 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Tokenization for Bridging Graphs and Transformers
Mar 11, 2026The success of large pretrained Transformers is closely tied to tokenizers, which convert raw input into discrete symbols. Extending these models to graph-structured data remains a significant challenge. In this work, we introduce a graph tokenization framework that generates sequential representations of graphs by combining reversible graph serialization, which preserves graph information, with Byte Pair Encoding (BPE), a widely adopted tokenizer in large language models (LLMs). To better capture structural information, the graph serialization process is guided by global statistics of graph substructures, ensuring that frequently occurring substructures appear more often in the sequence and can be merged by BPE into meaningful tokens. Empirical results demonstrate that the proposed tokenizer enables Transformers such as BERT to be directly applied to graph benchmarks without architectural modifications. The proposed approach achieves state-of-the-art results on 14 benchmark datasets and frequently outperforms both graph neural networks and specialized graph transformers. This work bridges the gap between graph-structured data and the ecosystem of sequence models. Our code is available at \href{https://github.com/BUPT-GAMMA/Graph-Tokenization-for-Bridging-Graphs-and-Transformers}{\color{blue}here}.
Masked Language Models are Good Heterogeneous Graph Generalizers
Jun 06, 2025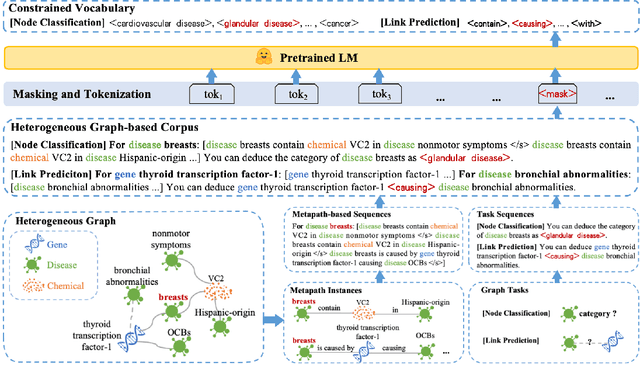
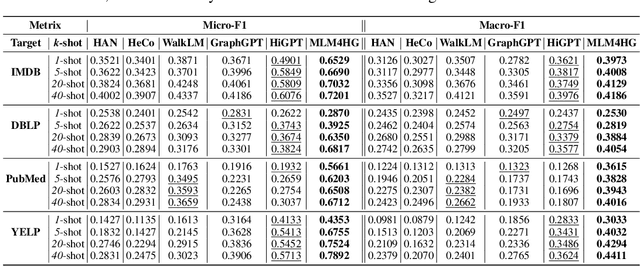
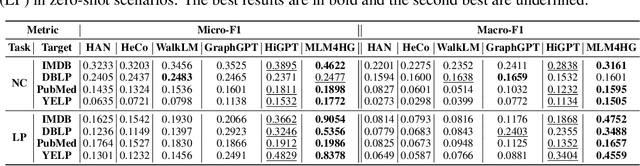
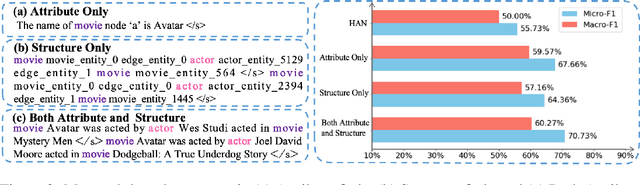
Heterogeneous graph neural networks (HGNNs) excel at capturing structural and semantic information in heterogeneous graphs (HGs), while struggling to generalize across domains and tasks. Recently, some researchers have turned to integrating HGNNs with large language models (LLMs) for more generalizable heterogeneous graph learning. However, these approaches typically extract structural information via HGNNs as HG tokens, and disparities in embedding spaces between HGNNs and LLMs have been shown to bias the LLM's comprehension of HGs. Moreover, as these HG tokens are often derived from node-level tasks, the model's ability to generalize across tasks remains limited. To this end, we propose a simple yet effective Masked Language Modeling-based method, called MLM4HG. MLM4HG introduces metapath-based textual sequences instead of HG tokens to extract structural and semantic information inherent in HGs, and designs customized textual templates to unify different graph tasks into a coherent cloze-style "mask" token prediction paradigm. Specifically, MLM4HG first converts HGs from various domains to texts based on metapaths, and subsequently combines them with the unified task texts to form a HG-based corpus. Moreover, the corpus is fed into a pretrained LM for fine-tuning with a constrained target vocabulary, enabling the fine-tuned LM to generalize to unseen target HGs. Extensive cross-domain and multi-task experiments on four real-world datasets demonstrate the superior generalization performance of MLM4HG over state-of-the-art methods in both few-shot and zero-shot scenarios. Our code is available at https://github.com/BUPT-GAMMA/MLM4HG.