 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Synthesis of Compositional Speech and Sound from Free-Form Text Prompts
May 27, 2026Audio generation has made significant progress, yet synthesizing unified audio where speech and sounds are naturally composited remains a challenge. Current methods either rely on disjoint pipelines, which fail to capture fine-grained interactions, or require structured inputs and external text rewriting, which limits the flexibility of free-form text prompts. In this paper, we introduce a new task: Free-Form-Text-Prompt-to-Unified-Audio generation, which aims to directly synthesize unified audio containing speech, sound, and their composites from unconstrained natural language. To address this task, we propose PlanAudio, a unified, autoregressive LLM-based framework. First, it simplifies the model architecture by leveraging intrinsic LLM reasoning capability instead of traditional text encoders. Second, it introduces a semantic latent chain-of-thought mechanism, an implicit planning mechanism that bridges high-level semantic understanding and low-level acoustic synthesis. Furthermore, we create PlanAudio-Bench, a specialized benchmark for evaluating composite audio scenarios. We perform evaluations in the scenarios of speech, sound, and their composites. The results demonstrate that PlanAudio generally outperforms the existing pipeline and unified baselines, while staying competitive with models designed for a single scenario. Our analysis further reveals the superiority of semantic latent CoT over other CoT mechanisms and highlights the importance of continuous multi-scenario training curricula.
Beyond Trajectory-Level Attribution: Graph-Based Credit Assignment for Agentic Reinforcement Learning
May 26, 2026Group-based reinforcement learning (RL) methods have achieved remarkable success in improving the performance of large language models (LLMs) and have been rapidly extended to agentic tasks. However, their credit assignment relies heavily on coarse-grained trajectory-level attribution according to final outcomes, making it difficult to capture the contribution of individual steps, such as valuable steps obscured within failed trajectories. To uncover latent information and enable more faithful step-level credit assignment, we propose Graph-based Group Policy Optimization (GraphGPO), which first aggregates all rollout trajectories into a unified state-transition graph and then estimates the distance from each state to the task goal using the global information encoded in the graph. Finally, GraphGPO assigns credit to each edge by estimating a graph-based advantage, based on how much the transition reduces the distance to the task goal. In this way, GraphGPO significantly improves training efficiency and achieves state-of-the-art performance across a range of challenging benchmarks.
SyncDPO: Enhancing Temporal Synchronization in Video-Audio Joint Generation via Preference Learning
May 12, 2026Recent advancements in video-audio joint generation have achieved remarkable success in semantic correspondence. However, achieving precise temporal synchronization, which requires fine-grained alignment between audio events and their visual triggers, remains a challenging problem. The post-training method for joint generation is largely dominated by Supervised Fine-Tuning, but the commonly used Mean Squared Error loss provides insufficient penalties for subtle temporal misalignments. Direct Preference Optimization offers an alternative by introducing explicit misaligned counterparts to better improve temporal sensitivity. In this paper we propose a post-training framework SyncDPO, leveraging DPO to improve the temporal sensitivity of V-A joint generation. Conventional DPO pipelines typically depend on costly sampling-and-ranking procedures to construct preference pairs, resulting in substantial computational cost. To improve efficiency, we introduce a suite of on-the-fly rule-based negative construction strategies that distort temporal structures without incurring additional annotation or sampling. We demonstrate that the temporal alignment capability can be effectively reinforced by providing explicit negative supervision through temporally distorted V-A pairs. Accordingly, we implement a curriculum learning strategy that progressively increases the difficulty of negative samples, transitioning from coarse misalignment to subtle inconsistencies. Extensive objective and subjective experiments across four diverse benchmarks, ranging from ambient sound videos to human speech videos, demonstrate that SyncDPO significantly outperforms other methods in improving model's temporal alignment capability. It also demonstrates superior generalization on out-of-distribution benchmark by capturing intrinsic motion-sound dynamics. Demo and code is available in https://syncdpo.github.io/syncdpo/.
CUTEv2: Unified and Configurable Matrix Extension for Diverse CPU Architectures with Minimal Design Overhead
Apr 13, 2026Matrix extensions have emerged as an essential feature in modern CPUs to address the surging demands of AI workloads. However, existing designs often incur substantial hardware and software design overhead. Tight coupling with the CPU pipeline complicates integration across diverse CPUs, while fine-grained synchronous instructions hinder the development of high-performance kernels. This paper proposes a unified and configurable CPU matrix extension architecture. By decoupling matrix units from the CPU pipeline, the design enables low-overhead integration while maintaining close coordination with existing compute and memory resources. The configurable matrix unit supports mixed-precision operations and adapts to diverse compute demands and memory bandwidth constraints. An asynchronous matrix multiplication abstraction with flexible granularity conceals hardware details, simplifies matrix-vector overlap, and supports a unified software stack. The architecture is integrated into four open-source CPU RTL platforms and evaluated on representative AI models. Matrix unit utilization under GEMM workloads exceeds 90% across all platforms. When configured with compute throughput and memory bandwidth comparable to Intel AMX, our design achieves speedups of 1.57x, 1.57x, and 2.31x on ResNet, BERT, and Llama3, with over 30% of the gains attributed to overlapped matrix-vector execution. A 4 TOPS@2GHz matrix unit occupies only 0.53 mm\textsuperscript{2} in 14nm CMOS. These results demonstrate strong cross-platform adaptability and effective hardware-software co-optimization, offering a practical matrix extension for the open-source community.
Hierarchy-of-Groups Policy Optimization for Long-Horizon Agentic Tasks
Feb 26, 2026Group-based reinforcement learning (RL), such as GRPO, has advanced the capabilities of large language models on long-horizon agentic tasks. To enable more fine-grained policy updates, recent research has increasingly shifted toward stepwise group-based policy optimization, which treats each step in a rollout trajectory independently while using a memory module to retain historical context. However, we find a key issue in estimating stepwise relative advantages, namely context inconsistency, where steps within the same group may differ in their historical contexts. Empirically, we reveal that this issue can lead to severely biased advantage estimation, thereby degrading policy optimization significantly. To address the issue, in this paper, we propose Hierarchy-of-Groups Policy Optimization (HGPO) for long-horizon agentic tasks. Specifically, within a group of rollout trajectories, HGPO assigns each step to multiple hierarchical groups according to the consistency of historical contexts. Then, for each step, HGPO computes distinct advantages within each group and aggregates them with an adaptive weighting scheme. In this way, HGPO can achieve a favorable bias-variance trade-off in stepwise advantage estimation, without extra models or rollouts. Evaluations on two challenging agentic tasks, ALFWorld and WebShop with Qwen2.5-1.5B-Instruct and Qwen2.5-7B-Instruct, show that HGPO significantly outperforms existing agentic RL methods under the same computational constraints. Code is available at https://github.com/langfengQ/verl-agent/tree/master/recipe/hgpo.
Online Causal Kalman Filtering for Stable and Effective Policy Optimization
Feb 11, 2026Reinforcement learning for large language models suffers from high-variance token-level importance sampling (IS) ratios, which would destabilize policy optimization at scale. To improve stability, recent methods typically use a fixed sequence-level IS ratio for all tokens in a sequence or adjust each token's IS ratio separately, thereby neglecting temporal off-policy derivation across tokens in a sequence. In this paper, we first empirically identify that local off-policy deviation is structurally inconsistent at the token level, which may distort policy-gradient updates across adjacent tokens and lead to training collapse. To address the issue, we propose Online Causal Kalman Filtering for stable and effective Policy Optimization (KPO). Concretely, we model the desired IS ratio as a latent state that evolves across tokens and apply a Kalman filter to update this state online and autoregressively based on the states of past tokens, regardless of future tokens. The resulting filtered IS ratios preserve token-wise local structure-aware variation while strongly smoothing noise spikes, yielding more stable and effective policy updates. Experimentally, KPO achieves superior results on challenging math reasoning datasets compared with state-of-the-art counterparts.
Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models
Jan 12, 2026While Mixture-of-Experts (MoE) scales capacity via conditional computation, Transformers lack a native primitive for knowledge lookup, forcing them to inefficiently simulate retrieval through computation. To address this, we introduce conditional memory as a complementary sparsity axis, instantiated via Engram, a module that modernizes classic $N$-gram embedding for O(1) lookup. By formulating the Sparsity Allocation problem, we uncover a U-shaped scaling law that optimizes the trade-off between neural computation (MoE) and static memory (Engram). Guided by this law, we scale Engram to 27B parameters, achieving superior performance over a strictly iso-parameter and iso-FLOPs MoE baseline. Most notably, while the memory module is expected to aid knowledge retrieval (e.g., MMLU +3.4; CMMLU +4.0), we observe even larger gains in general reasoning (e.g., BBH +5.0; ARC-Challenge +3.7) and code/math domains~(HumanEval +3.0; MATH +2.4). Mechanistic analyses reveal that Engram relieves the backbone's early layers from static reconstruction, effectively deepening the network for complex reasoning. Furthermore, by delegating local dependencies to lookups, it frees up attention capacity for global context, substantially boosting long-context retrieval (e.g., Multi-Query NIAH: 84.2 to 97.0). Finally, Engram establishes infrastructure-aware efficiency: its deterministic addressing enables runtime prefetching from host memory, incurring negligible overhead. We envision conditional memory as an indispensable modeling primitive for next-generation sparse models.
AgentOCR: Reimagining Agent History via Optical Self-Compression
Jan 08, 2026Recent advances in large language models (LLMs) enable agentic systems trained with reinforcement learning (RL) over multi-turn interaction trajectories, but practical deployment is bottlenecked by rapidly growing textual histories that inflate token budgets and memory usage. We introduce AgentOCR, a framework that exploits the superior information density of visual tokens by representing the accumulated observation-action history as a compact rendered image. To make multi-turn rollouts scalable, AgentOCR proposes segment optical caching. By decomposing history into hashable segments and maintaining a visual cache, this mechanism eliminates redundant re-rendering. Beyond fixed rendering, AgentOCR introduces agentic self-compression, where the agent actively emits a compression rate and is trained with compression-aware reward to adaptively balance task success and token efficiency. We conduct extensive experiments on challenging agentic benchmarks, ALFWorld and search-based QA. Remarkably, results demonstrate that AgentOCR preserves over 95\% of text-based agent performance while substantially reducing token consumption (>50\%), yielding consistent token and memory efficiency. Our further analysis validates a 20x rendering speedup from segment optical caching and the effective strategic balancing of self-compression.
Reasoning via Video: The First Evaluation of Video Models' Reasoning Abilities through Maze-Solving Tasks
Nov 19, 2025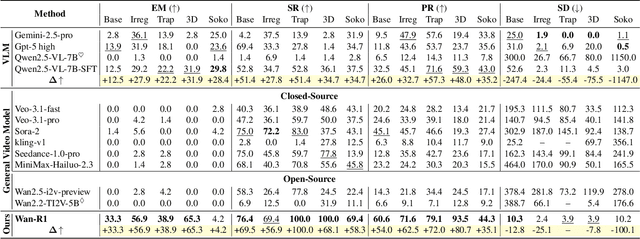

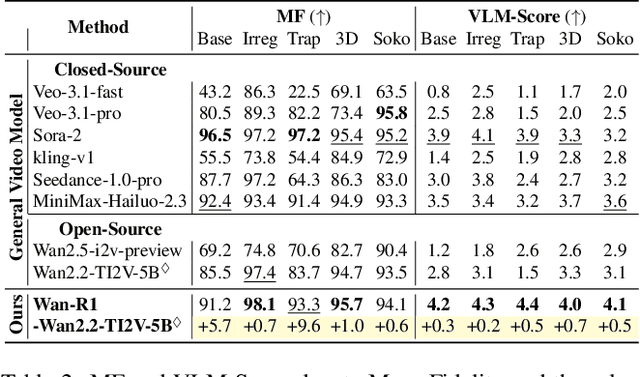
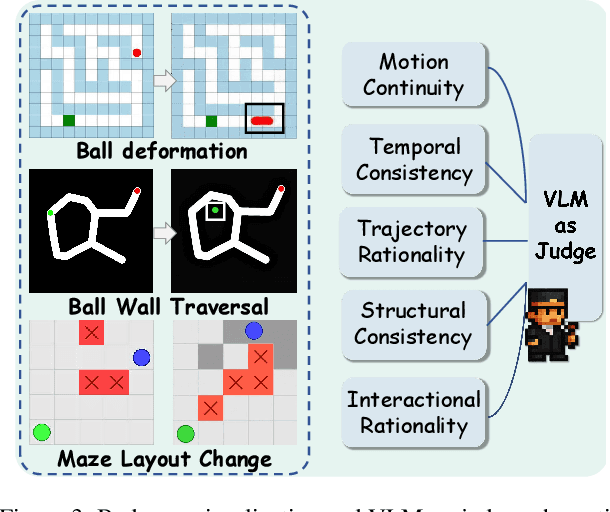
Video Models have achieved remarkable success in high-fidelity video generation with coherent motion dynamics. Analogous to the development from text generation to text-based reasoning in language modeling, the development of video models motivates us to ask: Can video models reason via video generation? Compared with the discrete text corpus, video grounds reasoning in explicit spatial layouts and temporal continuity, which serves as an ideal substrate for spatial reasoning. In this work, we explore the reasoning via video paradigm and introduce VR-Bench -- a comprehensive benchmark designed to systematically evaluate video models' reasoning capabilities. Grounded in maze-solving tasks that inherently require spatial planning and multi-step reasoning, VR-Bench contains 7,920 procedurally generated videos across five maze types and diverse visual styles. Our empirical analysis demonstrates that SFT can efficiently elicit the reasoning ability of video model. Video models exhibit stronger spatial perception during reasoning, outperforming leading VLMs and generalizing well across diverse scenarios, tasks, and levels of complexity. We further discover a test-time scaling effect, where diverse sampling during inference improves reasoning reliability by 10--20%. These findings highlight the unique potential and scalability of reasoning via video for spatial reasoning tasks.
WildSpoof Challenge Evaluation Plan
Aug 23, 2025The WildSpoof Challenge aims to advance the use of in-the-wild data in two intertwined speech processing tasks. It consists of two parallel tracks: (1) Text-to-Speech (TTS) synthesis for generating spoofed speech, and (2) Spoofing-robust Automatic Speaker Verification (SASV) for detecting spoofed speech. While the organizers coordinate both tracks and define the data protocols, participants treat them as separate and independent tasks. The primary objectives of the challenge are: (i) to promote the use of in-the-wild data for both TTS and SASV, moving beyond conventional clean and controlled datasets and considering real-world scenarios; and (ii) to encourage interdisciplinary collaboration between the spoofing generation (TTS) and spoofing detection (SASV) communities, thereby fostering the development of more integrated, robust, and realistic systems.