or relying on manually collected datasets that are often constrained by task diversity and language coverage. We leverage proprietary LLMs to generate diverse synthetic data for hundreds of thousands of text embedding tasks across nearly 100 languages. We then fine-tune open-source decoder-only LLMs on the synthetic data using standard contrastive loss. Experiments demonstrate that our method achieves strong performance on highly competitive text embedding benchmarks without using any labeled data. Furthermore, when fine-tuned with a mixture of synthetic and labeled data, our model sets new state-of-the-art results on the BEIR and MTEB benchmarks.
Large Search Model: Redefining Search Stack in the Era of LLMs
Oct 23, 2023



Modern search engines are built on a stack of different components, including query understanding, retrieval, multi-stage ranking, and question answering, among others. These components are often optimized and deployed independently. In this paper, we introduce a novel conceptual framework called large search model, which redefines the conventional search stack by unifying search tasks with one large language model (LLM). All tasks are formulated as autoregressive text generation problems, allowing for the customization of tasks through the use of natural language prompts. This proposed framework capitalizes on the strong language understanding and reasoning capabilities of LLMs, offering the potential to enhance search result quality while simultaneously simplifying the existing cumbersome search stack. To substantiate the feasibility of this framework, we present a series of proof-of-concept experiments and discuss the potential challenges associated with implementing this approach within real-world search systems.
Inference with Reference: Lossless Acceleration of Large Language Models
Apr 10, 2023We propose LLMA, an LLM accelerator to losslessly speed up Large Language Model (LLM) inference with references. LLMA is motivated by the observation that there are abundant identical text spans between the decoding result by an LLM and the reference that is available in many real world scenarios (e.g., retrieved documents). LLMA first selects a text span from the reference and copies its tokens to the decoder and then efficiently checks the tokens' appropriateness as the decoding result in parallel within one decoding step. The improved computational parallelism allows LLMA to achieve over 2x speed-up for LLMs with identical generation results as greedy decoding in many practical generation scenarios where significant overlap between in-context reference and outputs exists (e.g., search engines and multi-turn conversations).
LEAD: Liberal Feature-based Distillation for Dense Retrieval
Dec 10, 2022



Knowledge distillation is often used to transfer knowledge from a strong teacher model to a relatively weak student model. Traditional knowledge distillation methods include response-based methods and feature-based methods. Response-based methods are used the most widely but suffer from lower upper limit of model performance, while feature-based methods have constraints on the vocabularies and tokenizers. In this paper, we propose a tokenizer-free method liberal feature-based distillation (LEAD). LEAD aligns the distribution between teacher model and student model, which is effective, extendable, portable and has no requirements on vocabularies, tokenizer, or model architecture. Extensive experiments show the effectiveness of LEAD on several widely-used benchmarks, including MS MARCO Passage, TREC Passage 19, TREC Passage 20, MS MARCO Document, TREC Document 19 and TREC Document 20.
Text Embeddings by Weakly-Supervised Contrastive Pre-training
Dec 07, 2022This paper presents E5, a family of state-of-the-art text embeddings that transfer well to a wide range of tasks. The model is trained in a contrastive manner with weak supervision signals from our curated large-scale text pair dataset (called CCPairs). E5 can be readily used as a general-purpose embedding model for any tasks requiring a single-vector representation of texts such as retrieval, clustering, and classification, achieving strong performance in both zero-shot and fine-tuned settings. We conduct extensive evaluations on 56 datasets from the BEIR and MTEB benchmarks. For zero-shot settings, E5 is the first model that outperforms the strong BM25 baseline on the BEIR retrieval benchmark without using any labeled data. When fine-tuned, E5 obtains the best results on the MTEB benchmark, beating existing embedding models with 40x more parameters.
LexMAE: Lexicon-Bottlenecked Pretraining for Large-Scale Retrieval
Aug 31, 2022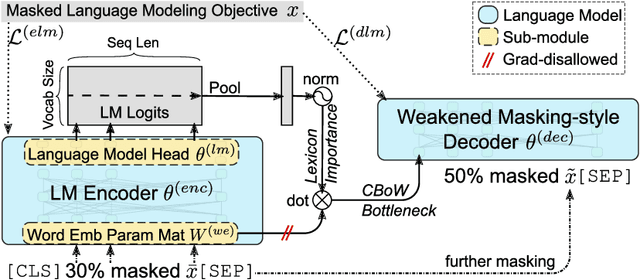
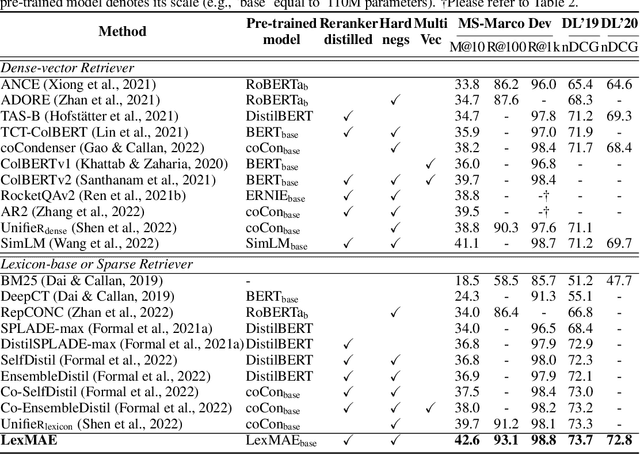
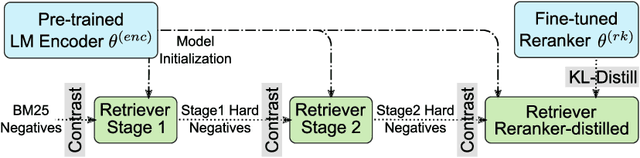
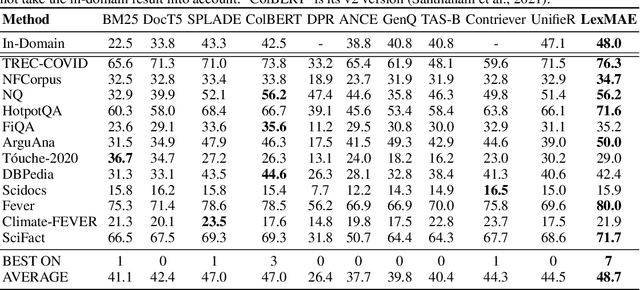
In large-scale retrieval, the lexicon-weighting paradigm, learning weighted sparse representations in vocabulary space, has shown promising results with high quality and low latency. Despite it deeply exploiting the lexicon-representing capability of pre-trained language models, a crucial gap remains between language modeling and lexicon-weighting retrieval -- the former preferring certain or low-entropy words whereas the latter favoring pivot or high-entropy words -- becoming the main barrier to lexicon-weighting performance for large-scale retrieval. To bridge this gap, we propose a brand-new pre-training framework, lexicon-bottlenecked masked autoencoder (LexMAE), to learn importance-aware lexicon representations. Essentially, we present a lexicon-bottlenecked module between a normal language modeling encoder and a weakened decoder, where a continuous bag-of-words bottleneck is constructed to learn a lexicon-importance distribution in an unsupervised fashion. The pre-trained LexMAE is readily transferred to the lexicon-weighting retrieval via fine-tuning, achieving 42.6\% MRR@10 with 45.83 QPS on a CPU machine for the passage retrieval benchmark, MS-Marco. And LexMAE shows state-of-the-art zero-shot transfer capability on BEIR benchmark with 12 datasets.