 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabBuilder: Protocol-Grounded 3D Layout Generation for Interactable and Safe Laboratory
May 04, 2026Automated laboratories hold the promise of accelerating scientific discovery, yet their deployment is bottlenecked by the difficulty of designing safe and executable environments. While simulator-based design offers scalability, existing 3D scene generation methods are primarily tailored for household settings, optimizing for visual plausibility while neglecting the rigorous functional semantics and safety constraints essential for scientific experimentation. We present LabBuilder, an end-to-end system that generates and verifies 3D laboratory layouts from concise textual specifications. It operates through three tightly coupled components: LabForge first curates a meta-dataset of annotated assets and chemical knowledge, translating natural language specifications into structured protocols; building on these protocols, LabGen synthesizes laboratory layouts via an iterative, constraint-aware optimization strategy; finally, LabTouchstone evaluates the resulting layouts as a unified benchmark. Extensive experiments demonstrate that LabBuilder significantly outperforms existing state-of-the-art methods, producing laboratory environments that are not only realistic but also functionally valid and safe for complex experimental workflows.
P1-VL: Bridging Visual Perception and Scientific Reasoning in Physics Olympiads
Feb 10, 2026The transition from symbolic manipulation to science-grade reasoning represents a pivotal frontier for Large Language Models (LLMs), with physics serving as the critical test anchor for binding abstract logic to physical reality. Physics demands that a model maintain physical consistency with the laws governing the universe, a task that fundamentally requires multimodal perception to ground abstract logic in reality. At the Olympiad level, diagrams are often constitutive rather than illustrative, containing essential constraints, such as boundary conditions and spatial symmetries, that are absent from the text. To bridge this visual-logical gap, we introduce P1-VL, a family of open-source vision-language models engineered for advanced scientific reasoning. Our method harmonizes Curriculum Reinforcement Learning, which employs progressive difficulty expansion to stabilize post-training, with Agentic Augmentation, enabling iterative self-verification at inference. Evaluated on HiPhO, a rigorous benchmark of 13 exams from 2024-2025, our flagship P1-VL-235B-A22B becomes the first open-source Vision-Language Model (VLM) to secure 12 gold medals and achieves the state-of-the-art performance in the open-source models. Our agent-augmented system achieves the No.2 overall rank globally, trailing only Gemini-3-Pro. Beyond physics, P1-VL demonstrates remarkable scientific reasoning capacity and generalizability, establishing significant leads over base models in STEM benchmarks. By open-sourcing P1-VL, we provide a foundational step toward general-purpose physical intelligence to better align visual perceptions with abstract physical laws for machine scientific discovery.
SDFLoRA: Selective Decoupled Federated LoRA for Privacy-preserving Fine-tuning with Heterogeneous Clients
Jan 29, 2026Federated learning (FL) for large language models (LLMs) has attracted increasing attention as a privacy-preserving approach for adapting models over distributed data, where parameter-efficient methods such as Low-Rank Adaptation (LoRA) are widely adopted to reduce communication and memory costs. However, practical deployments often exhibit rank and data heterogeneity: clients operate under different low-rank budgets and data distributions, making direct aggregation of LoRA updates biased and unstable. Existing approaches either enforce a unified rank or align heterogeneous updates into a single shared subspace, which tends to mix transferable and client-specific directions and consequently undermines personalization. Moreover, under differential privacy (DP), perturbing such structurally mixed updates injects noise into directions that should remain purely local, leading to unnecessary utility degradation. To address these issues, we propose Selective Decoupled Federated LoRA (SDFLoRA), a structure-aware LoRA framework that decouples each client update into a shared component for aggregation and a private component that preserves client-specific semantics. Only the shared component participates in subspace alignment, while the private component remains local and uncommunicated, making the training DP-compatible and stabilizing aggregation under rank heterogeneity. By injecting noise only into the aggregated shareable update, this approach avoids perturbations to local directions and improves the utility-privacy trade-off. Experiments on multiple benchmarks demonstrate that SDFLoRA outperforms federated LoRA baselines and achieves a strong utility-privacy trade-off.
SDFLoRA: Selective Dual-Module LoRA for Federated Fine-tuning with Heterogeneous Clients
Jan 16, 2026Federated learning (FL) for large language models (LLMs) has attracted increasing attention as a way to enable privacy-preserving adaptation over distributed data. Parameter-efficient methods such as LoRA are widely adopted to reduce communication and memory costs. Despite these advances, practical FL deployments often exhibit rank heterogeneity, since different clients may use different low-rank configurations. This makes direct aggregation of LoRA updates biased and unstable. Existing solutions typically enforce unified ranks or align heterogeneous updates into a shared subspace, which over-constrains client-specific semantics, limits personalization, and provides weak protection of local client information under differential privacy noise. To address this issue, we propose Selective Dual-module Federated LoRA (SDFLoRA), which decomposes each client adapter into a global module that captures transferable knowledge and a local module that preserves client-specific adaptations. The global module is selectively aligned and aggregated across clients, while local modules remain private. This design enables robust learning under rank heterogeneity and supports privacy-aware optimization by injecting differential privacy noise exclusively into the global module. Experiments on GLUE benchmarks demonstrate that SDFLoRA outperforms representative federated LoRA baselines and achieves a better utility-privacy trade-off.
Beyond Static Tools: Test-Time Tool Evolution for Scientific Reasoning
Jan 12, 2026The central challenge of AI for Science is not reasoning alone, but the ability to create computational methods in an open-ended scientific world. Existing LLM-based agents rely on static, pre-defined tool libraries, a paradigm that fundamentally fails in scientific domains where tools are sparse, heterogeneous, and intrinsically incomplete. In this paper, we propose Test-Time Tool Evolution (TTE), a new paradigm that enables agents to synthesize, verify, and evolve executable tools during inference. By transforming tools from fixed resources into problem-driven artifacts, TTE overcomes the rigidity and long-tail limitations of static tool libraries. To facilitate rigorous evaluation, we introduce SciEvo, a benchmark comprising 1,590 scientific reasoning tasks supported by 925 automatically evolved tools. Extensive experiments show that TTE achieves state-of-the-art performance in both accuracy and tool efficiency, while enabling effective cross-domain adaptation of computational tools. The code and benchmark have been released at https://github.com/lujiaxuan0520/Test-Time-Tool-Evol.
Reasoning via Video: The First Evaluation of Video Models' Reasoning Abilities through Maze-Solving Tasks
Nov 19, 2025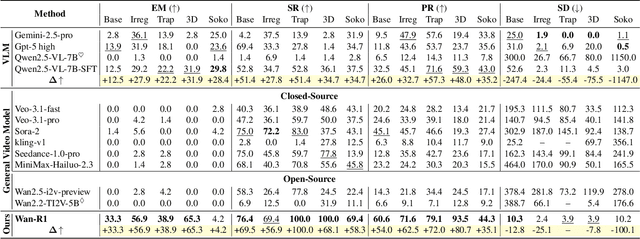

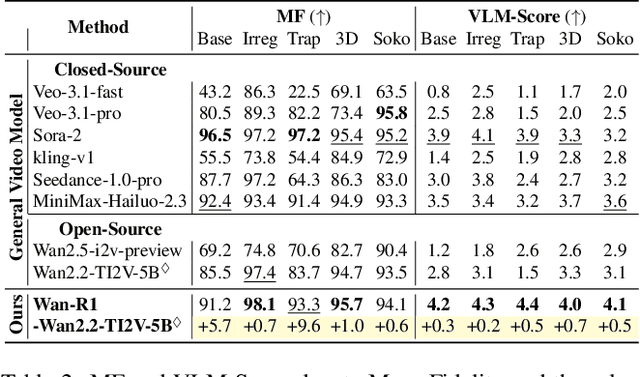
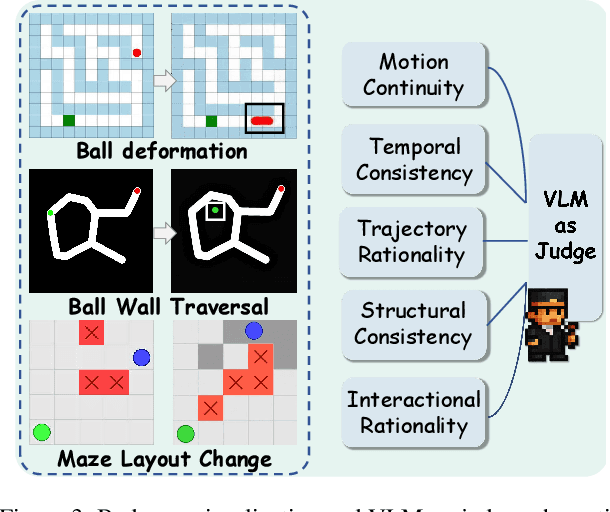
Video Models have achieved remarkable success in high-fidelity video generation with coherent motion dynamics. Analogous to the development from text generation to text-based reasoning in language modeling, the development of video models motivates us to ask: Can video models reason via video generation? Compared with the discrete text corpus, video grounds reasoning in explicit spatial layouts and temporal continuity, which serves as an ideal substrate for spatial reasoning. In this work, we explore the reasoning via video paradigm and introduce VR-Bench -- a comprehensive benchmark designed to systematically evaluate video models' reasoning capabilities. Grounded in maze-solving tasks that inherently require spatial planning and multi-step reasoning, VR-Bench contains 7,920 procedurally generated videos across five maze types and diverse visual styles. Our empirical analysis demonstrates that SFT can efficiently elicit the reasoning ability of video model. Video models exhibit stronger spatial perception during reasoning, outperforming leading VLMs and generalizing well across diverse scenarios, tasks, and levels of complexity. We further discover a test-time scaling effect, where diverse sampling during inference improves reasoning reliability by 10--20%. These findings highlight the unique potential and scalability of reasoning via video for spatial reasoning tasks.
P1: Mastering Physics Olympiads with Reinforcement Learning
Nov 17, 2025Recent progress in large language models (LLMs) has moved the frontier from puzzle-solving to science-grade reasoning-the kind needed to tackle problems whose answers must stand against nature, not merely fit a rubric. Physics is the sharpest test of this shift, which binds symbols to reality in a fundamental way, serving as the cornerstone of most modern technologies. In this work, we manage to advance physics research by developing large language models with exceptional physics reasoning capabilities, especially excel at solving Olympiad-level physics problems. We introduce P1, a family of open-source physics reasoning models trained entirely through reinforcement learning (RL). Among them, P1-235B-A22B is the first open-source model with Gold-medal performance at the latest International Physics Olympiad (IPhO 2025), and wins 12 gold medals out of 13 international/regional physics competitions in 2024/2025. P1-30B-A3B also surpasses almost all other open-source models on IPhO 2025, getting a silver medal. Further equipped with an agentic framework PhysicsMinions, P1-235B-A22B+PhysicsMinions achieves overall No.1 on IPhO 2025, and obtains the highest average score over the 13 physics competitions. Besides physics, P1 models also present great performance on other reasoning tasks like math and coding, showing the great generalibility of P1 series.
RECALL: REpresentation-aligned Catastrophic-forgetting ALLeviation via Hierarchical Model Merging
Oct 23, 2025We unveil that internal representations in large language models (LLMs) serve as reliable proxies of learned knowledge, and propose RECALL, a novel representation-aware model merging framework for continual learning without access to historical data. RECALL computes inter-model similarity from layer-wise hidden representations over clustered typical samples, and performs adaptive, hierarchical parameter fusion to align knowledge across models. This design enables the preservation of domain-general features in shallow layers while allowing task-specific adaptation in deeper layers. Unlike prior methods that require task labels or incur performance trade-offs, RECALL achieves seamless multi-domain integration and strong resistance to catastrophic forgetting. Extensive experiments across five NLP tasks and multiple continual learning scenarios show that RECALL outperforms baselines in both knowledge retention and generalization, providing a scalable and data-free solution for evolving LLMs.
HiPhO: How Far Are (M)LLMs from Humans in the Latest High School Physics Olympiad Benchmark?
Sep 10, 2025



Recently, the physical capabilities of (M)LLMs have garnered increasing attention. However, existing benchmarks for physics suffer from two major gaps: they neither provide systematic and up-to-date coverage of real-world physics competitions such as physics Olympiads, nor enable direct performance comparison with humans. To bridge these gaps, we present HiPhO, the first benchmark dedicated to high school physics Olympiads with human-aligned evaluation. Specifically, HiPhO highlights three key innovations. (1) Comprehensive Data: It compiles 13 latest Olympiad exams from 2024-2025, spanning both international and regional competitions, and covering mixed modalities that encompass problems spanning text-only to diagram-based. (2) Professional Evaluation: We adopt official marking schemes to perform fine-grained grading at both the answer and step level, fully aligned with human examiners to ensure high-quality and domain-specific evaluation. (3) Comparison with Human Contestants: We assign gold, silver, and bronze medals to models based on official medal thresholds, thereby enabling direct comparison between (M)LLMs and human contestants. Our large-scale evaluation of 30 state-of-the-art (M)LLMs shows that: across 13 exams, open-source MLLMs mostly remain at or below the bronze level; open-source LLMs show promising progress with occasional golds; closed-source reasoning MLLMs can achieve 6 to 12 gold medals; and most models still have a significant gap from full marks. These results highlight a substantial performance gap between open-source models and top students, the strong physical reasoning capabilities of closed-source reasoning models, and the fact that there is still significant room for improvement. HiPhO, as a rigorous, human-aligned, and Olympiad-focused benchmark for advancing multimodal physical reasoning, is open-source and available at https://github.com/SciYu/HiPhO.
Spotlight Attention: Towards Efficient LLM Generation via Non-linear Hashing-based KV Cache Retrieval
Aug 27, 2025



Reducing the key-value (KV) cache burden in Large Language Models (LLMs) significantly accelerates inference. Dynamically selecting critical KV caches during decoding helps maintain performance. Existing methods use random linear hashing to identify important tokens, but this approach is inefficient due to the orthogonal distribution of queries and keys within two narrow cones in LLMs. We introduce Spotlight Attention, a novel method that employs non-linear hashing functions to optimize the embedding distribution of queries and keys, enhancing coding efficiency and robustness. We also developed a lightweight, stable training framework using a Bradley-Terry ranking-based loss, enabling optimization of the non-linear hashing module on GPUs with 16GB memory in 8 hours. Experimental results show that Spotlight Attention drastically improves retrieval precision while shortening the length of the hash code at least 5$\times$ compared to traditional linear hashing. Finally, we exploit the computational advantages of bitwise operations by implementing specialized CUDA kernels, achieving hashing retrieval for 512K tokens in under 100$\mu$s on a single A100 GPU, with end-to-end throughput up to 3$\times$ higher than vanilla decoding.