 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeATA: Bridging Implicit Reasoning with Attention-Guided and Action-Guided Inference for Vision-Language Action Models
Mar 02, 2026Vision-Language-Action (VLA) models rely on current observations, including images, language instructions, and robot states, to predict actions and complete tasks. While accurate visual perception is crucial for precise action prediction and execution, recent work has attempted to further improve performance by introducing explicit reasoning during inference. However, such approaches face significant limitations. They often depend on data-intensive resources such as Chain-of-Thought (CoT) style annotations to decompose tasks into step-by-step reasoning, and in many cases require additional visual grounding annotations (e.g., bounding boxes or masks) to highlight relevant image regions. Moreover, they involve time-consuming dataset construction, labeling, and retraining, which ultimately results in longer inference sequences and reduced efficiency. To address these challenges, we propose ATA, a novel training-free framework that introduces implicit reasoning into VLA inference through complementary attention-guided and action-guided strategies. Unlike CoT or explicit visual-grounding methods, ATA formulates reasoning implicitly by integrating attention maps with an action-based region of interest (RoI), thereby adaptively refining visual inputs without requiring extra training or annotations. ATA is a plug-and-play implicit reasoning approach for VLA models, lightweight yet effective. Extensive experiments show that it consistently improves task success and robustness while preserving, and even enhancing, inference efficiency.
EcoSpa: Efficient Transformer Training with Coupled Sparsity
Nov 09, 2025Transformers have become the backbone of modern AI, yet their high computational demands pose critical system challenges. While sparse training offers efficiency gains, existing methods fail to preserve critical structural relationships between weight matrices that interact multiplicatively in attention and feed-forward layers. This oversight leads to performance degradation at high sparsity levels. We introduce EcoSpa, an efficient structured sparse training method that jointly evaluates and sparsifies coupled weight matrix pairs, preserving their interaction patterns through aligned row/column removal. EcoSpa introduces a new granularity for calibrating structural component importance and performs coupled estimation and sparsification across both pre-training and fine-tuning scenarios. Evaluations demonstrate substantial improvements: EcoSpa enables efficient training of LLaMA-1B with 50\% memory reduction and 21\% faster training, achieves $2.2\times$ model compression on GPT-2-Medium with $2.4$ lower perplexity, and delivers $1.6\times$ inference speedup. The approach uses standard PyTorch operations, requiring no custom hardware or kernels, making efficient transformer training accessible on commodity hardware.
LowDiff: Efficient Diffusion Sampling with Low-Resolution Condition
Sep 18, 2025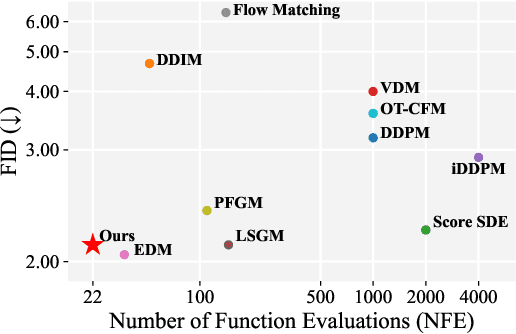
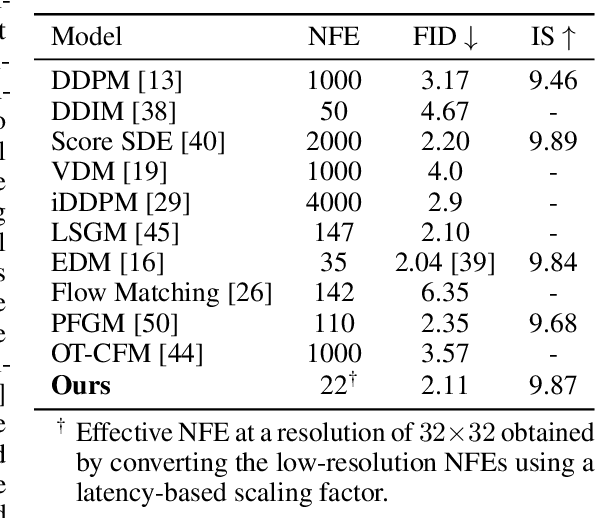
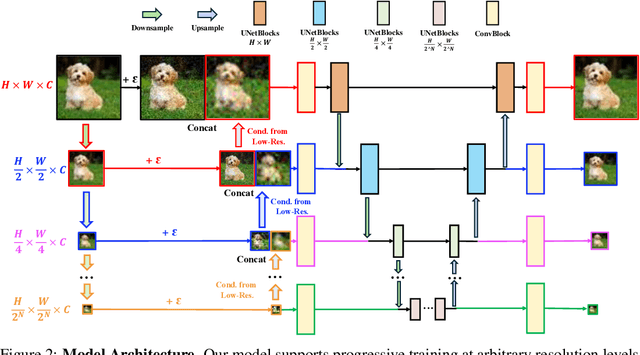
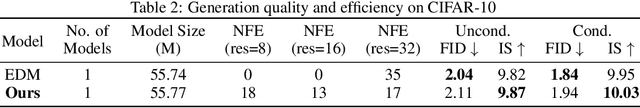
Diffusion models have achieved remarkable success in image generation but their practical application is often hindered by the slow sampling speed. Prior efforts of improving efficiency primarily focus on compressing models or reducing the total number of denoising steps, largely neglecting the possibility to leverage multiple input resolutions in the generation process. In this work, we propose LowDiff, a novel and efficient diffusion framework based on a cascaded approach by generating increasingly higher resolution outputs. Besides, LowDiff employs a unified model to progressively refine images from low resolution to the desired resolution. With the proposed architecture design and generation techniques, we achieve comparable or even superior performance with much fewer high-resolution sampling steps. LowDiff is applicable to diffusion models in both pixel space and latent space. Extensive experiments on both conditional and unconditional generation tasks across CIFAR-10, FFHQ and ImageNet demonstrate the effectiveness and generality of our method. Results show over 50% throughput improvement across all datasets and settings while maintaining comparable or better quality. On unconditional CIFAR-10, LowDiff achieves an FID of 2.11 and IS of 9.87, while on conditional CIFAR-10, an FID of 1.94 and IS of 10.03. On FFHQ 64x64, LowDiff achieves an FID of 2.43, and on ImageNet 256x256, LowDiff built on LightningDiT-B/1 produces high-quality samples with a FID of 4.00 and an IS of 195.06, together with substantial efficiency gains.
When Tokens Talk Too Much: A Survey of Multimodal Long-Context Token Compression across Images, Videos, and Audios
Jul 27, 2025



Multimodal large language models (MLLMs) have made remarkable strides, largely driven by their ability to process increasingly long and complex contexts, such as high-resolution images, extended video sequences, and lengthy audio input. While this ability significantly enhances MLLM capabilities, it introduces substantial computational challenges, primarily due to the quadratic complexity of self-attention mechanisms with numerous input tokens. To mitigate these bottlenecks, token compression has emerged as an auspicious and critical approach, efficiently reducing the number of tokens during both training and inference. In this paper, we present the first systematic survey and synthesis of the burgeoning field of multimodal long context token compression. Recognizing that effective compression strategies are deeply tied to the unique characteristics and redundancies of each modality, we categorize existing approaches by their primary data focus, enabling researchers to quickly access and learn methods tailored to their specific area of interest: (1) image-centric compression, which addresses spatial redundancy in visual data; (2) video-centric compression, which tackles spatio-temporal redundancy in dynamic sequences; and (3) audio-centric compression, which handles temporal and spectral redundancy in acoustic signals. Beyond this modality-driven categorization, we further dissect methods based on their underlying mechanisms, including transformation-based, similarity-based, attention-based, and query-based approaches. By providing a comprehensive and structured overview, this survey aims to consolidate current progress, identify key challenges, and inspire future research directions in this rapidly evolving domain. We also maintain a public repository to continuously track and update the latest advances in this promising area.
Multi-task Learning for Heterogeneous Data via Integrating Shared and Task-Specific Encodings
May 30, 2025Multi-task learning (MTL) has become an essential machine learning tool for addressing multiple learning tasks simultaneously and has been effectively applied across fields such as healthcare, marketing, and biomedical research. However, to enable efficient information sharing across tasks, it is crucial to leverage both shared and heterogeneous information. Despite extensive research on MTL, various forms of heterogeneity, including distribution and posterior heterogeneity, present significant challenges. Existing methods often fail to address these forms of heterogeneity within a unified framework. In this paper, we propose a dual-encoder framework to construct a heterogeneous latent factor space for each task, incorporating a task-shared encoder to capture common information across tasks and a task-specific encoder to preserve unique task characteristics. Additionally, we explore the intrinsic similarity structure of the coefficients corresponding to learned latent factors, allowing for adaptive integration across tasks to manage posterior heterogeneity. We introduce a unified algorithm that alternately learns the task-specific and task-shared encoders and coefficients. In theory, we investigate the excess risk bound for the proposed MTL method using local Rademacher complexity and apply it to a new but related task. Through simulation studies, we demonstrate that the proposed method outperforms existing data integration methods across various settings. Furthermore, the proposed method achieves superior predictive performance for time to tumor doubling across five distinct cancer types in PDX data.
Multi-task Learning for Heterogeneous Multi-source Block-Wise Missing Data
May 30, 2025Multi-task learning (MTL) has emerged as an imperative machine learning tool to solve multiple learning tasks simultaneously and has been successfully applied to healthcare, marketing, and biomedical fields. However, in order to borrow information across different tasks effectively, it is essential to utilize both homogeneous and heterogeneous information. Among the extensive literature on MTL, various forms of heterogeneity are presented in MTL problems, such as block-wise, distribution, and posterior heterogeneity. Existing methods, however, struggle to tackle these forms of heterogeneity simultaneously in a unified framework. In this paper, we propose a two-step learning strategy for MTL which addresses the aforementioned heterogeneity. First, we impute the missing blocks using shared representations extracted from homogeneous source across different tasks. Next, we disentangle the mappings between input features and responses into a shared component and a task-specific component, respectively, thereby enabling information borrowing through the shared component. Our numerical experiments and real-data analysis from the ADNI database demonstrate the superior MTL performance of the proposed method compared to other competing methods.
HoliTom: Holistic Token Merging for Fast Video Large Language Models
May 28, 2025Video large language models (video LLMs) excel at video comprehension but face significant computational inefficiency due to redundant video tokens. Existing token pruning methods offer solutions. However, approaches operating within the LLM (inner-LLM pruning), such as FastV, incur intrinsic computational overhead in shallow layers. In contrast, methods performing token pruning before the LLM (outer-LLM pruning) primarily address spatial redundancy within individual frames or limited temporal windows, neglecting the crucial global temporal dynamics and correlations across longer video sequences. This leads to sub-optimal spatio-temporal reduction and does not leverage video compressibility fully. Crucially, the synergistic potential and mutual influence of combining these strategies remain unexplored. To further reduce redundancy, we introduce HoliTom, a novel training-free holistic token merging framework. HoliTom employs outer-LLM pruning through global redundancy-aware temporal segmentation, followed by spatial-temporal merging to reduce visual tokens by over 90%, significantly alleviating the LLM's computational burden. Complementing this, we introduce a robust inner-LLM token similarity-based merging approach, designed for superior performance and compatibility with outer-LLM pruning. Evaluations demonstrate our method's promising efficiency-performance trade-off on LLaVA-OneVision-7B, reducing computational costs to 6.9% of FLOPs while maintaining 99.1% of the original performance. Furthermore, we achieve a 2.28x reduction in Time-To-First-Token (TTFT) and a 1.32x acceleration in decoding throughput, highlighting the practical benefits of our integrated pruning approach for efficient video LLMs inference.
AutoL2S: Auto Long-Short Reasoning for Efficient Large Language Models
May 28, 2025The reasoning-capable large language models (LLMs) demonstrate strong performance on complex reasoning tasks but often suffer from overthinking, generating unnecessarily long chain-of-thought (CoT) reasoning paths for easy reasoning questions, thereby increasing inference cost and latency. Recent approaches attempt to address this challenge by manually deciding when to apply long or short reasoning. However, they lack the flexibility to adapt CoT length dynamically based on question complexity. In this paper, we propose Auto Long-Short Reasoning (AutoL2S), a dynamic and model-agnostic framework that enables LLMs to dynamically compress their generated reasoning path based on the complexity of the reasoning question. AutoL2S enables a learned paradigm, in which LLMs themselves can decide when longer reasoning is necessary and when shorter reasoning suffices, by training on data annotated with our proposed method, which includes both long and short CoT paths and a special <EASY> token. We then use <EASY> token to indicate when the model can skip generating lengthy CoT reasoning. This proposed annotation strategy can enhance the LLMs' ability to generate shorter CoT reasoning paths with improved quality after training. Extensive evaluation results show that AutoL2S reduces the length of reasoning generation by up to 57% without compromising performance, demonstrating the effectiveness of AutoL2S for scalable and efficient LLM reasoning.
70% Size, 100% Accuracy: Lossless LLM Compression for Efficient GPU Inference via Dynamic-Length Float
Apr 15, 2025



Large Language Models (LLMs) have grown rapidly in size, creating significant challenges for efficient deployment on resource-constrained hardware. In this paper, we introduce Dynamic-Length Float (DFloat11), a lossless compression framework that reduces LLM size by 30% while preserving outputs that are bit-for-bit identical to the original model. DFloat11 is motivated by the low entropy in the BFloat16 weight representation of LLMs, which reveals significant inefficiency in existing storage format. By applying entropy coding, DFloat11 assigns dynamic-length encodings to weights based on frequency, achieving near information-optimal compression without any loss of precision. To facilitate efficient inference with dynamic-length encodings, we develop a custom GPU kernel for fast online decompression. Our design incorporates the following: (i) decomposition of memory-intensive lookup tables (LUTs) into compact LUTs that fit in GPU SRAM, (ii) a two-phase kernel for coordinating thread read/write positions using lightweight auxiliary variables, and (iii) transformer-block-level decompression to minimize latency. Experiments on recent models, including Llama-3.1, Qwen-2.5, and Gemma-3, validates our hypothesis that DFloat11 achieves around 30% model size reduction while preserving bit-for-bit exact outputs. Compared to a potential alternative of offloading parts of an uncompressed model to the CPU to meet memory constraints, DFloat11 achieves 1.9-38.8x higher throughput in token generation. With a fixed GPU memory budget, DFloat11 enables 5.3-13.17x longer context lengths than uncompressed models. Notably, our method enables lossless inference of Llama-3.1-405B, an 810GB model, on a single node equipped with 8x80GB GPUs. Our code and models are available at https://github.com/LeanModels/DFloat11.
Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models
Mar 20, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities in complex tasks. Recent advancements in Large Reasoning Models (LRMs), such as OpenAI o1 and DeepSeek-R1, have further improved performance in System-2 reasoning domains like mathematics and programming by harnessing supervised fine-tuning (SFT) and reinforcement learning (RL) techniques to enhance the Chain-of-Thought (CoT) reasoning. However, while longer CoT reasoning sequences improve performance, they also introduce significant computational overhead due to verbose and redundant outputs, known as the "overthinking phenomenon". In this paper, we provide the first structured survey to systematically investigate and explore the current progress toward achieving efficient reasoning in LLMs. Overall, relying on the inherent mechanism of LLMs, we categorize existing works into several key directions: (1) model-based efficient reasoning, which considers optimizing full-length reasoning models into more concise reasoning models or directly training efficient reasoning models; (2) reasoning output-based efficient reasoning, which aims to dynamically reduce reasoning steps and length during inference; (3) input prompts-based efficient reasoning, which seeks to enhance reasoning efficiency based on input prompt properties such as difficulty or length control. Additionally, we introduce the use of efficient data for training reasoning models, explore the reasoning capabilities of small language models, and discuss evaluation methods and benchmarking.