 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast and Accurate Camera Scene Detection on Smartphones
May 17, 2021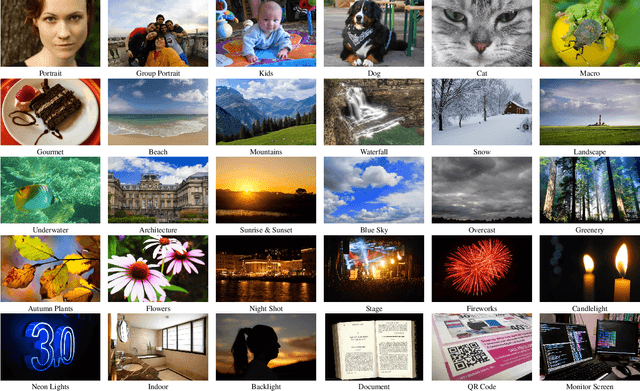

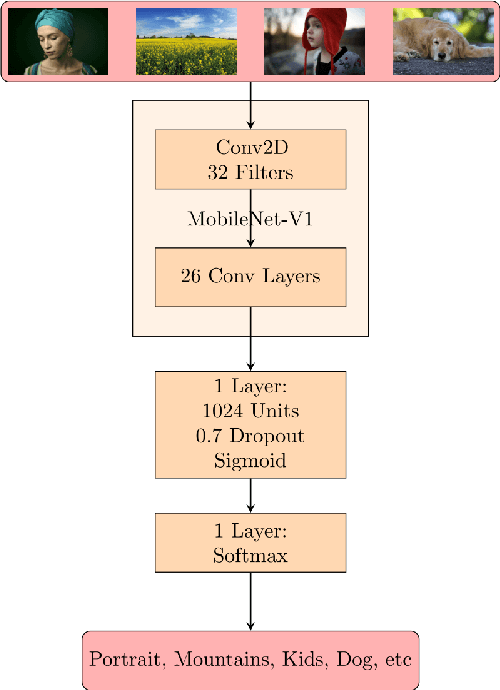
AI-powered automatic camera scene detection mode is nowadays available in nearly any modern smartphone, though the problem of accurate scene prediction has not yet been addressed by the research community. This paper for the first time carefully defines this problem and proposes a novel Camera Scene Detection Dataset (CamSDD) containing more than 11K manually crawled images belonging to 30 different scene categories. We propose an efficient and NPU-friendly CNN model for this task that demonstrates a top-3 accuracy of 99.5% on this dataset and achieves more than 200 FPS on the recent mobile SoCs. An additional in-the-wild evaluation of the obtained solution is performed to analyze its performance and limitation in the real-world scenarios. The dataset and pre-trained models used in this paper are available on the project website.
Fast and Accurate Quantized Camera Scene Detection on Smartphones, Mobile AI 2021 Challenge: Report
May 17, 2021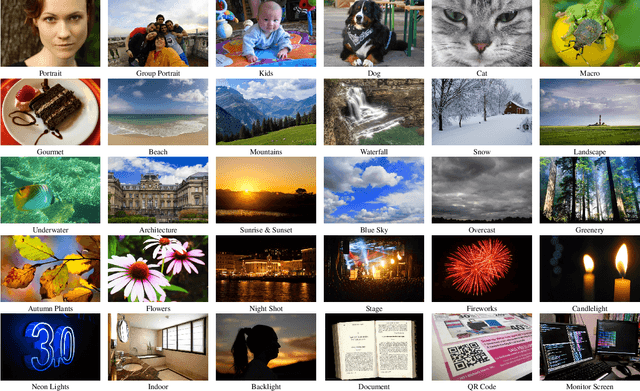
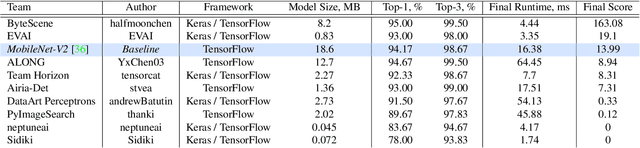

Camera scene detection is among the most popular computer vision problem on smartphones. While many custom solutions were developed for this task by phone vendors, none of the designed models were available publicly up until now. To address this problem, we introduce the first Mobile AI challenge, where the target is to develop quantized deep learning-based camera scene classification solutions that can demonstrate a real-time performance on smartphones and IoT platforms. For this, the participants were provided with a large-scale CamSDD dataset consisting of more than 11K images belonging to the 30 most important scene categories. The runtime of all models was evaluated on the popular Apple Bionic A11 platform that can be found in many iOS devices. The proposed solutions are fully compatible with all major mobile AI accelerators and can demonstrate more than 100-200 FPS on the majority of recent smartphone platforms while achieving a top-3 accuracy of more than 98%. A detailed description of all models developed in the challenge is provided in this paper.
Fast and Accurate Single-Image Depth Estimation on Mobile Devices, Mobile AI 2021 Challenge: Report
May 17, 2021


Depth estimation is an important computer vision problem with many practical applications to mobile devices. While many solutions have been proposed for this task, they are usually very computationally expensive and thus are not applicable for on-device inference. To address this problem, we introduce the first Mobile AI challenge, where the target is to develop an end-to-end deep learning-based depth estimation solutions that can demonstrate a nearly real-time performance on smartphones and IoT platforms. For this, the participants were provided with a new large-scale dataset containing RGB-depth image pairs obtained with a dedicated stereo ZED camera producing high-resolution depth maps for objects located at up to 50 meters. The runtime of all models was evaluated on the popular Raspberry Pi 4 platform with a mobile ARM-based Broadcom chipset. The proposed solutions can generate VGA resolution depth maps at up to 10 FPS on the Raspberry Pi 4 while achieving high fidelity results, and are compatible with any Android or Linux-based mobile devices. A detailed description of all models developed in the challenge is provided in this paper.
Real-Time Video Super-Resolution on Smartphones with Deep Learning, Mobile AI 2021 Challenge: Report
May 17, 2021

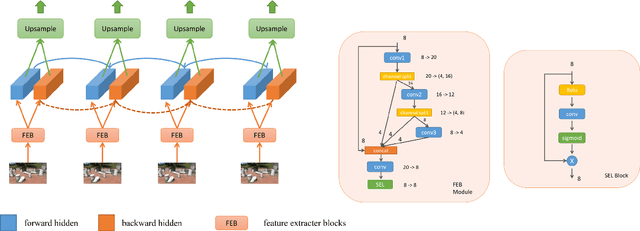
Video super-resolution has recently become one of the most important mobile-related problems due to the rise of video communication and streaming services. While many solutions have been proposed for this task, the majority of them are too computationally expensive to run on portable devices with limited hardware resources. To address this problem, we introduce the first Mobile AI challenge, where the target is to develop an end-to-end deep learning-based video super-resolution solutions that can achieve a real-time performance on mobile GPUs. The participants were provided with the REDS dataset and trained their models to do an efficient 4X video upscaling. The runtime of all models was evaluated on the OPPO Find X2 smartphone with the Snapdragon 865 SoC capable of accelerating floating-point networks on its Adreno GPU. The proposed solutions are fully compatible with any mobile GPU and can upscale videos to HD resolution at up to 80 FPS while demonstrating high fidelity results. A detailed description of all models developed in the challenge is provided in this paper.
Real-Time Quantized Image Super-Resolution on Mobile NPUs, Mobile AI 2021 Challenge: Report
May 17, 2021
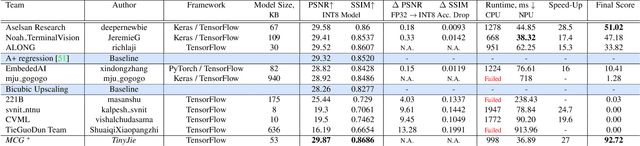
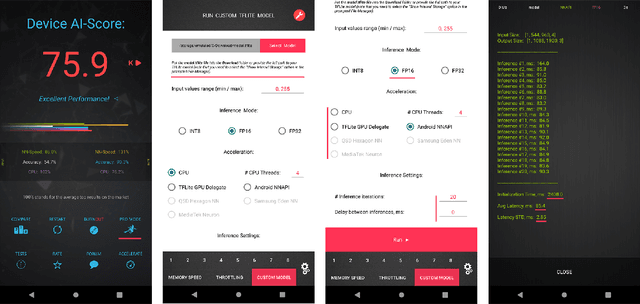
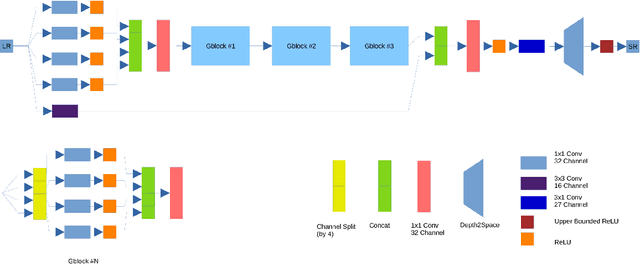
Image super-resolution is one of the most popular computer vision problems with many important applications to mobile devices. While many solutions have been proposed for this task, they are usually not optimized even for common smartphone AI hardware, not to mention more constrained smart TV platforms that are often supporting INT8 inference only. To address this problem, we introduce the first Mobile AI challenge, where the target is to develop an end-to-end deep learning-based image super-resolution solutions that can demonstrate a real-time performance on mobile or edge NPUs. For this, the participants were provided with the DIV2K dataset and trained quantized models to do an efficient 3X image upscaling. The runtime of all models was evaluated on the Synaptics VS680 Smart Home board with a dedicated NPU capable of accelerating quantized neural networks. The proposed solutions are fully compatible with all major mobile AI accelerators and are capable of reconstructing Full HD images under 40-60 ms while achieving high fidelity results. A detailed description of all models developed in the challenge is provided in this paper.
Fast Camera Image Denoising on Mobile GPUs with Deep Learning, Mobile AI 2021 Challenge: Report
May 17, 2021

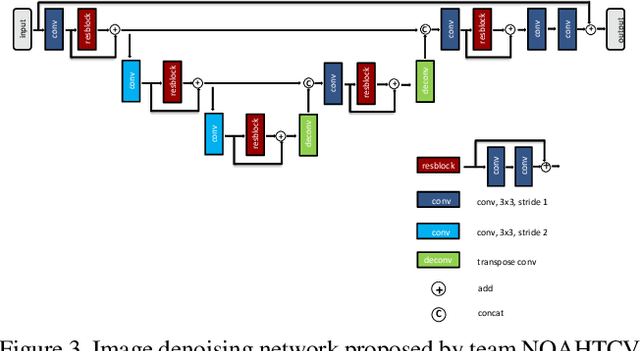
Image denoising is one of the most critical problems in mobile photo processing. While many solutions have been proposed for this task, they are usually working with synthetic data and are too computationally expensive to run on mobile devices. To address this problem, we introduce the first Mobile AI challenge, where the target is to develop an end-to-end deep learning-based image denoising solution that can demonstrate high efficiency on smartphone GPUs. For this, the participants were provided with a novel large-scale dataset consisting of noisy-clean image pairs captured in the wild. The runtime of all models was evaluated on the Samsung Exynos 2100 chipset with a powerful Mali GPU capable of accelerating floating-point and quantized neural networks. The proposed solutions are fully compatible with any mobile GPU and are capable of processing 480p resolution images under 40-80 ms while achieving high fidelity results. A detailed description of all models developed in the challenge is provided in this paper.
Learned Smartphone ISP on Mobile NPUs with Deep Learning, Mobile AI 2021 Challenge: Report
May 17, 2021
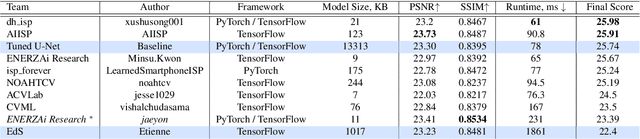
As the quality of mobile cameras starts to play a crucial role in modern smartphones, more and more attention is now being paid to ISP algorithms used to improve various perceptual aspects of mobile photos. In this Mobile AI challenge, the target was to develop an end-to-end deep learning-based image signal processing (ISP) pipeline that can replace classical hand-crafted ISPs and achieve nearly real-time performance on smartphone NPUs. For this, the participants were provided with a novel learned ISP dataset consisting of RAW-RGB image pairs captured with the Sony IMX586 Quad Bayer mobile sensor and a professional 102-megapixel medium format camera. The runtime of all models was evaluated on the MediaTek Dimensity 1000+ platform with a dedicated AI processing unit capable of accelerating both floating-point and quantized neural networks. The proposed solutions are fully compatible with the above NPU and are capable of processing Full HD photos under 60-100 milliseconds while achieving high fidelity results. A detailed description of all models developed in this challenge is provided in this paper.
AIM 2020 Challenge on Learned Image Signal Processing Pipeline
Nov 10, 2020
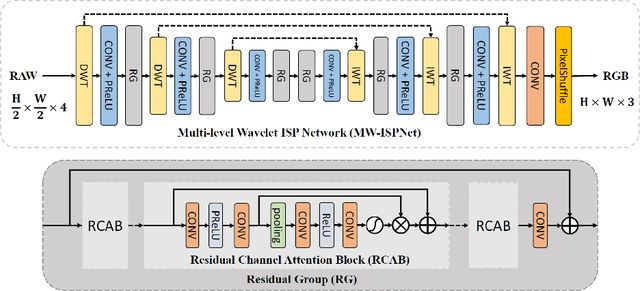
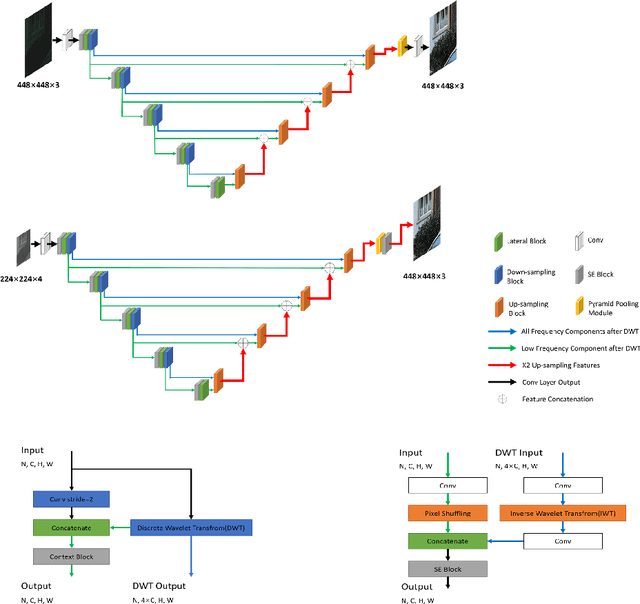
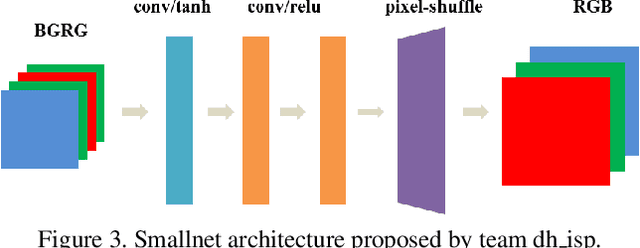
This paper reviews the second AIM learned ISP challenge and provides the description of the proposed solutions and results. The participating teams were solving a real-world RAW-to-RGB mapping problem, where to goal was to map the original low-quality RAW images captured by the Huawei P20 device to the same photos obtained with the Canon 5D DSLR camera. The considered task embraced a number of complex computer vision subtasks, such as image demosaicing, denoising, white balancing, color and contrast correction, demoireing, etc. The target metric used in this challenge combined fidelity scores (PSNR and SSIM) with solutions' perceptual results measured in a user study. The proposed solutions significantly improved the baseline results, defining the state-of-the-art for practical image signal processing pipeline modeling.
AIM 2020 Challenge on Rendering Realistic Bokeh
Nov 10, 2020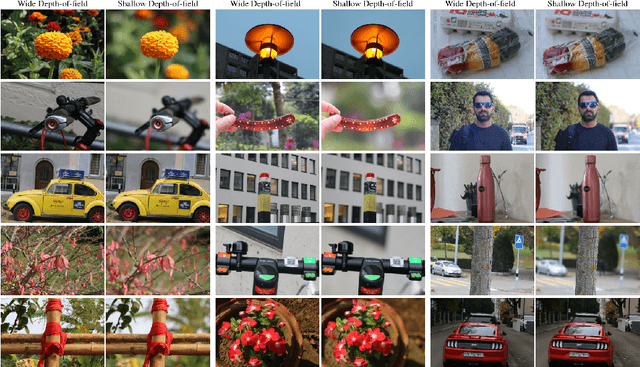


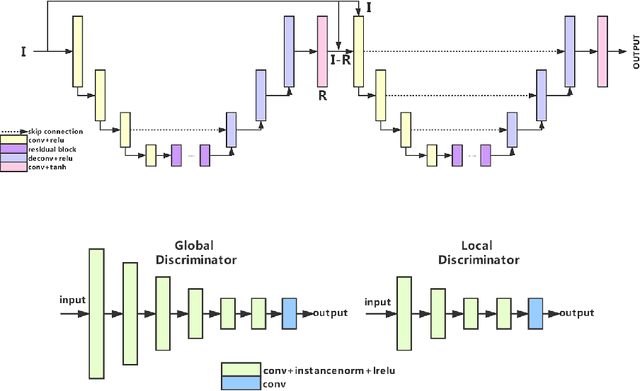
This paper reviews the second AIM realistic bokeh effect rendering challenge and provides the description of the proposed solutions and results. The participating teams were solving a real-world bokeh simulation problem, where the goal was to learn a realistic shallow focus technique using a large-scale EBB! bokeh dataset consisting of 5K shallow / wide depth-of-field image pairs captured using the Canon 7D DSLR camera. The participants had to render bokeh effect based on only one single frame without any additional data from other cameras or sensors. The target metric used in this challenge combined the runtime and the perceptual quality of the solutions measured in the user study. To ensure the efficiency of the submitted models, we measured their runtime on standard desktop CPUs as well as were running the models on smartphone GPUs. The proposed solutions significantly improved the baseline results, defining the state-of-the-art for practical bokeh effect rendering problem.
Controlling Information Capacity of Binary Neural Network
Aug 04, 2020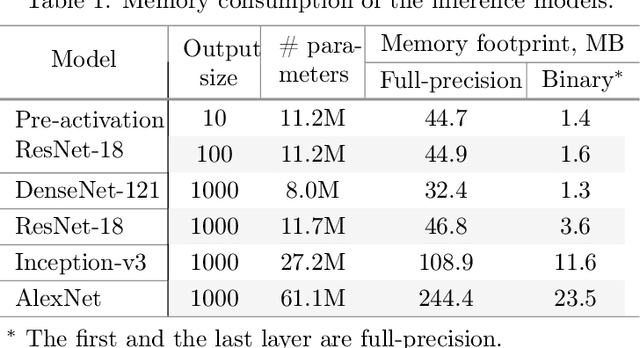
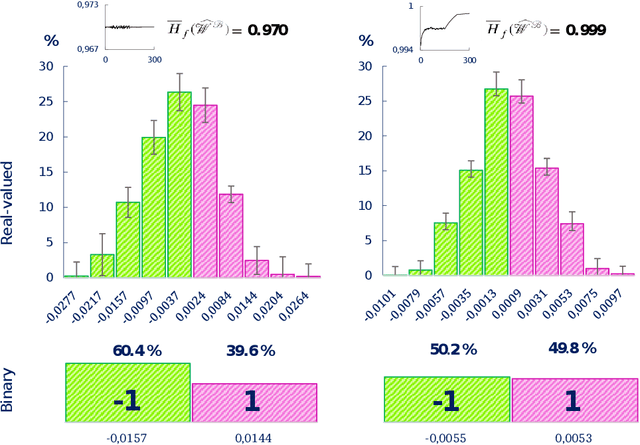
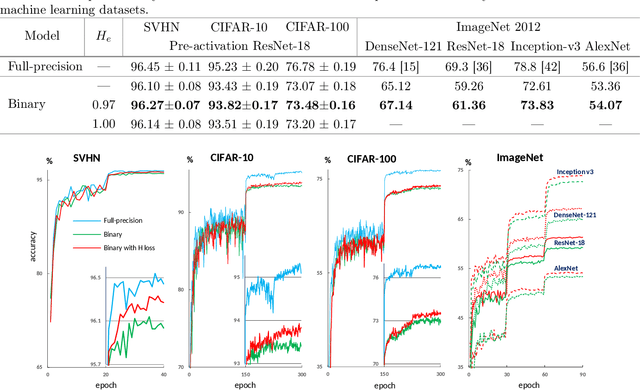
Despite the growing popularity of deep learning technologies, high memory requirements and power consumption are essentially limiting their application in mobile and IoT areas. While binary convolutional networks can alleviate these problems, the limited bitwidth of weights is often leading to significant degradation of prediction accuracy. In this paper, we present a method for training binary networks that maintains a stable predefined level of their information capacity throughout the training process by applying Shannon entropy based penalty to convolutional filters. The results of experiments conducted on SVHN, CIFAR and ImageNet datasets demonstrate that the proposed approach can statistically significantly improve the accuracy of binary networks.