 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMicroISP: Processing 32MP Photos on Mobile Devices with Deep Learning
Nov 08, 2022



While neural networks-based photo processing solutions can provide a better image quality compared to the traditional ISP systems, their application to mobile devices is still very limited due to their very high computational complexity. In this paper, we present a novel MicroISP model designed specifically for edge devices, taking into account their computational and memory limitations. The proposed solution is capable of processing up to 32MP photos on recent smartphones using the standard mobile ML libraries and requiring less than 1 second to perform the inference, while for FullHD images it achieves real-time performance. The architecture of the model is flexible, allowing to adjust its complexity to devices of different computational power. To evaluate the performance of the model, we collected a novel Fujifilm UltraISP dataset consisting of thousands of paired photos captured with a normal mobile camera sensor and a professional 102MP medium-format FujiFilm GFX100 camera. The experiments demonstrated that, despite its compact size, the MicroISP model is able to provide comparable or better visual results than the traditional mobile ISP systems, while outperforming the previously proposed efficient deep learning based solutions. Finally, this model is also compatible with the latest mobile AI accelerators, achieving good runtime and low power consumption on smartphone NPUs and APUs. The code, dataset and pre-trained models are available on the project website: https://people.ee.ethz.ch/~ihnatova/microisp.html
PyNet-V2 Mobile: Efficient On-Device Photo Processing With Neural Networks
Nov 08, 2022The increased importance of mobile photography created a need for fast and performant RAW image processing pipelines capable of producing good visual results in spite of the mobile camera sensor limitations. While deep learning-based approaches can efficiently solve this problem, their computational requirements usually remain too large for high-resolution on-device image processing. To address this limitation, we propose a novel PyNET-V2 Mobile CNN architecture designed specifically for edge devices, being able to process RAW 12MP photos directly on mobile phones under 1.5 second and producing high perceptual photo quality. To train and to evaluate the performance of the proposed solution, we use the real-world Fujifilm UltraISP dataset consisting on thousands of RAW-RGB image pairs captured with a professional medium-format 102MP Fujifilm camera and a popular Sony mobile camera sensor. The results demonstrate that the PyNET-V2 Mobile model can substantially surpass the quality of tradition ISP pipelines, while outperforming the previously introduced neural network-based solutions designed for fast image processing. Furthermore, we show that the proposed architecture is also compatible with the latest mobile AI accelerators such as NPUs or APUs that can be used to further reduce the latency of the model to as little as 0.5 second. The dataset, code and pre-trained models used in this paper are available on the project website: https://github.com/gmalivenko/PyNET-v2
Power Efficient Video Super-Resolution on Mobile NPUs with Deep Learning, Mobile AI & AIM 2022 challenge: Report
Nov 07, 2022



Video super-resolution is one of the most popular tasks on mobile devices, being widely used for an automatic improvement of low-bitrate and low-resolution video streams. While numerous solutions have been proposed for this problem, they are usually quite computationally demanding, demonstrating low FPS rates and power efficiency on mobile devices. In this Mobile AI challenge, we address this problem and propose the participants to design an end-to-end real-time video super-resolution solution for mobile NPUs optimized for low energy consumption. The participants were provided with the REDS training dataset containing video sequences for a 4X video upscaling task. The runtime and power efficiency of all models was evaluated on the powerful MediaTek Dimensity 9000 platform with a dedicated AI processing unit capable of accelerating floating-point and quantized neural networks. All proposed solutions are fully compatible with the above NPU, demonstrating an up to 500 FPS rate and 0.2 [Watt / 30 FPS] power consumption. A detailed description of all models developed in the challenge is provided in this paper.
Learned Smartphone ISP on Mobile NPUs with Deep Learning, Mobile AI 2021 Challenge: Report
May 17, 2021
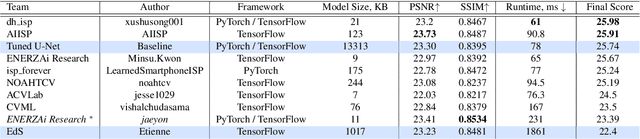
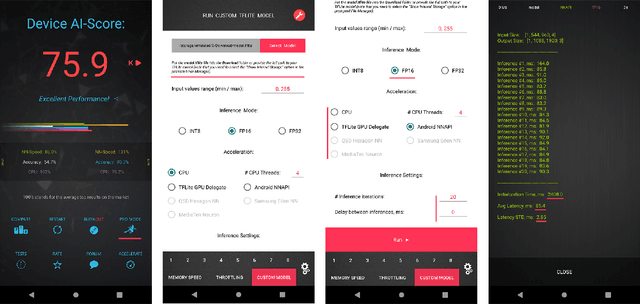
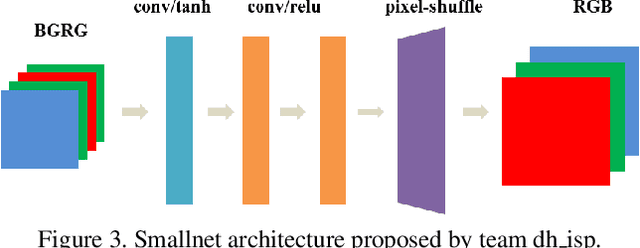
As the quality of mobile cameras starts to play a crucial role in modern smartphones, more and more attention is now being paid to ISP algorithms used to improve various perceptual aspects of mobile photos. In this Mobile AI challenge, the target was to develop an end-to-end deep learning-based image signal processing (ISP) pipeline that can replace classical hand-crafted ISPs and achieve nearly real-time performance on smartphone NPUs. For this, the participants were provided with a novel learned ISP dataset consisting of RAW-RGB image pairs captured with the Sony IMX586 Quad Bayer mobile sensor and a professional 102-megapixel medium format camera. The runtime of all models was evaluated on the MediaTek Dimensity 1000+ platform with a dedicated AI processing unit capable of accelerating both floating-point and quantized neural networks. The proposed solutions are fully compatible with the above NPU and are capable of processing Full HD photos under 60-100 milliseconds while achieving high fidelity results. A detailed description of all models developed in this challenge is provided in this paper.
Answer-checking in Context: A Multi-modal FullyAttention Network for Visual Question Answering
Oct 17, 2020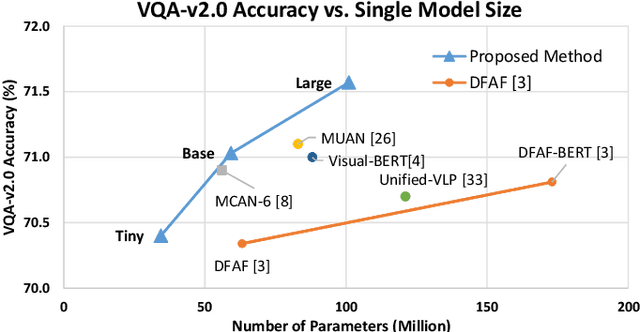
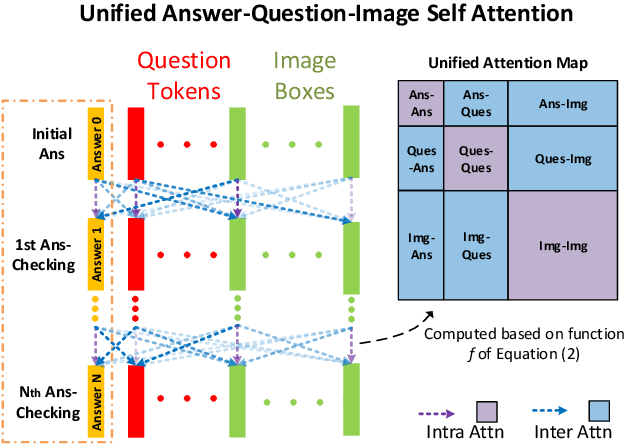
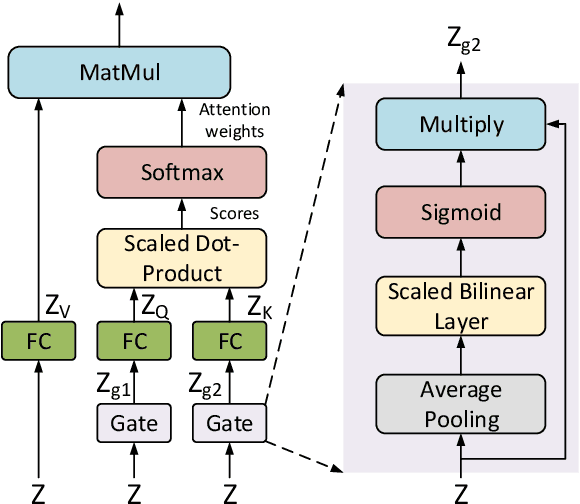
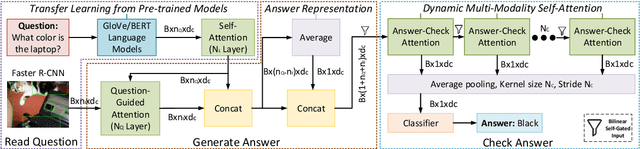
Visual Question Answering (VQA) is challenging due to the complex cross-modal relations. It has received extensive attention from the research community. From the human perspective, to answer a visual question, one needs to read the question and then refer to the image to generate an answer. This answer will then be checked against the question and image again for the final confirmation. In this paper, we mimic this process and propose a fully attention based VQA architecture. Moreover, an answer-checking module is proposed to perform a unified attention on the jointly answer, question and image representation to update the answer. This mimics the human answer checking process to consider the answer in the context. With answer-checking modules and transferred BERT layers, our model achieves the state-of-the-art accuracy 71.57\% using fewer parameters on VQA-v2.0 test-standard split.
Deploying Image Deblurring across Mobile Devices: A Perspective of Quality and Latency
Apr 27, 2020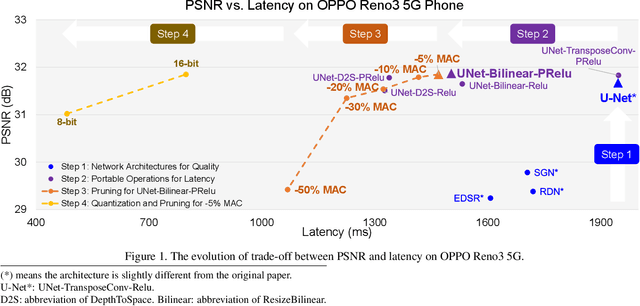
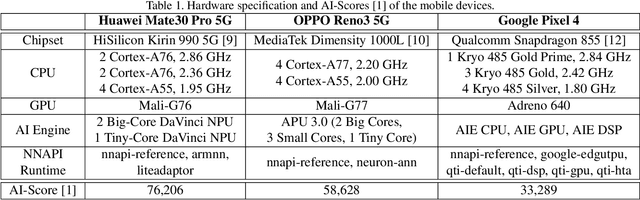
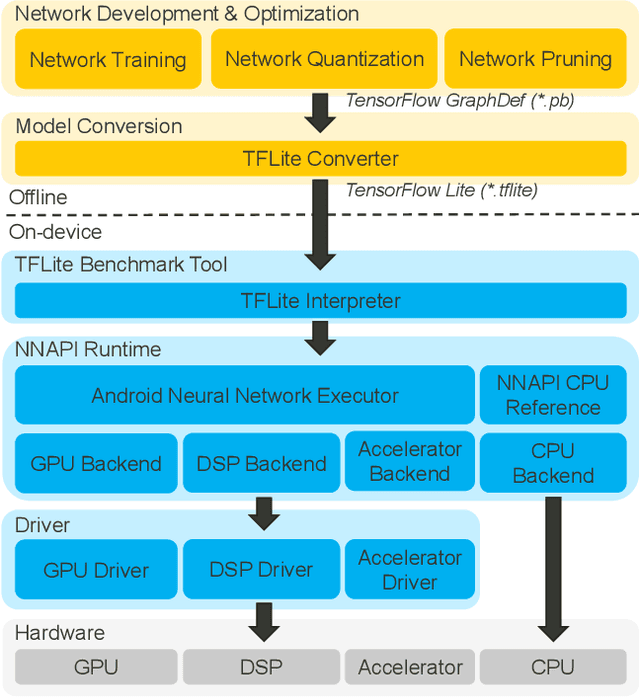
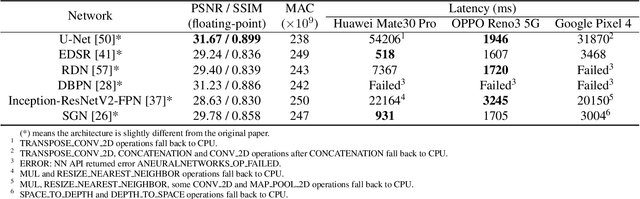
Recently, image enhancement and restoration have become important applications on mobile devices, such as super-resolution and image deblurring. However, most state-of-the-art networks present extremely high computational complexity. This makes them difficult to be deployed on mobile devices with acceptable latency. Moreover, when deploying to different mobile devices, there is a large latency variation due to the difference and limitation of deep learning accelerators on mobile devices. In this paper, we conduct a search of portable network architectures for better quality-latency trade-off across mobile devices. We further present the effectiveness of widely used network optimizations for image deblurring task. This paper provides comprehensive experiments and comparisons to uncover the in-depth analysis for both latency and image quality. Through all the above works, we demonstrate the successful deployment of image deblurring application on mobile devices with the acceleration of deep learning accelerators. To the best of our knowledge, this is the first paper that addresses all the deployment issues of image deblurring task across mobile devices. This paper provides practical deployment-guidelines, and is adopted by the championship-winning team in NTIRE 2020 Image Deblurring Challenge on Smartphone Track.
Architecture-aware Network Pruning for Vision Quality Applications
Aug 05, 2019
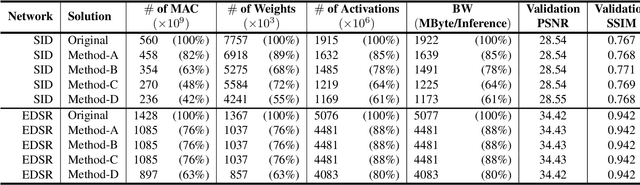
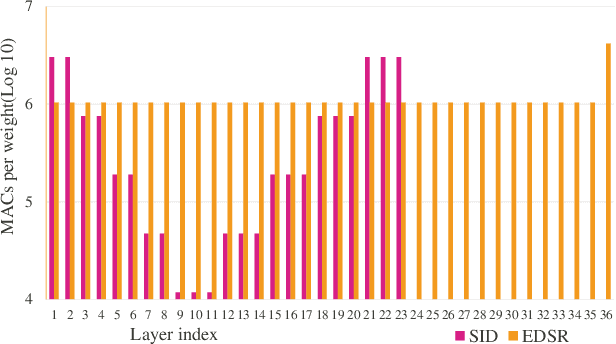
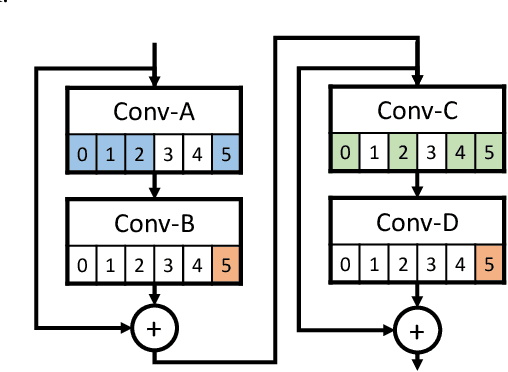
Convolutional neural network (CNN) delivers impressive achievements in computer vision and machine learning field. However, CNN incurs high computational complexity, especially for vision quality applications because of large image resolution. In this paper, we propose an iterative architecture-aware pruning algorithm with adaptive magnitude threshold while cooperating with quality-metric measurement simultaneously. We show the performance improvement applied on vision quality applications and provide comprehensive analysis with flexible pruning configuration. With the proposed method, the Multiply-Accumulate (MAC) of state-of-the-art low-light imaging (SID) and super-resolution (EDSR) are reduced by 58% and 37% without quality drop, respectively. The memory bandwidth (BW) requirements of convolutional layer can be also reduced by 20% to 40%.