 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToolACE-MCP: Generalizing History-Aware Routing from MCP Tools to the Agent Web
Jan 13, 2026With the rise of the Agent Web and Model Context Protocol (MCP), the agent ecosystem is evolving into an open collaborative network, exponentially increasing accessible tools. However, current architectures face severe scalability and generality bottlenecks. To address this, we propose ToolACE-MCP, a pipeline for training history-aware routers to empower precise navigation in large-scale ecosystems. By leveraging a dependency-rich candidate Graph to synthesize multi-turn trajectories, we effectively train routers with dynamic context understanding to create the plug-and-play Light Routing Agent. Experiments on the real-world benchmarks MCP-Universe and MCP-Mark demonstrate superior performance. Notably, ToolACE-MCP exhibits critical properties for the future Agent Web: it not only generalizes to multi-agent collaboration with minimal adaptation but also maintains exceptional robustness against noise and scales effectively to massive candidate spaces. These findings provide a strong empirical foundation for universal orchestration in open-ended ecosystems.
Beyond Static Tools: Test-Time Tool Evolution for Scientific Reasoning
Jan 12, 2026The central challenge of AI for Science is not reasoning alone, but the ability to create computational methods in an open-ended scientific world. Existing LLM-based agents rely on static, pre-defined tool libraries, a paradigm that fundamentally fails in scientific domains where tools are sparse, heterogeneous, and intrinsically incomplete. In this paper, we propose Test-Time Tool Evolution (TTE), a new paradigm that enables agents to synthesize, verify, and evolve executable tools during inference. By transforming tools from fixed resources into problem-driven artifacts, TTE overcomes the rigidity and long-tail limitations of static tool libraries. To facilitate rigorous evaluation, we introduce SciEvo, a benchmark comprising 1,590 scientific reasoning tasks supported by 925 automatically evolved tools. Extensive experiments show that TTE achieves state-of-the-art performance in both accuracy and tool efficiency, while enabling effective cross-domain adaptation of computational tools. The code and benchmark have been released at https://github.com/lujiaxuan0520/Test-Time-Tool-Evol.
InstructMoLE: Instruction-Guided Mixture of Low-rank Experts for Multi-Conditional Image Generation
Dec 25, 2025Parameter-Efficient Fine-Tuning of Diffusion Transformers (DiTs) for diverse, multi-conditional tasks often suffers from task interference when using monolithic adapters like LoRA. The Mixture of Low-rank Experts (MoLE) architecture offers a modular solution, but its potential is usually limited by routing policies that operate at a token level. Such local routing can conflict with the global nature of user instructions, leading to artifacts like spatial fragmentation and semantic drift in complex image generation tasks. To address these limitations, we introduce InstructMoLE, a novel framework that employs an Instruction-Guided Mixture of Low-Rank Experts. Instead of per-token routing, InstructMoLE utilizes a global routing signal, Instruction-Guided Routing (IGR), derived from the user's comprehensive instruction. This ensures that a single, coherently chosen expert council is applied uniformly across all input tokens, preserving the global semantics and structural integrity of the generation process. To complement this, we introduce an output-space orthogonality loss, which promotes expert functional diversity and mitigates representational collapse. Extensive experiments demonstrate that InstructMoLE significantly outperforms existing LoRA adapters and MoLE variants across challenging multi-conditional generation benchmarks. Our work presents a robust and generalizable framework for instruction-driven fine-tuning of generative models, enabling superior compositional control and fidelity to user intent.
Reasoning via Video: The First Evaluation of Video Models' Reasoning Abilities through Maze-Solving Tasks
Nov 19, 2025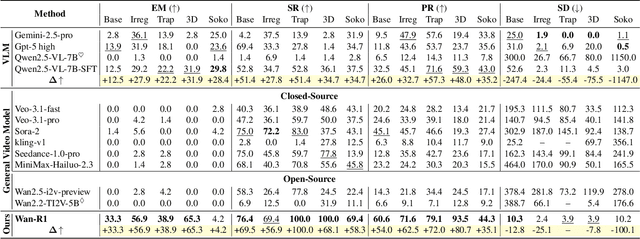

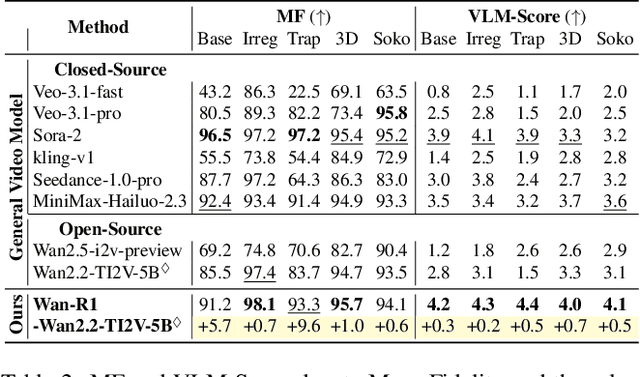
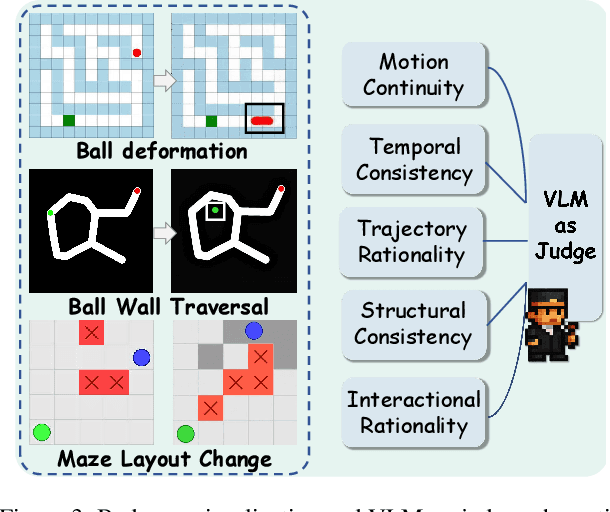
Video Models have achieved remarkable success in high-fidelity video generation with coherent motion dynamics. Analogous to the development from text generation to text-based reasoning in language modeling, the development of video models motivates us to ask: Can video models reason via video generation? Compared with the discrete text corpus, video grounds reasoning in explicit spatial layouts and temporal continuity, which serves as an ideal substrate for spatial reasoning. In this work, we explore the reasoning via video paradigm and introduce VR-Bench -- a comprehensive benchmark designed to systematically evaluate video models' reasoning capabilities. Grounded in maze-solving tasks that inherently require spatial planning and multi-step reasoning, VR-Bench contains 7,920 procedurally generated videos across five maze types and diverse visual styles. Our empirical analysis demonstrates that SFT can efficiently elicit the reasoning ability of video model. Video models exhibit stronger spatial perception during reasoning, outperforming leading VLMs and generalizing well across diverse scenarios, tasks, and levels of complexity. We further discover a test-time scaling effect, where diverse sampling during inference improves reasoning reliability by 10--20%. These findings highlight the unique potential and scalability of reasoning via video for spatial reasoning tasks.
EcoSpa: Efficient Transformer Training with Coupled Sparsity
Nov 09, 2025Transformers have become the backbone of modern AI, yet their high computational demands pose critical system challenges. While sparse training offers efficiency gains, existing methods fail to preserve critical structural relationships between weight matrices that interact multiplicatively in attention and feed-forward layers. This oversight leads to performance degradation at high sparsity levels. We introduce EcoSpa, an efficient structured sparse training method that jointly evaluates and sparsifies coupled weight matrix pairs, preserving their interaction patterns through aligned row/column removal. EcoSpa introduces a new granularity for calibrating structural component importance and performs coupled estimation and sparsification across both pre-training and fine-tuning scenarios. Evaluations demonstrate substantial improvements: EcoSpa enables efficient training of LLaMA-1B with 50\% memory reduction and 21\% faster training, achieves $2.2\times$ model compression on GPT-2-Medium with $2.4$ lower perplexity, and delivers $1.6\times$ inference speedup. The approach uses standard PyTorch operations, requiring no custom hardware or kernels, making efficient transformer training accessible on commodity hardware.
A Survey on Deep Text Hashing: Efficient Semantic Text Retrieval with Binary Representation
Oct 31, 2025



With the rapid growth of textual content on the Internet, efficient large-scale semantic text retrieval has garnered increasing attention from both academia and industry. Text hashing, which projects original texts into compact binary hash codes, is a crucial method for this task. By using binary codes, the semantic similarity computation for text pairs is significantly accelerated via fast Hamming distance calculations, and storage costs are greatly reduced. With the advancement of deep learning, deep text hashing has demonstrated significant advantages over traditional, data-independent hashing techniques. By leveraging deep neural networks, these methods can learn compact and semantically rich binary representations directly from data, overcoming the performance limitations of earlier approaches. This survey investigates current deep text hashing methods by categorizing them based on their core components: semantic extraction, hash code quality preservation, and other key technologies. We then present a detailed evaluation schema with results on several popular datasets, followed by a discussion of practical applications and open-source tools for implementation. Finally, we conclude by discussing key challenges and future research directions, including the integration of deep text hashing with large language models to further advance the field. The project for this survey can be accessed at https://github.com/hly1998/DeepTextHashing.
Learning on the Job: An Experience-Driven Self-Evolving Agent for Long-Horizon Tasks
Oct 09, 2025Large Language Models have demonstrated remarkable capabilities across diverse domains, yet significant challenges persist when deploying them as AI agents for real-world long-horizon tasks. Existing LLM agents suffer from a critical limitation: they are test-time static and cannot learn from experience, lacking the ability to accumulate knowledge and continuously improve on the job. To address this challenge, we propose MUSE, a novel agent framework that introduces an experience-driven, self-evolving system centered around a hierarchical Memory Module. MUSE organizes diverse levels of experience and leverages them to plan and execute long-horizon tasks across multiple applications. After each sub-task execution, the agent autonomously reflects on its trajectory, converting the raw trajectory into structured experience and integrating it back into the Memory Module. This mechanism enables the agent to evolve beyond its static pretrained parameters, fostering continuous learning and self-evolution. We evaluate MUSE on the long-horizon productivity benchmark TAC. It achieves new SOTA performance by a significant margin using only a lightweight Gemini-2.5 Flash model. Sufficient Experiments demonstrate that as the agent autonomously accumulates experience, it exhibits increasingly superior task completion capabilities, as well as robust continuous learning and self-evolution capabilities. Moreover, the accumulated experience from MUSE exhibits strong generalization properties, enabling zero-shot improvement on new tasks. MUSE establishes a new paradigm for AI agents capable of real-world productivity task automation.
Brain-HGCN: A Hyperbolic Graph Convolutional Network for Brain Functional Network Analysis
Sep 18, 2025Functional magnetic resonance imaging (fMRI) provides a powerful non-invasive window into the brain's functional organization by generating complex functional networks, typically modeled as graphs. These brain networks exhibit a hierarchical topology that is crucial for cognitive processing. However, due to inherent spatial constraints, standard Euclidean GNNs struggle to represent these hierarchical structures without high distortion, limiting their clinical performance. To address this limitation, we propose Brain-HGCN, a geometric deep learning framework based on hyperbolic geometry, which leverages the intrinsic property of negatively curved space to model the brain's network hierarchy with high fidelity. Grounded in the Lorentz model, our model employs a novel hyperbolic graph attention layer with a signed aggregation mechanism to distinctly process excitatory and inhibitory connections, ultimately learning robust graph-level representations via a geometrically sound Fr\'echet mean for graph readout. Experiments on two large-scale fMRI datasets for psychiatric disorder classification demonstrate that our approach significantly outperforms a wide range of state-of-the-art Euclidean baselines. This work pioneers a new geometric deep learning paradigm for fMRI analysis, highlighting the immense potential of hyperbolic GNNs in the field of computational psychiatry.
Small Lesions-aware Bidirectional Multimodal Multiscale Fusion Network for Lung Disease Classification
Aug 06, 2025



The diagnosis of medical diseases faces challenges such as the misdiagnosis of small lesions. Deep learning, particularly multimodal approaches, has shown great potential in the field of medical disease diagnosis. However, the differences in dimensionality between medical imaging and electronic health record data present challenges for effective alignment and fusion. To address these issues, we propose the Multimodal Multiscale Cross-Attention Fusion Network (MMCAF-Net). This model employs a feature pyramid structure combined with an efficient 3D multi-scale convolutional attention module to extract lesion-specific features from 3D medical images. To further enhance multimodal data integration, MMCAF-Net incorporates a multi-scale cross-attention module, which resolves dimensional inconsistencies, enabling more effective feature fusion. We evaluated MMCAF-Net on the Lung-PET-CT-Dx dataset, and the results showed a significant improvement in diagnostic accuracy, surpassing current state-of-the-art methods. The code is available at https://github.com/yjx1234/MMCAF-Net
Masked Language Models are Good Heterogeneous Graph Generalizers
Jun 06, 2025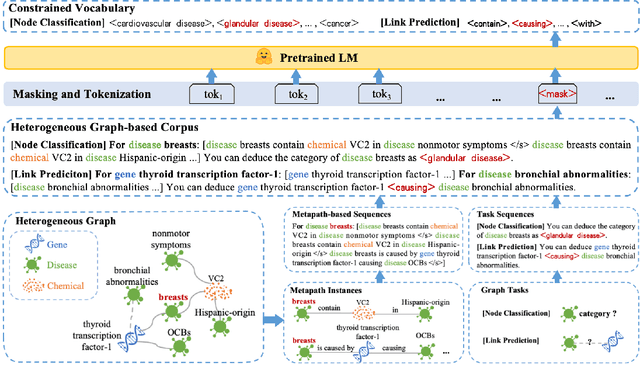
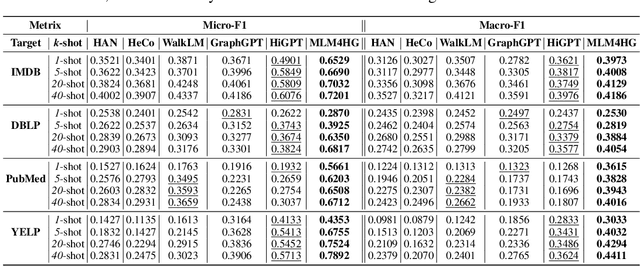
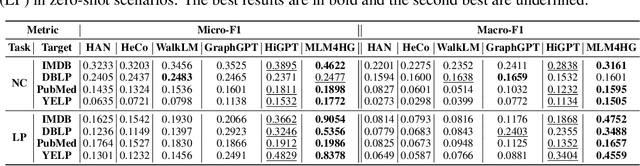
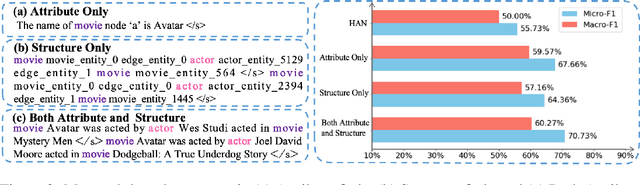
Heterogeneous graph neural networks (HGNNs) excel at capturing structural and semantic information in heterogeneous graphs (HGs), while struggling to generalize across domains and tasks. Recently, some researchers have turned to integrating HGNNs with large language models (LLMs) for more generalizable heterogeneous graph learning. However, these approaches typically extract structural information via HGNNs as HG tokens, and disparities in embedding spaces between HGNNs and LLMs have been shown to bias the LLM's comprehension of HGs. Moreover, as these HG tokens are often derived from node-level tasks, the model's ability to generalize across tasks remains limited. To this end, we propose a simple yet effective Masked Language Modeling-based method, called MLM4HG. MLM4HG introduces metapath-based textual sequences instead of HG tokens to extract structural and semantic information inherent in HGs, and designs customized textual templates to unify different graph tasks into a coherent cloze-style "mask" token prediction paradigm. Specifically, MLM4HG first converts HGs from various domains to texts based on metapaths, and subsequently combines them with the unified task texts to form a HG-based corpus. Moreover, the corpus is fed into a pretrained LM for fine-tuning with a constrained target vocabulary, enabling the fine-tuned LM to generalize to unseen target HGs. Extensive cross-domain and multi-task experiments on four real-world datasets demonstrate the superior generalization performance of MLM4HG over state-of-the-art methods in both few-shot and zero-shot scenarios. Our code is available at https://github.com/BUPT-GAMMA/MLM4HG.