 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial-Contextual Discrepancy Information Compensation for GAN Inversion
Dec 12, 2023



Most existing GAN inversion methods either achieve accurate reconstruction but lack editability or offer strong editability at the cost of fidelity. Hence, how to balance the distortioneditability trade-off is a significant challenge for GAN inversion. To address this challenge, we introduce a novel spatial-contextual discrepancy information compensationbased GAN-inversion method (SDIC), which consists of a discrepancy information prediction network (DIPN) and a discrepancy information compensation network (DICN). SDIC follows a "compensate-and-edit" paradigm and successfully bridges the gap in image details between the original image and the reconstructed/edited image. On the one hand, DIPN encodes the multi-level spatial-contextual information of the original and initial reconstructed images and then predicts a spatial-contextual guided discrepancy map with two hourglass modules. In this way, a reliable discrepancy map that models the contextual relationship and captures finegrained image details is learned. On the other hand, DICN incorporates the predicted discrepancy information into both the latent code and the GAN generator with different transformations, generating high-quality reconstructed/edited images. This effectively compensates for the loss of image details during GAN inversion. Both quantitative and qualitative experiments demonstrate that our proposed method achieves the excellent distortion-editability trade-off at a fast inference speed for both image inversion and editing tasks.
VioLA: Unified Codec Language Models for Speech Recognition, Synthesis, and Translation
May 25, 2023



Recent research shows a big convergence in model architecture, training objectives, and inference methods across various tasks for different modalities. In this paper, we propose VioLA, a single auto-regressive Transformer decoder-only network that unifies various cross-modal tasks involving speech and text, such as speech-to-text, text-to-text, text-to-speech, and speech-to-speech tasks, as a conditional codec language model task via multi-task learning framework. To accomplish this, we first convert all the speech utterances to discrete tokens (similar to the textual data) using an offline neural codec encoder. In such a way, all these tasks are converted to token-based sequence conversion problems, which can be naturally handled with one conditional language model. We further integrate task IDs (TID) and language IDs (LID) into the proposed model to enhance the modeling capability of handling different languages and tasks. Experimental results demonstrate that the proposed VioLA model can support both single-modal and cross-modal tasks well, and the decoder-only model achieves a comparable and even better performance than the strong baselines.
Speak Foreign Languages with Your Own Voice: Cross-Lingual Neural Codec Language Modeling
Mar 07, 2023We propose a cross-lingual neural codec language model, VALL-E X, for cross-lingual speech synthesis. Specifically, we extend VALL-E and train a multi-lingual conditional codec language model to predict the acoustic token sequences of the target language speech by using both the source language speech and the target language text as prompts. VALL-E X inherits strong in-context learning capabilities and can be applied for zero-shot cross-lingual text-to-speech synthesis and zero-shot speech-to-speech translation tasks. Experimental results show that it can generate high-quality speech in the target language via just one speech utterance in the source language as a prompt while preserving the unseen speaker's voice, emotion, and acoustic environment. Moreover, VALL-E X effectively alleviates the foreign accent problems, which can be controlled by a language ID. Audio samples are available at \url{https://aka.ms/vallex}.
Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
Jan 05, 2023



We introduce a language modeling approach for text to speech synthesis (TTS). Specifically, we train a neural codec language model (called Vall-E) using discrete codes derived from an off-the-shelf neural audio codec model, and regard TTS as a conditional language modeling task rather than continuous signal regression as in previous work. During the pre-training stage, we scale up the TTS training data to 60K hours of English speech which is hundreds of times larger than existing systems. Vall-E emerges in-context learning capabilities and can be used to synthesize high-quality personalized speech with only a 3-second enrolled recording of an unseen speaker as an acoustic prompt. Experiment results show that Vall-E significantly outperforms the state-of-the-art zero-shot TTS system in terms of speech naturalness and speaker similarity. In addition, we find Vall-E could preserve the speaker's emotion and acoustic environment of the acoustic prompt in synthesis. See https://aka.ms/valle for demos of our work.
VATLM: Visual-Audio-Text Pre-Training with Unified Masked Prediction for Speech Representation Learning
Nov 21, 2022



Although speech is a simple and effective way for humans to communicate with the outside world, a more realistic speech interaction contains multimodal information, e.g., vision, text. How to design a unified framework to integrate different modal information and leverage different resources (e.g., visual-audio pairs, audio-text pairs, unlabeled speech, and unlabeled text) to facilitate speech representation learning was not well explored. In this paper, we propose a unified cross-modal representation learning framework VATLM (Visual-Audio-Text Language Model). The proposed VATLM employs a unified backbone network to model the modality-independent information and utilizes three simple modality-dependent modules to preprocess visual, speech, and text inputs. In order to integrate these three modalities into one shared semantic space, VATLM is optimized with a masked prediction task of unified tokens, given by our proposed unified tokenizer. We evaluate the pre-trained VATLM on audio-visual related downstream tasks, including audio-visual speech recognition (AVSR), visual speech recognition (VSR) tasks. Results show that the proposed VATLM outperforms previous the state-of-the-art models, such as audio-visual pre-trained AV-HuBERT model, and analysis also demonstrates that VATLM is capable of aligning different modalities into the same space. To facilitate future research, we release the code and pre-trained models at https://aka.ms/vatlm.
Joint Pre-Training with Speech and Bilingual Text for Direct Speech to Speech Translation
Oct 31, 2022



Direct speech-to-speech translation (S2ST) is an attractive research topic with many advantages compared to cascaded S2ST. However, direct S2ST suffers from the data scarcity problem because the corpora from speech of the source language to speech of the target language are very rare. To address this issue, we propose in this paper a Speech2S model, which is jointly pre-trained with unpaired speech and bilingual text data for direct speech-to-speech translation tasks. By effectively leveraging the paired text data, Speech2S is capable of modeling the cross-lingual speech conversion from source to target language. We verify the performance of the proposed Speech2S on Europarl-ST and VoxPopuli datasets. Experimental results demonstrate that Speech2S gets an improvement of about 5 BLEU scores compared to encoder-only pre-training models, and achieves a competitive or even better performance than existing state-of-the-art models1.
SpeechUT: Bridging Speech and Text with Hidden-Unit for Encoder-Decoder Based Speech-Text Pre-training
Oct 07, 2022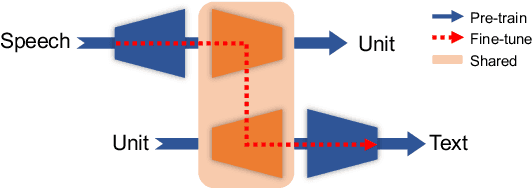
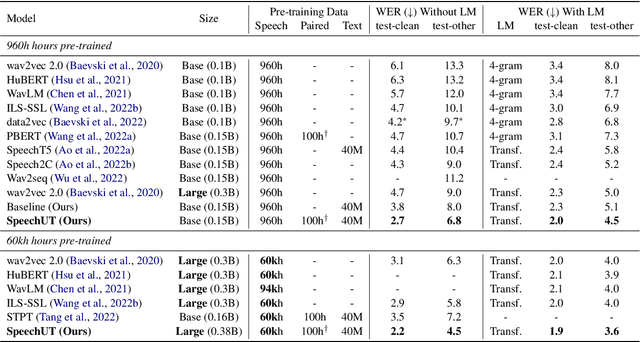
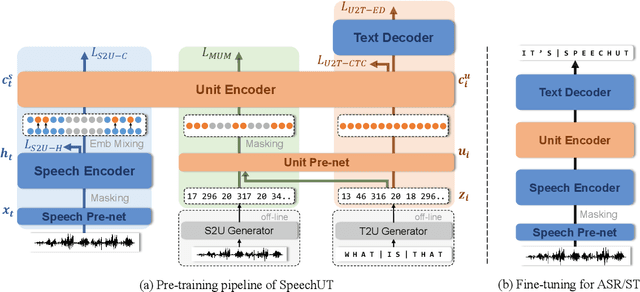
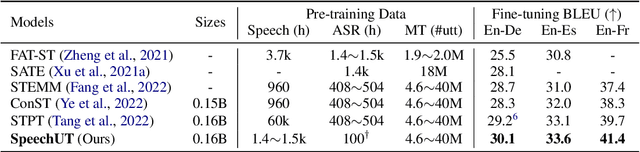
The rapid development of single-modal pre-training has prompted researchers to pay more attention to cross-modal pre-training methods. In this paper, we propose a unified-modal speech-unit-text pre-training model, SpeechUT, to connect the representations of a speech encoder and a text decoder with a shared unit encoder. Leveraging hidden-unit as an interface to align speech and text, we can decompose the speech-to-text model into a speech-to-unit model and a unit-to-text model, which can be jointly pre-trained with unpaired speech and text data respectively. Our proposed SpeechUT is fine-tuned and evaluated on automatic speech recognition (ASR) and speech translation (ST) tasks. Experimental results show that SpeechUT gets substantial improvements over strong baselines, and achieves state-of-the-art performance on both the LibriSpeech ASR and MuST-C ST tasks. To better understand the proposed SpeechUT, detailed analyses are conducted. The code and pre-trained models are available at https://aka.ms/SpeechUT.
SpeechLM: Enhanced Speech Pre-Training with Unpaired Textual Data
Sep 30, 2022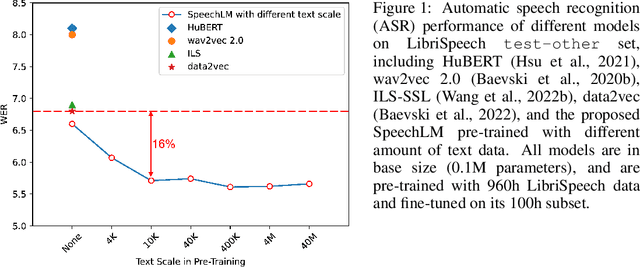
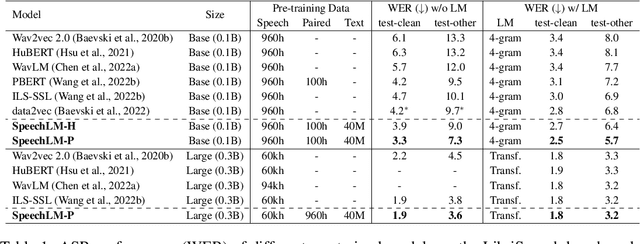
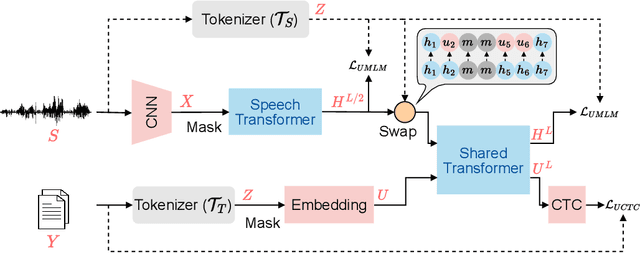
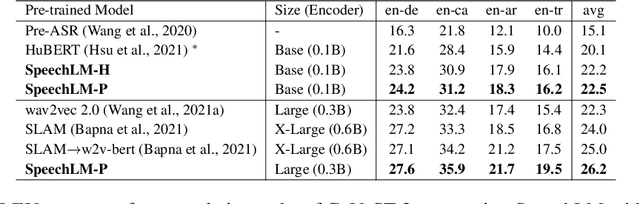
How to boost speech pre-training with textual data is an unsolved problem due to the fact that speech and text are very different modalities with distinct characteristics. In this paper, we propose a cross-modal Speech and Language Model (SpeechLM) to explicitly align speech and text pre-training with a pre-defined unified discrete representation. Specifically, we introduce two alternative discrete tokenizers to bridge the speech and text modalities, including phoneme-unit and hidden-unit tokenizers, which can be trained using a small amount of paired speech-text data. Based on the trained tokenizers, we convert the unlabeled speech and text data into tokens of phoneme units or hidden units. The pre-training objective is designed to unify the speech and the text into the same discrete semantic space with a unified Transformer network. Leveraging only 10K text sentences, our SpeechLM gets a 16\% relative WER reduction over the best base model performance (from 6.8 to 5.7) on the public LibriSpeech ASR benchmark. Moreover, SpeechLM with fewer parameters even outperforms previous SOTA models on CoVoST-2 speech translation tasks. We also evaluate our SpeechLM on various spoken language processing tasks under the universal representation evaluation framework SUPERB, demonstrating significant improvements on content-related tasks. Our code and models are available at https://aka.ms/SpeechLM.
The YiTrans End-to-End Speech Translation System for IWSLT 2022 Offline Shared Task
Jun 14, 2022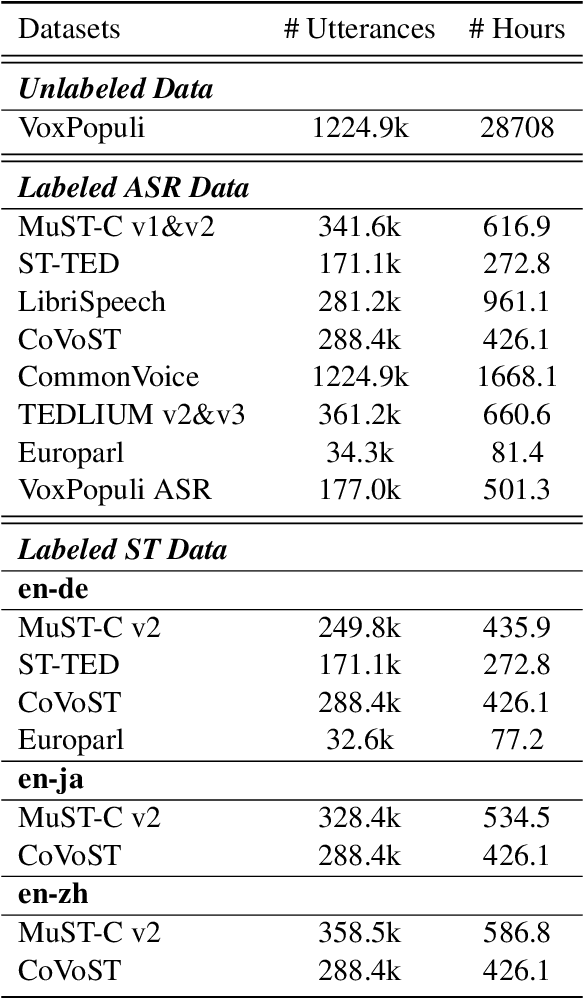
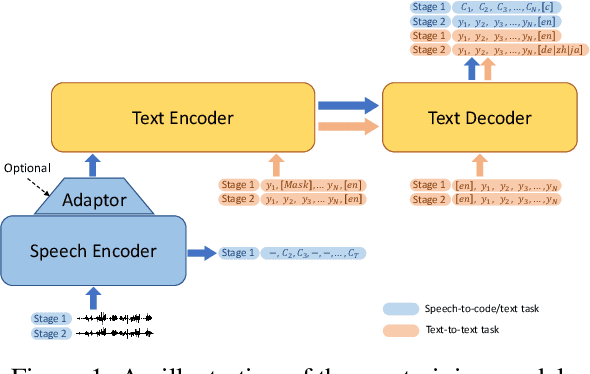
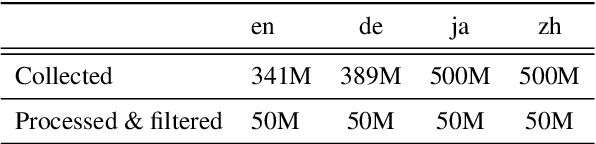
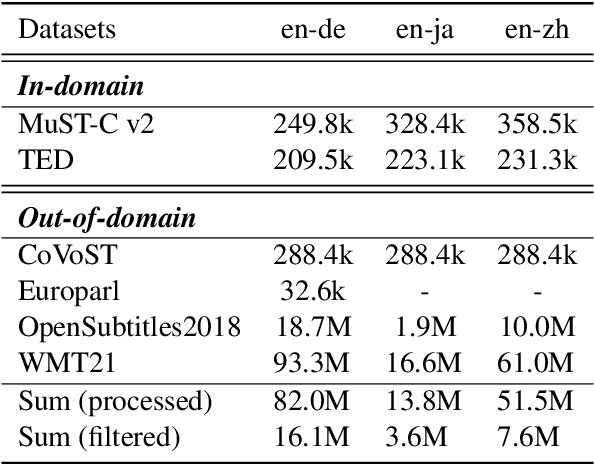
This paper describes the submission of our end-to-end YiTrans speech translation system for the IWSLT 2022 offline task, which translates from English audio to German, Chinese, and Japanese. The YiTrans system is built on large-scale pre-trained encoder-decoder models. More specifically, we first design a multi-stage pre-training strategy to build a multi-modality model with a large amount of labeled and unlabeled data. We then fine-tune the corresponding components of the model for the downstream speech translation tasks. Moreover, we make various efforts to improve performance, such as data filtering, data augmentation, speech segmentation, model ensemble, and so on. Experimental results show that our YiTrans system obtains a significant improvement than the strong baseline on three translation directions, and it achieves +5.2 BLEU improvements over last year's optimal end-to-end system on tst2021 English-German. Our final submissions rank first on English-German and English-Chinese end-to-end systems in terms of the automatic evaluation metric. We make our code and models publicly available.
Pre-Training Transformer Decoder for End-to-End ASR Model with Unpaired Speech Data
Mar 31, 2022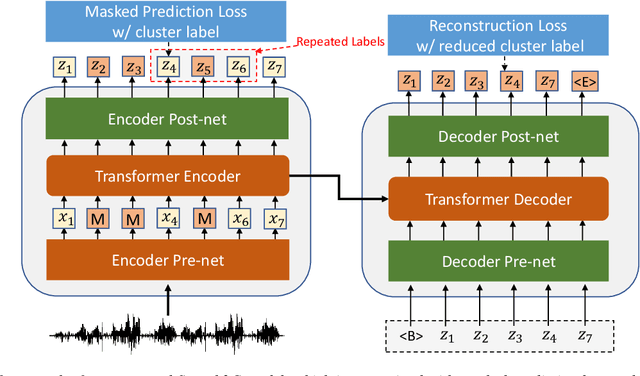
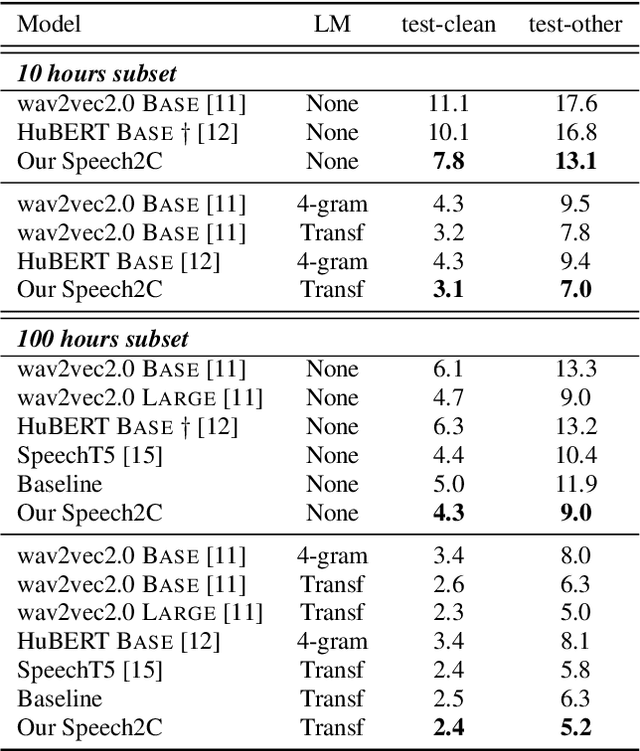

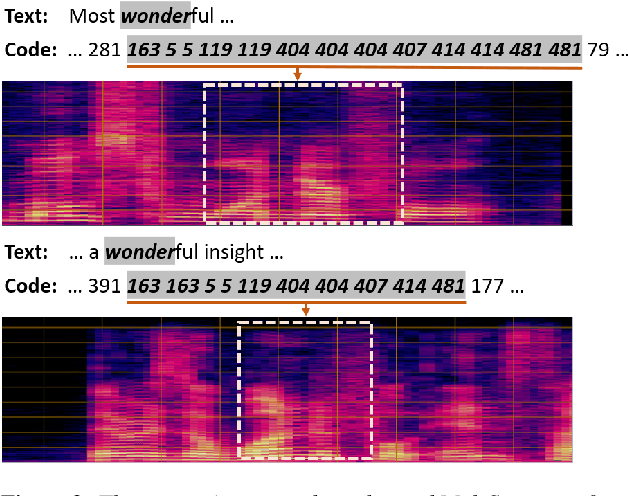
This paper studies a novel pre-training technique with unpaired speech data, Speech2C, for encoder-decoder based automatic speech recognition (ASR). Within a multi-task learning framework, we introduce two pre-training tasks for the encoder-decoder network using acoustic units, i.e., pseudo codes, derived from an offline clustering model. One is to predict the pseudo codes via masked language modeling in encoder output, like HuBERT model, while the other lets the decoder learn to reconstruct pseudo codes autoregressively instead of generating textual scripts. In this way, the decoder learns to reconstruct original speech information with codes before learning to generate correct text. Comprehensive experiments on the LibriSpeech corpus show that the proposed Speech2C can relatively reduce the word error rate (WER) by 19.2% over the method without decoder pre-training, and also outperforms significantly the state-of-the-art wav2vec 2.0 and HuBERT on fine-tuning subsets of 10h and 100h.