 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCulinaryCut-VLAP: A Vision-Language-Action-Physics Framework for Food Cutting via a Force-Aware Material Point Method
Jan 10, 2026Food cutting is a highly practical yet underexplored application at the intersection of vision and robotic manipulation. The task remains challenging because interactions between the knife and deformable materials are highly nonlinear and often entail large deformations, frequent contact, and topological change, which in turn hinder stable and safe large-scale data collection. To address these challenges, we propose a unified framework that couples a vision-language-action (VLA) dataset with a physically realistic cutting simulator built on the material point method (MPM). Our simulator adopts MLS-MPM as its computational core, reducing numerical dissipation and energy drift while preserving rotational and shear responses even under topology-changing cuts. During cutting, forces and stress distributions are estimated from impulse exchanges between particles and the grid, enabling stable tracking of transient contact forces and energy transfer. We also provide a benchmark dataset that integrates diverse cutting trajectories, multi-view visual observations, and fine-grained language instructions, together with force--torque and tool--pose labels to provide physically consistent training signals. These components realize a learning--evaluation loop that respects the core physics of cutting and establishes a safe, reproducible, and scalable foundation for advancing VLA models in deformable object manipulation.
Learning with Noisy Labels: Interconnection of Two Expectation-Maximizations
Jan 09, 2024Labor-intensive labeling becomes a bottleneck in developing computer vision algorithms based on deep learning. For this reason, dealing with imperfect labels has increasingly gained attention and has become an active field of study. We address learning with noisy labels (LNL) problem, which is formalized as a task of finding a structured manifold in the midst of noisy data. In this framework, we provide a proper objective function and an optimization algorithm based on two expectation-maximization (EM) cycles. The separate networks associated with the two EM cycles collaborate to optimize the objective function, where one model is for distinguishing clean labels from corrupted ones while the other is for refurbishing the corrupted labels. This approach results in a non-collapsing LNL-flywheel model in the end. Experiments show that our algorithm achieves state-of-the-art performance in multiple standard benchmarks with substantial margins under various types of label noise.
CADyQ: Content-Aware Dynamic Quantization for Image Super-Resolution
Jul 21, 2022
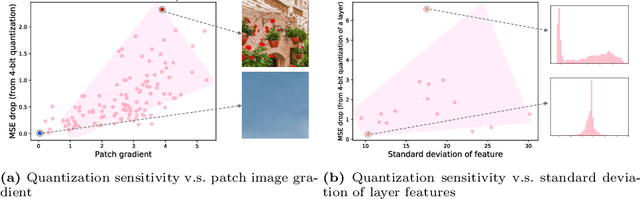
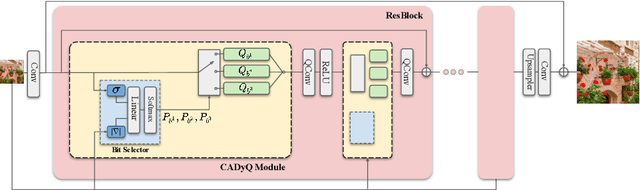
Despite breakthrough advances in image super-resolution (SR) with convolutional neural networks (CNNs), SR has yet to enjoy ubiquitous applications due to the high computational complexity of SR networks. Quantization is one of the promising approaches to solve this problem. However, existing methods fail to quantize SR models with a bit-width lower than 8 bits, suffering from severe accuracy loss due to fixed bit-width quantization applied everywhere. In this work, to achieve high average bit-reduction with less accuracy loss, we propose a novel Content-Aware Dynamic Quantization (CADyQ) method for SR networks that allocates optimal bits to local regions and layers adaptively based on the local contents of an input image. To this end, a trainable bit selector module is introduced to determine the proper bit-width and quantization level for each layer and a given local image patch. This module is governed by the quantization sensitivity that is estimated by using both the average magnitude of image gradient of the patch and the standard deviation of the input feature of the layer. The proposed quantization pipeline has been tested on various SR networks and evaluated on several standard benchmarks extensively. Significant reduction in computational complexity and the elevated restoration accuracy clearly demonstrate the effectiveness of the proposed CADyQ framework for SR. Codes are available at https://github.com/Cheeun/CADyQ.
Controllable Image Enhancement
Jun 16, 2022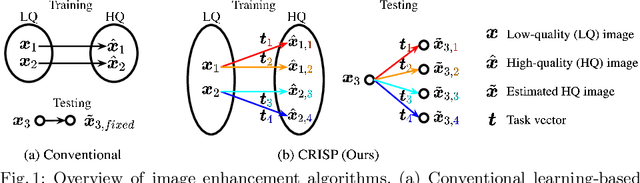
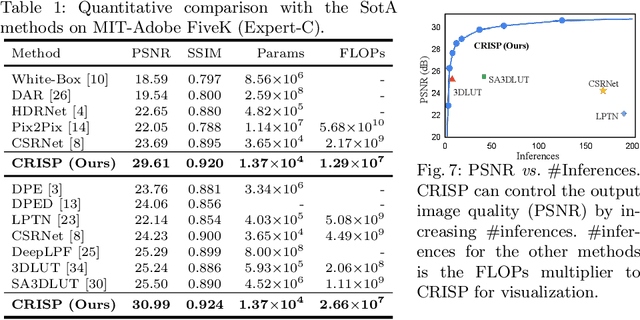
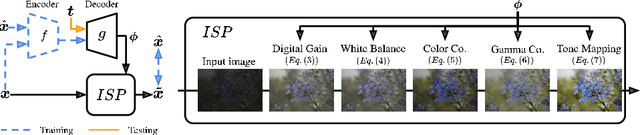

Editing flat-looking images into stunning photographs requires skill and time. Automated image enhancement algorithms have attracted increased interest by generating high-quality images without user interaction. However, the quality assessment of a photograph is subjective. Even in tone and color adjustments, a single photograph of auto-enhancement is challenging to fit user preferences which are subtle and even changeable. To address this problem, we present a semiautomatic image enhancement algorithm that can generate high-quality images with multiple styles by controlling a few parameters. We first disentangle photo retouching skills from high-quality images and build an efficient enhancement system for each skill. Specifically, an encoder-decoder framework encodes the retouching skills into latent codes and decodes them into the parameters of image signal processing (ISP) functions. The ISP functions are computationally efficient and consist of only 19 parameters. Despite our approach requiring multiple inferences to obtain the desired result, experimental results present that the proposed method achieves state-of-the-art performances on the benchmark dataset for image quality and model efficiency.
Attentive Fine-Grained Structured Sparsity for Image Restoration
Apr 26, 2022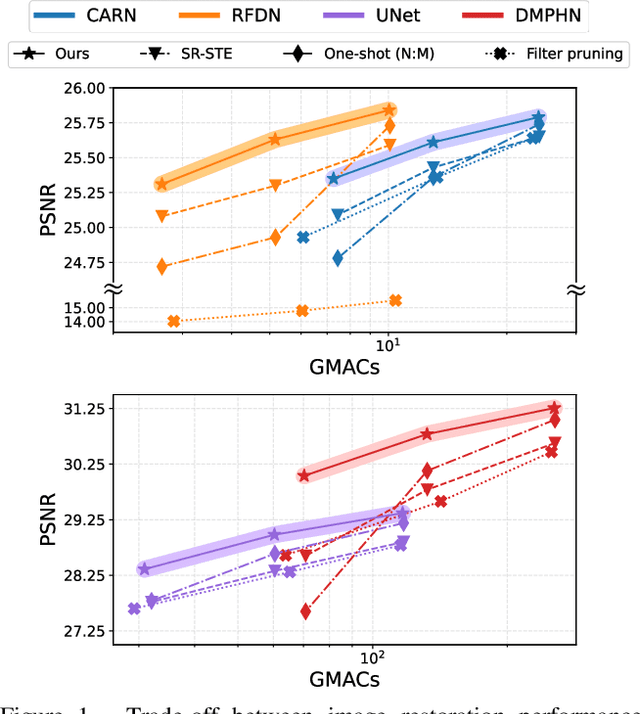
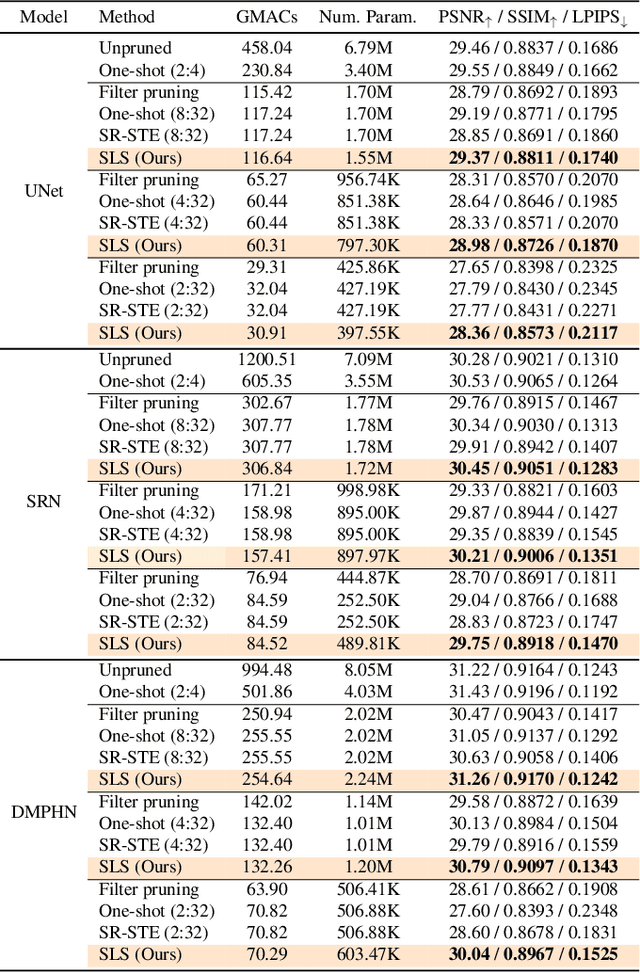
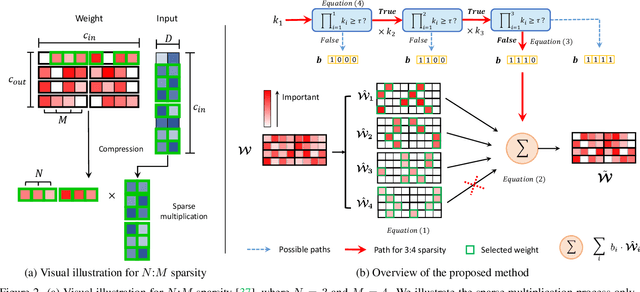
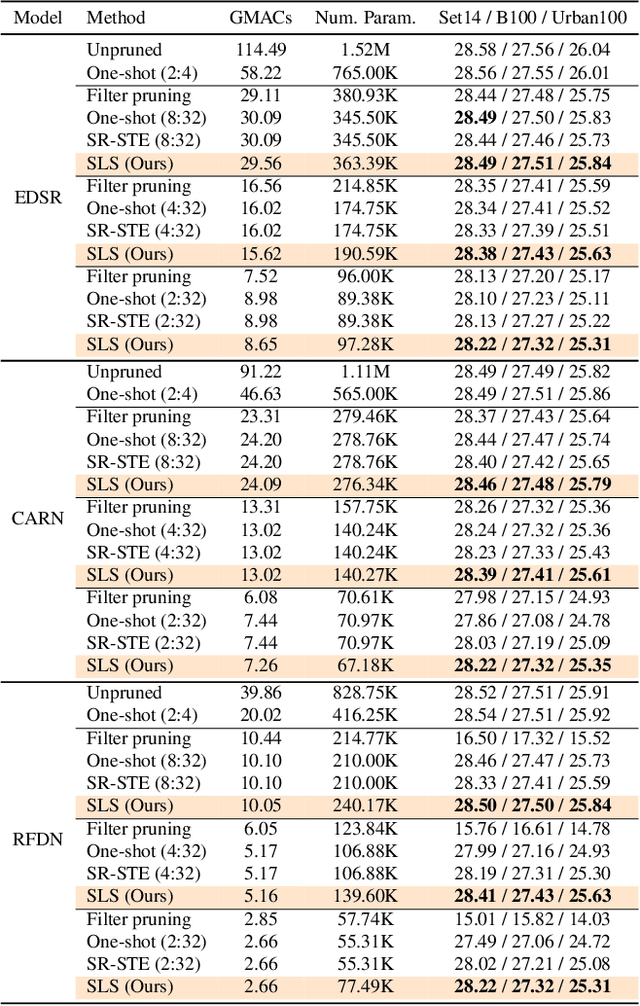
Image restoration tasks have witnessed great performance improvement in recent years by developing large deep models. Despite the outstanding performance, the heavy computation demanded by the deep models has restricted the application of image restoration. To lift the restriction, it is required to reduce the size of the networks while maintaining accuracy. Recently, N:M structured pruning has appeared as one of the effective and practical pruning approaches for making the model efficient with the accuracy constraint. However, it fails to account for different computational complexities and performance requirements for different layers of an image restoration network. To further optimize the trade-off between the efficiency and the restoration accuracy, we propose a novel pruning method that determines the pruning ratio for N:M structured sparsity at each layer. Extensive experimental results on super-resolution and deblurring tasks demonstrate the efficacy of our method which outperforms previous pruning methods significantly. PyTorch implementation for the proposed methods will be publicly available at https://github.com/JungHunOh/SLS_CVPR2022.
Batch Normalization Tells You Which Filter is Important
Dec 02, 2021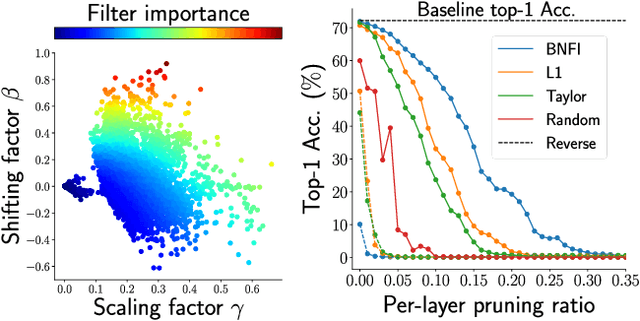
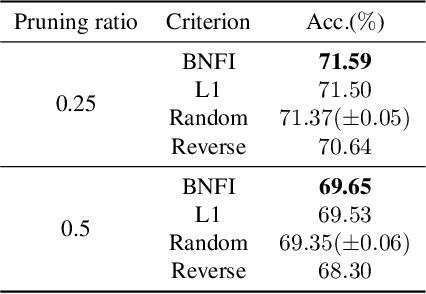
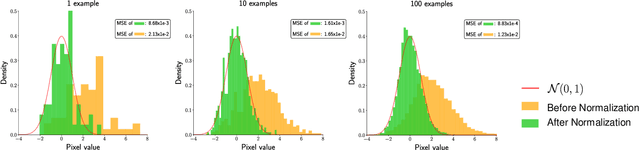
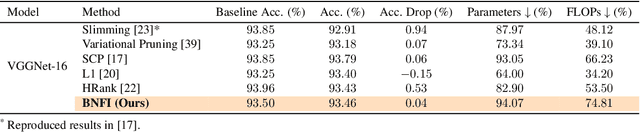
The goal of filter pruning is to search for unimportant filters to remove in order to make convolutional neural networks (CNNs) efficient without sacrificing the performance in the process. The challenge lies in finding information that can help determine how important or relevant each filter is with respect to the final output of neural networks. In this work, we share our observation that the batch normalization (BN) parameters of pre-trained CNNs can be used to estimate the feature distribution of activation outputs, without processing of training data. Upon observation, we propose a simple yet effective filter pruning method by evaluating the importance of each filter based on the BN parameters of pre-trained CNNs. The experimental results on CIFAR-10 and ImageNet demonstrate that the proposed method can achieve outstanding performance with and without fine-tuning in terms of the trade-off between the accuracy drop and the reduction in computational complexity and number of parameters of pruned networks.
Meta-Learning with Task-Adaptive Loss Function for Few-Shot Learning
Oct 17, 2021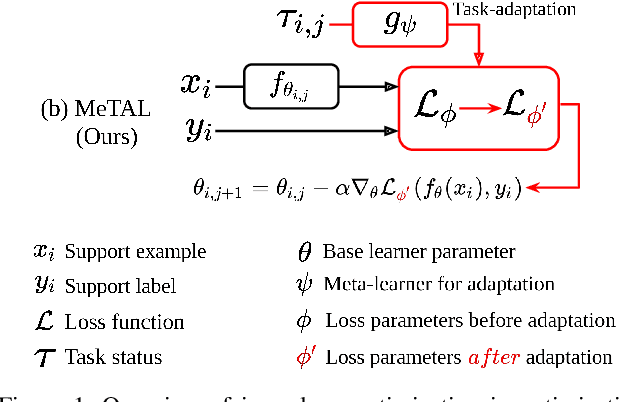
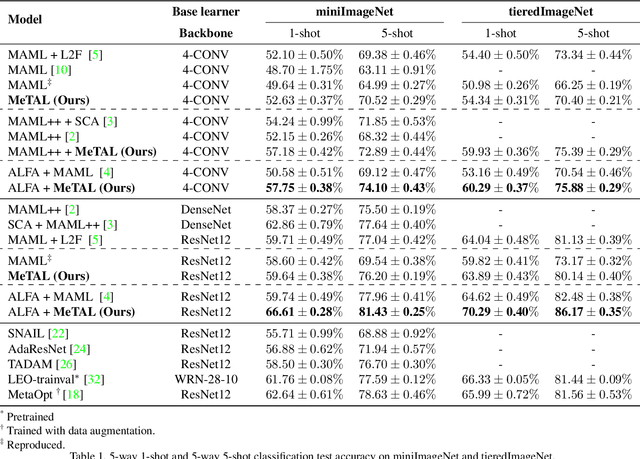
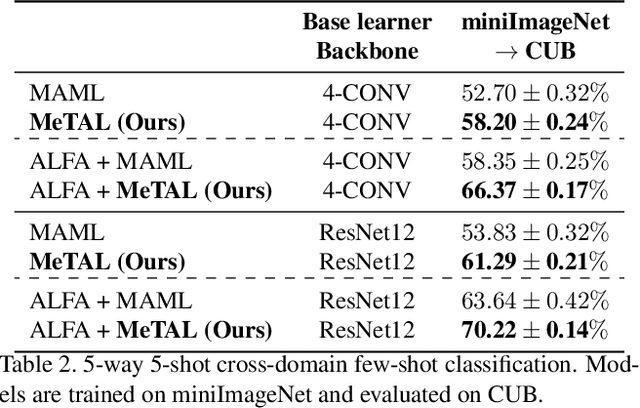
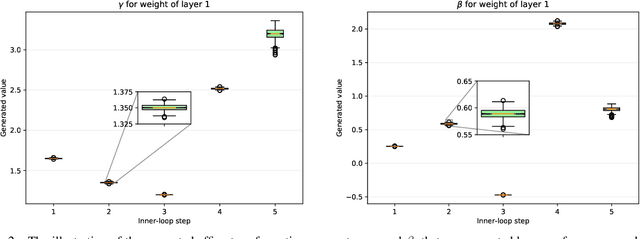
In few-shot learning scenarios, the challenge is to generalize and perform well on new unseen examples when only very few labeled examples are available for each task. Model-agnostic meta-learning (MAML) has gained the popularity as one of the representative few-shot learning methods for its flexibility and applicability to diverse problems. However, MAML and its variants often resort to a simple loss function without any auxiliary loss function or regularization terms that can help achieve better generalization. The problem lies in that each application and task may require different auxiliary loss function, especially when tasks are diverse and distinct. Instead of attempting to hand-design an auxiliary loss function for each application and task, we introduce a new meta-learning framework with a loss function that adapts to each task. Our proposed framework, named Meta-Learning with Task-Adaptive Loss Function (MeTAL), demonstrates the effectiveness and the flexibility across various domains, such as few-shot classification and few-shot regression.
Real-Time Video Super-Resolution on Smartphones with Deep Learning, Mobile AI 2021 Challenge: Report
May 17, 2021

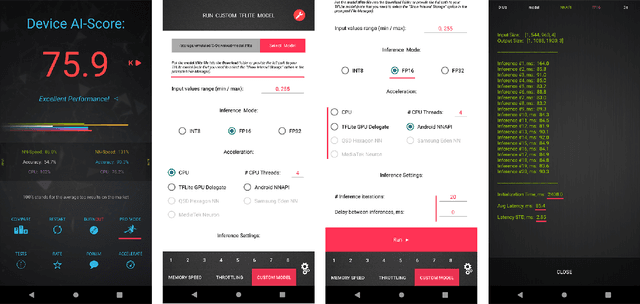
Video super-resolution has recently become one of the most important mobile-related problems due to the rise of video communication and streaming services. While many solutions have been proposed for this task, the majority of them are too computationally expensive to run on portable devices with limited hardware resources. To address this problem, we introduce the first Mobile AI challenge, where the target is to develop an end-to-end deep learning-based video super-resolution solutions that can achieve a real-time performance on mobile GPUs. The participants were provided with the REDS dataset and trained their models to do an efficient 4X video upscaling. The runtime of all models was evaluated on the OPPO Find X2 smartphone with the Snapdragon 865 SoC capable of accelerating floating-point networks on its Adreno GPU. The proposed solutions are fully compatible with any mobile GPU and can upscale videos to HD resolution at up to 80 FPS while demonstrating high fidelity results. A detailed description of all models developed in the challenge is provided in this paper.
DAQ: Distribution-Aware Quantization for Deep Image Super-Resolution Networks
Dec 21, 2020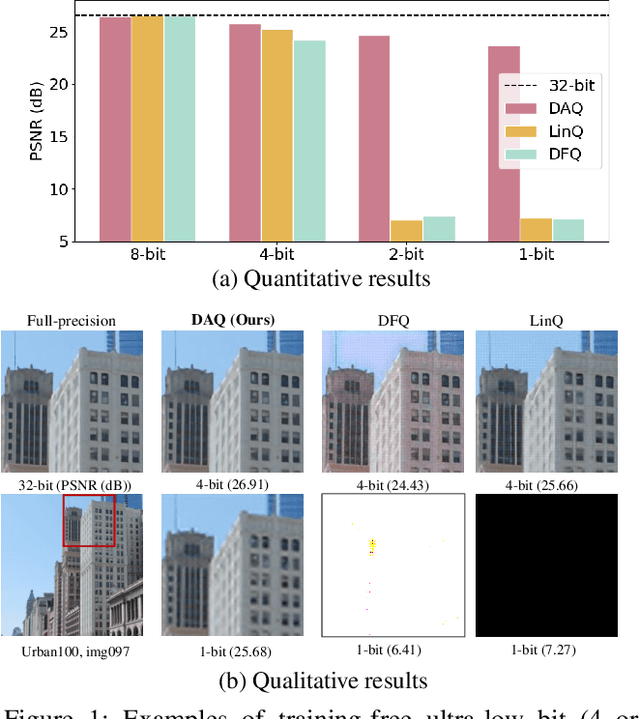

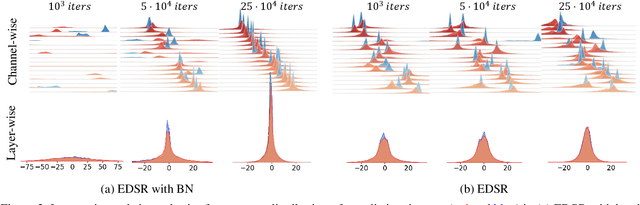
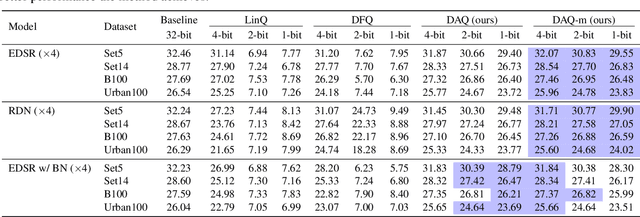
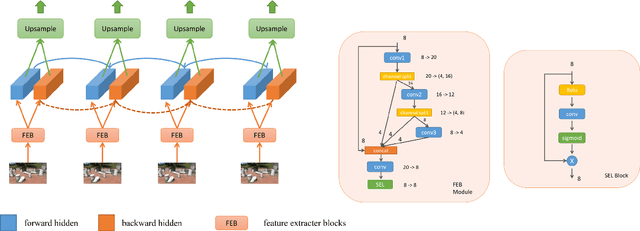
Quantizing deep convolutional neural networks for image super-resolution substantially reduces their computational costs. However, existing works either suffer from a severe performance drop in ultra-low precision of 4 or lower bit-widths, or require a heavy fine-tuning process to recover the performance. To our knowledge, this vulnerability to low precisions relies on two statistical observations of feature map values. First, distribution of feature map values varies significantly per channel and per input image. Second, feature maps have outliers that can dominate the quantization error. Based on these observations, we propose a novel distribution-aware quantization scheme (DAQ) which facilitates accurate training-free quantization in ultra-low precision. A simple function of DAQ determines dynamic range of feature maps and weights with low computational burden. Furthermore, our method enables mixed-precision quantization by calculating the relative sensitivity of each channel, without any training process involved. Nonetheless, quantization-aware training is also applicable for auxiliary performance gain. Our new method outperforms recent training-free and even training-based quantization methods to the state-of-the-art image super-resolution networks in ultra-low precision.
Searching for Controllable Image Restoration Networks
Dec 21, 2020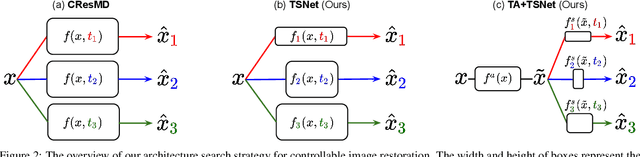
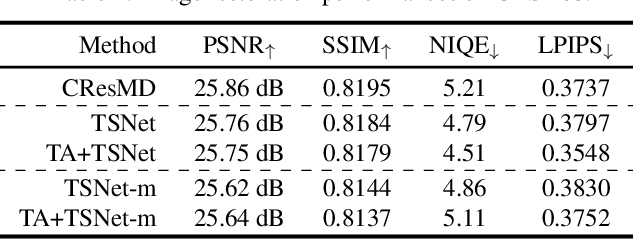
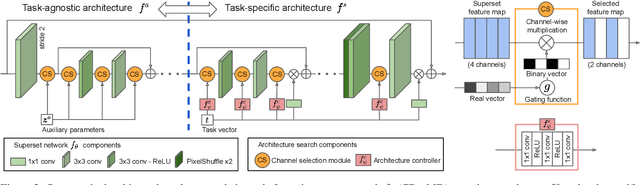
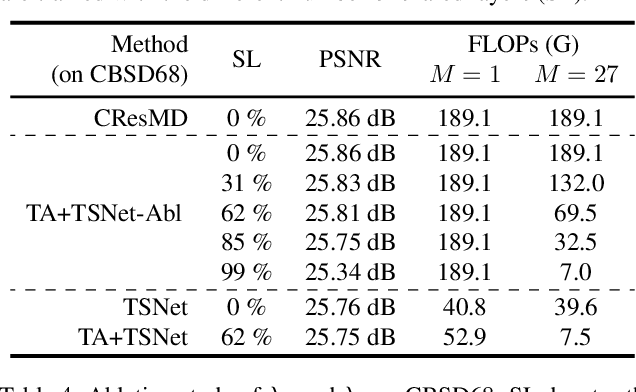
Diverse user preferences over images have recently led to a great amount of interest in controlling the imagery effects for image restoration tasks. However, existing methods require separate inference through the entire network per each output, which hinders users from readily comparing multiple imagery effects due to long latency. To this end, we propose a novel framework based on a neural architecture search technique that enables efficient generation of multiple imagery effects via two stages of pruning: task-agnostic and task-specific pruning. Specifically, task-specific pruning learns to adaptively remove the irrelevant network parameters for each task, while task-agnostic pruning learns to find an efficient architecture by sharing the early layers of the network across different tasks. Since the shared layers allow for feature reuse, only a single inference of the task-agnostic layers is needed to generate multiple imagery effects from the input image. Using the proposed task-agnostic and task-specific pruning schemes together significantly reduces the FLOPs and the actual latency of inference compared to the baseline. We reduce 95.7% of the FLOPs when generating 27 imagery effects, and make the GPU latency 73.0% faster on 4K-resolution images.