 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGVC-Seg: Training-Free 3D Instance Segmentation via Geometric Visual Correspondence
Jun 06, 2026Accurate 3D instance segmentation in point cloud data is critical for machine vision applications. Recent advancements leverage multiple pre-trained foundation models to generate 3D proposals, followed by the application of proposal aggregation methods, which significantly enhance performance. However, they often produce sub-optimal results due to inherent variations in confidence levels across different segmentation models, resulting in a bias toward the model with higher confidence. This bias is inherently model-dependent and is influenced by factors such as data preprocessing techniques and training strategies. To address this bias, we propose a novel, training-free 3D instance segmentation approach via Geometric Visual Correspondence (GVC-Seg), which exploits the correspondence between 3D geometric cues and 2D visual cues to mitigate the confidence bias. Additionally, a 3D proposal generation module and a mask-aware CLIP feature extraction module are introduced during the instance mask generation and instance semantic reasoning, respectively. In this way, GVC-Seg enhances proposal quality assessment, ensuring unbiased ensemble learning across different models. Extensive experiments demonstrate that our method achieves state-of-the-art performance on several challenging benchmarks, while also exhibiting strong potential in open-vocabulary semantic segmentation settings.
RelPrism: A Multi-Faceted Pre-training Framework with Self-Generated Tasks for Relational Databases
May 22, 2026Relational databases (RDBs) remain the cornerstone of modern data systems and support diverse predictive tasks. Recent relational deep learning (RDL) methods enable end-to-end prediction by converting RDBs into graphs, where rows are represented as nodes and inter-table interactions are represented as edges, and then applying graph-based models for representation learning. Despite the strong capability of RDL, effective self-supervised pre-training for RDBs remains non-trivial. RDB tasks often require multi-faceted information across different perspectives and granularities. For example, user churn classification may rely more on interaction patterns, whereas consumption value prediction requires both user-item behaviors and intrinsic user attributes for fine-grained regression. Such heterogeneous needs challenge RDB representation learning, as pre-training objectives should cover comprehensive information for downstream adaptation. However, existing SSL methods typically derive supervision from a single facet, such as node-level intrinsic attributes or subgraph-level relational structures, providing limited adaptability. To this end, we propose RelPrism, a multi-faceted self-supervised learning framework for RDBs. RelPrism constructs intrinsic, relational, and hybrid attributes from distinct perspectives, and applies multi-granularity clustering to each perspective to form corresponding pseudo-task pools. Pre-training over these pools exposes representations to broader perspectives and granularity levels, yielding a stronger basis for downstream adaptation. Experiments on 14 tasks across 5 real-world datasets show that RelPrism improves ROC-AUC by 4.15% for classification and reduces MAE by 10.75% for regression over state-of-the-art baselines. Our code is available at https://anonymous.4open.science/r/RelPrism.
LiveVLN: Breaking the Stop-and-Go Loop in Vision-Language Navigation
Apr 21, 2026Recent navigation systems achieve strong benchmark results, yet real-world deployment often remains visibly stop-and-go. This bottleneck arises because the sense-inference-execution loop is still blocking: after each new observation, the controller must wait for sensing, transmission, and inference before motion can continue. Reducing action-generation cost alone therefore does not remove redundant waiting. To address this issue, we present LiveVLN, a training-free framework for more continuous embodied navigation by augmenting pretrained VLM navigators with multi-step action continuation. Instead of pausing for each full sense-and-inference round, LiveVLN overlaps execution with the processing of newly arrived observations, allowing refreshed future actions to be handed off before the current executable prefix is exhausted. This design keeps actions continuously available during motion, reducing idle waiting and enabling smoother online execution. The framework operates at runtime and can be integrated with compatible pretrained VLM navigators. Across R2R and RxR, LiveVLN preserves benchmark performance while reducing waiting time and improving action availability. In real-world deployments, it cuts average episode waiting time by up to $77.7\%$ and shortens wall-clock episode time by $12.6\%$ on StreamVLN and $19.6\%$ on NaVIDA, yielding more coherent execution during deployment. Code is available at https://github.com/NIneeeeeem/LiveVLN.
Dictionary-Aligned Concept Control for Safeguarding Multimodal LLMs
Apr 10, 2026Multimodal Large Language Models (MLLMs) have been shown to be vulnerable to malicious queries that can elicit unsafe responses. Recent work uses prompt engineering, response classification, or finetuning to improve MLLM safety. Nevertheless, such approaches are often ineffective against evolving malicious patterns, may require rerunning the query, or demand heavy computational resources. Steering the activations of a frozen model at inference time has recently emerged as a flexible and effective solution. However, existing steering methods for MLLMs typically handle only a narrow set of safety-related concepts or struggle to adjust specific concepts without affecting others. To address these challenges, we introduce Dictionary-Aligned Concept Control (DACO), a framework that utilizes a curated concept dictionary and a Sparse Autoencoder (SAE) to provide granular control over MLLM activations. First, we curate a dictionary of 15,000 multimodal concepts by retrieving over 400,000 caption-image stimuli and summarizing their activations into concept directions. We name the dataset DACO-400K. Second, we show that the curated dictionary can be used to intervene activations via sparse coding. Third, we propose a new steering approach that uses our dictionary to initialize the training of an SAE and automatically annotate the semantics of the SAE atoms for safeguarding MLLMs. Experiments on multiple MLLMs (e.g., QwenVL, LLaVA, InternVL) across safety benchmarks (e.g., MM-SafetyBench, JailBreakV) show that DACO significantly improves MLLM safety while maintaining general-purpose capabilities.
Show Me When and Where: Towards Referring Video Object Segmentation in the Wild
Mar 15, 2026Referring video object segmentation (RVOS) has recently generated great popularity in computer vision due to its widespread applications. Existing RVOS setting contains elaborately trimmed videos, with text-referred objects always appearing in all frames, which however fail to fully reflect the realistic challenges of this task. This simplified setting requires RVOS methods to only predict where objects, with no need to show when the objects appear. In this work, we introduce a new setting towards in-the-wild RVOS. To this end, we collect a new benchmark dataset using Youtube Untrimmed videos for RVOS - YoURVOS, which contains 1,120 in-the-wild videos with 7 times more duration and scenes than existing datasets. Our new benchmark challenges RVOS methods to show not only where but also when objects appear in videos. To set a baseline, we propose Object-level Multimodal TransFormers (OMFormer) to tackle the challenges, which are characterized by encoding object-level multimodal interactions for efficient and global spatial-temporal localisation. We demonstrate that previous VOS methods struggle on our YoURVOS benchmark, especially with the increase of target-absent frames, while our OMFormer consistently performs well. Our YoURVOS dataset offers an imperative benchmark, which will push forward the advancement of RVOS methods for practical applications.
RADAR: Closed-Loop Robotic Data Generation via Semantic Planning and Autonomous Causal Environment Reset
Mar 12, 2026The acquisition of large-scale physical interaction data, a critical prerequisite for modern robot learning, is severely bottlenecked by the prohibitive cost and scalability limits of human-in-the-loop collection paradigms. To break this barrier, we introduce Robust Autonomous Data Acquisition for Robotics (RADAR), a fully autonomous, closed-loop data generation engine that completely removes human intervention from the collection cycle. RADAR elegantly divides the cognitive load into a four-module pipeline. Anchored by 2-5 3D human demonstrations as geometric priors, a Vision-Language Model first orchestrates scene-relevant task generation via precise semantic object grounding and skill retrieval. Next, a Graph Neural Network policy translates these subtasks into physical actions via in-context imitation learning. Following execution, the VLM performs automated success evaluation using a structured Visual Question Answering pipeline. Finally, to shatter the bottleneck of manual resets, a Finite State Machine orchestrates an autonomous environment reset and asymmetric data routing mechanism. Driven by simultaneous forward-reverse planning with a strict Last-In, First-Out causal sequence, the system seamlessly restores unstructured workspaces and robustly recovers from execution failures. This continuous brain-cerebellum synergy transforms data collection into a self-sustaining process. Extensive evaluations highlight RADAR's exceptional versatility. In simulation, our framework achieves up to 90% success rates on complex, long-horizon tasks, effortlessly solving challenges where traditional baselines plummet to near-zero performance. In real-world deployments, the system reliably executes diverse, contact-rich skills (e.g., deformable object manipulation) via few-shot adaptation without domain-specific fine-tuning, providing a highly scalable paradigm for robotic data acquisition.
LLM-driven Indoor Scene Layout Generation via Scaled Human-aligned Data Synthesis and Multi-Stage Preference Optimization
Jun 09, 2025Automatic indoor layout generation has attracted increasing attention due to its potential in interior design, virtual environment construction, and embodied AI. Existing methods fall into two categories: prompt-driven approaches that leverage proprietary LLM services (e.g., GPT APIs) and learning-based methods trained on layout data upon diffusion-based models. Prompt-driven methods often suffer from spatial inconsistency and high computational costs, while learning-based methods are typically constrained by coarse relational graphs and limited datasets, restricting their generalization to diverse room categories. In this paper, we revisit LLM-based indoor layout generation and present 3D-SynthPlace, a large-scale dataset that combines synthetic layouts generated via a 'GPT synthesize, Human inspect' pipeline, upgraded from the 3D-Front dataset. 3D-SynthPlace contains nearly 17,000 scenes, covering four common room types -- bedroom, living room, kitchen, and bathroom -- enriched with diverse objects and high-level spatial annotations. We further introduce OptiScene, a strong open-source LLM optimized for indoor layout generation, fine-tuned based on our 3D-SynthPlace dataset through our two-stage training. For the warum-up stage I, we adopt supervised fine-tuning (SFT), which is taught to first generate high-level spatial descriptions then conditionally predict concrete object placements. For the reinforcing stage II, to better align the generated layouts with human design preferences, we apply multi-turn direct preference optimization (DPO), which significantly improving layout quality and generation success rates. Extensive experiments demonstrate that OptiScene outperforms traditional prompt-driven and learning-based baselines. Moreover, OptiScene shows promising potential in interactive tasks such as scene editing and robot navigation.
Masked Language Models are Good Heterogeneous Graph Generalizers
Jun 06, 2025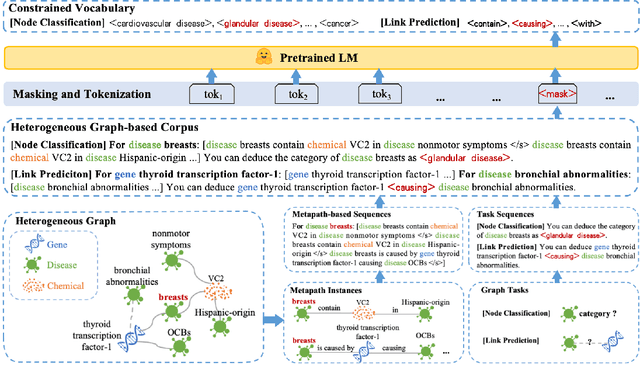
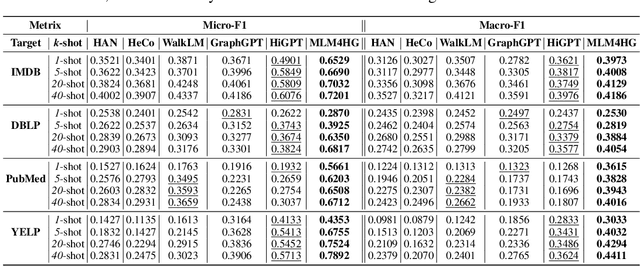
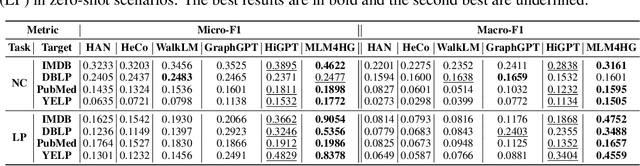
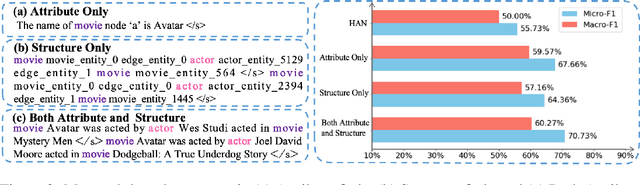
Heterogeneous graph neural networks (HGNNs) excel at capturing structural and semantic information in heterogeneous graphs (HGs), while struggling to generalize across domains and tasks. Recently, some researchers have turned to integrating HGNNs with large language models (LLMs) for more generalizable heterogeneous graph learning. However, these approaches typically extract structural information via HGNNs as HG tokens, and disparities in embedding spaces between HGNNs and LLMs have been shown to bias the LLM's comprehension of HGs. Moreover, as these HG tokens are often derived from node-level tasks, the model's ability to generalize across tasks remains limited. To this end, we propose a simple yet effective Masked Language Modeling-based method, called MLM4HG. MLM4HG introduces metapath-based textual sequences instead of HG tokens to extract structural and semantic information inherent in HGs, and designs customized textual templates to unify different graph tasks into a coherent cloze-style "mask" token prediction paradigm. Specifically, MLM4HG first converts HGs from various domains to texts based on metapaths, and subsequently combines them with the unified task texts to form a HG-based corpus. Moreover, the corpus is fed into a pretrained LM for fine-tuning with a constrained target vocabulary, enabling the fine-tuned LM to generalize to unseen target HGs. Extensive cross-domain and multi-task experiments on four real-world datasets demonstrate the superior generalization performance of MLM4HG over state-of-the-art methods in both few-shot and zero-shot scenarios. Our code is available at https://github.com/BUPT-GAMMA/MLM4HG.
RefComp: A Reference-guided Unified Framework for Unpaired Point Cloud Completion
Apr 18, 2025The unpaired point cloud completion task aims to complete a partial point cloud by using models trained with no ground truth. Existing unpaired point cloud completion methods are class-aware, i.e., a separate model is needed for each object class. Since they have limited generalization capabilities, these methods perform poorly in real-world scenarios when confronted with a wide range of point clouds of generic 3D objects. In this paper, we propose a novel unpaired point cloud completion framework, namely the Reference-guided Completion (RefComp) framework, which attains strong performance in both the class-aware and class-agnostic training settings. The RefComp framework transforms the unpaired completion problem into a shape translation problem, which is solved in the latent feature space of the partial point clouds. To this end, we introduce the use of partial-complete point cloud pairs, which are retrieved by using the partial point cloud to be completed as a template. These point cloud pairs are used as reference data to guide the completion process. Our RefComp framework uses a reference branch and a target branch with shared parameters for shape fusion and shape translation via a Latent Shape Fusion Module (LSFM) to enhance the structural features along the completion pipeline. Extensive experiments demonstrate that the RefComp framework achieves not only state-of-the-art performance in the class-aware training setting but also competitive results in the class-agnostic training setting on both virtual scans and real-world datasets.
CoLLM: A Large Language Model for Composed Image Retrieval
Mar 25, 2025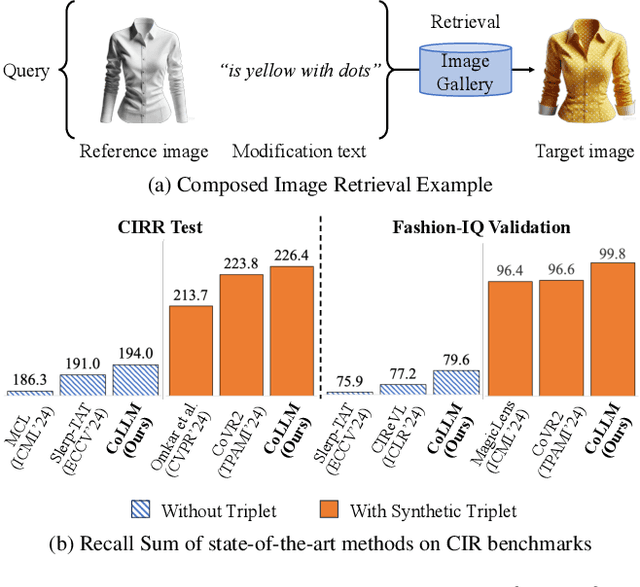
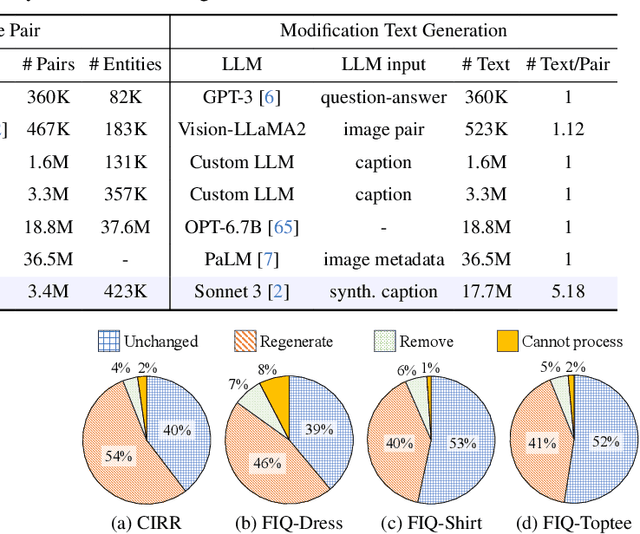
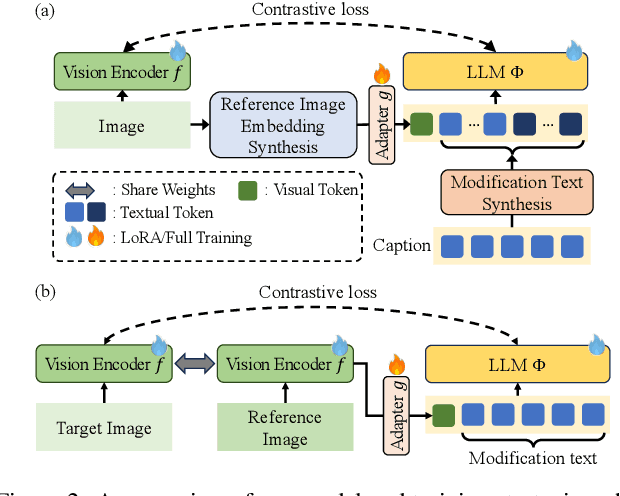
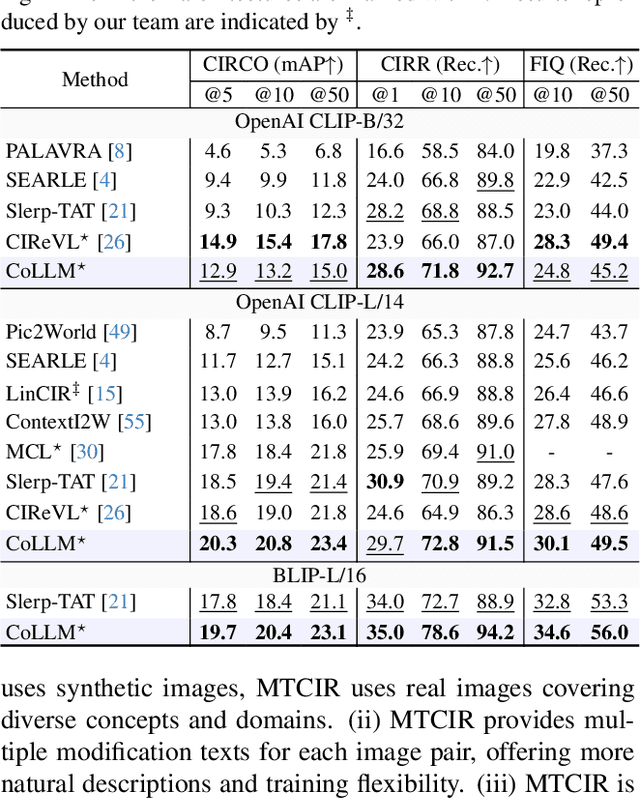
Composed Image Retrieval (CIR) is a complex task that aims to retrieve images based on a multimodal query. Typical training data consists of triplets containing a reference image, a textual description of desired modifications, and the target image, which are expensive and time-consuming to acquire. The scarcity of CIR datasets has led to zero-shot approaches utilizing synthetic triplets or leveraging vision-language models (VLMs) with ubiquitous web-crawled image-caption pairs. However, these methods have significant limitations: synthetic triplets suffer from limited scale, lack of diversity, and unnatural modification text, while image-caption pairs hinder joint embedding learning of the multimodal query due to the absence of triplet data. Moreover, existing approaches struggle with complex and nuanced modification texts that demand sophisticated fusion and understanding of vision and language modalities. We present CoLLM, a one-stop framework that effectively addresses these limitations. Our approach generates triplets on-the-fly from image-caption pairs, enabling supervised training without manual annotation. We leverage Large Language Models (LLMs) to generate joint embeddings of reference images and modification texts, facilitating deeper multimodal fusion. Additionally, we introduce Multi-Text CIR (MTCIR), a large-scale dataset comprising 3.4M samples, and refine existing CIR benchmarks (CIRR and Fashion-IQ) to enhance evaluation reliability. Experimental results demonstrate that CoLLM achieves state-of-the-art performance across multiple CIR benchmarks and settings. MTCIR yields competitive results, with up to 15% performance improvement. Our refined benchmarks provide more reliable evaluation metrics for CIR models, contributing to the advancement of this important field.