 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Image Zoom-in with Bounding Box Transformation for UAV Object Detection
Feb 07, 2026Detecting objects from UAV-captured images is challenging due to the small object size. In this work, a simple and efficient adaptive zoom-in framework is explored for object detection on UAV images. The main motivation is that the foreground objects are generally smaller and sparser than those in common scene images, which hinders the optimization of effective object detectors. We thus aim to zoom in adaptively on the objects to better capture object features for the detection task. To achieve the goal, two core designs are required: \textcolor{black}{i) How to conduct non-uniform zooming on each image efficiently? ii) How to enable object detection training and inference with the zoomed image space?} Correspondingly, a lightweight offset prediction scheme coupled with a novel box-based zooming objective is introduced to learn non-uniform zooming on the input image. Based on the learned zooming transformation, a corner-aligned bounding box transformation method is proposed. The method warps the ground-truth bounding boxes to the zoomed space to learn object detection, and warps the predicted bounding boxes back to the original space during inference. We conduct extensive experiments on three representative UAV object detection datasets, including VisDrone, UAVDT, and SeaDronesSee. The proposed ZoomDet is architecture-independent and can be applied to an arbitrary object detection architecture. Remarkably, on the SeaDronesSee dataset, ZoomDet offers more than 8.4 absolute gain of mAP with a Faster R-CNN model, with only about 3 ms additional latency. The code is available at https://github.com/twangnh/zoomdet_code.
Small Lesions-aware Bidirectional Multimodal Multiscale Fusion Network for Lung Disease Classification
Aug 06, 2025



The diagnosis of medical diseases faces challenges such as the misdiagnosis of small lesions. Deep learning, particularly multimodal approaches, has shown great potential in the field of medical disease diagnosis. However, the differences in dimensionality between medical imaging and electronic health record data present challenges for effective alignment and fusion. To address these issues, we propose the Multimodal Multiscale Cross-Attention Fusion Network (MMCAF-Net). This model employs a feature pyramid structure combined with an efficient 3D multi-scale convolutional attention module to extract lesion-specific features from 3D medical images. To further enhance multimodal data integration, MMCAF-Net incorporates a multi-scale cross-attention module, which resolves dimensional inconsistencies, enabling more effective feature fusion. We evaluated MMCAF-Net on the Lung-PET-CT-Dx dataset, and the results showed a significant improvement in diagnostic accuracy, surpassing current state-of-the-art methods. The code is available at https://github.com/yjx1234/MMCAF-Net
Knowledgeable-r1: Policy Optimization for Knowledge Exploration in Retrieval-Augmented Generation
Jun 05, 2025

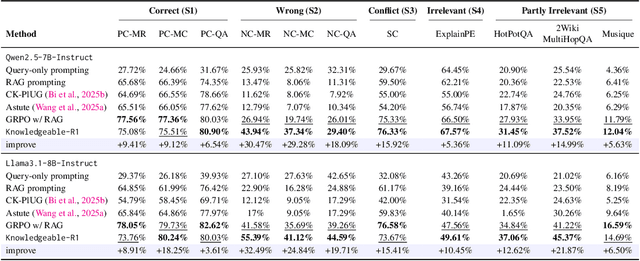

Retrieval-augmented generation (RAG) is a mainstream method for improving performance on knowledge-intensive tasks. However,current RAG systems often place too much emphasis on retrieved contexts. This can lead to reliance on inaccurate sources and overlook the model's inherent knowledge, especially when dealing with misleading or excessive information. To resolve this imbalance, we propose Knowledgeable-r1 that using joint sampling and define multi policy distributions in knowledge capability exploration to stimulate large language models'self-integrated utilization of parametric and contextual knowledge. Experiments show that Knowledgeable-r1 significantly enhances robustness and reasoning accuracy in both parameters and contextual conflict tasks and general RAG tasks, especially outperforming baselines by 17.07% in counterfactual scenarios and demonstrating consistent gains across RAG tasks. Our code are available at https://github.com/lcy80366872/ knowledgeable-r1.
Fine-tuning Quantized Neural Networks with Zeroth-order Optimization
May 19, 2025As the size of large language models grows exponentially, GPU memory has become a bottleneck for adapting these models to downstream tasks. In this paper, we aim to push the limits of memory-efficient training by minimizing memory usage on model weights, gradients, and optimizer states, within a unified framework. Our idea is to eliminate both gradients and optimizer states using zeroth-order optimization, which approximates gradients by perturbing weights during forward passes to identify gradient directions. To minimize memory usage on weights, we employ model quantization, e.g., converting from bfloat16 to int4. However, directly applying zeroth-order optimization to quantized weights is infeasible due to the precision gap between discrete weights and continuous gradients, which would otherwise require de-quantization and re-quantization. To overcome this challenge, we propose Quantized Zeroth-order Optimization (QZO), a novel approach that perturbs the continuous quantization scale for gradient estimation and uses a directional derivative clipping method to stabilize training. QZO is orthogonal to both scalar-based and codebook-based post-training quantization methods. Compared to full-parameter fine-tuning in bfloat16, QZO can reduce the total memory cost by more than 18$\times$ for 4-bit LLMs, and enables fine-tuning Llama-2-13B and Stable Diffusion 3.5 Large within a single 24GB GPU.
Cross-Modal Interactive Perception Network with Mamba for Lung Tumor Segmentation in PET-CT Images
Mar 21, 2025



Lung cancer is a leading cause of cancer-related deaths globally. PET-CT is crucial for imaging lung tumors, providing essential metabolic and anatomical information, while it faces challenges such as poor image quality, motion artifacts, and complex tumor morphology. Deep learning-based models are expected to address these problems, however, existing small-scale and private datasets limit significant performance improvements for these methods. Hence, we introduce a large-scale PET-CT lung tumor segmentation dataset, termed PCLT20K, which comprises 21,930 pairs of PET-CT images from 605 patients. Furthermore, we propose a cross-modal interactive perception network with Mamba (CIPA) for lung tumor segmentation in PET-CT images. Specifically, we design a channel-wise rectification module (CRM) that implements a channel state space block across multi-modal features to learn correlated representations and helps filter out modality-specific noise. A dynamic cross-modality interaction module (DCIM) is designed to effectively integrate position and context information, which employs PET images to learn regional position information and serves as a bridge to assist in modeling the relationships between local features of CT images. Extensive experiments on a comprehensive benchmark demonstrate the effectiveness of our CIPA compared to the current state-of-the-art segmentation methods. We hope our research can provide more exploration opportunities for medical image segmentation. The dataset and code are available at https://github.com/mj129/CIPA.
Zero-Shot Aerial Object Detection with Visual Description Regularization
Mar 01, 2024



Existing object detection models are mainly trained on large-scale labeled datasets. However, annotating data for novel aerial object classes is expensive since it is time-consuming and may require expert knowledge. Thus, it is desirable to study label-efficient object detection methods on aerial images. In this work, we propose a zero-shot method for aerial object detection named visual Description Regularization, or DescReg. Concretely, we identify the weak semantic-visual correlation of the aerial objects and aim to address the challenge with prior descriptions of their visual appearance. Instead of directly encoding the descriptions into class embedding space which suffers from the representation gap problem, we propose to infuse the prior inter-class visual similarity conveyed in the descriptions into the embedding learning. The infusion process is accomplished with a newly designed similarity-aware triplet loss which incorporates structured regularization on the representation space. We conduct extensive experiments with three challenging aerial object detection datasets, including DIOR, xView, and DOTA. The results demonstrate that DescReg significantly outperforms the state-of-the-art ZSD methods with complex projection designs and generative frameworks, e.g., DescReg outperforms best reported ZSD method on DIOR by 4.5 mAP on unseen classes and 8.1 in HM. We further show the generalizability of DescReg by integrating it into generative ZSD methods as well as varying the detection architecture.
VCL Challenges 2023 at ICCV 2023 Technical Report: Bi-level Adaptation Method for Test-time Adaptive Object Detection
Oct 13, 2023This report outlines our team's participation in VCL Challenges B Continual Test_time Adaptation, focusing on the technical details of our approach. Our primary focus is Testtime Adaptation using bi_level adaptations, encompassing image_level and detector_level adaptations. At the image level, we employ adjustable parameterbased image filters, while at the detector level, we leverage adjustable parameterbased mean teacher modules. Ultimately, through the utilization of these bi_level adaptations, we have achieved a remarkable 38.3% mAP on the target domain of the test set within VCL Challenges B. It is worth noting that the minimal drop in mAP, is mearly 4.2%, and the overall performance is 32.5% mAP.