 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2026 Challenge on Single Image Reflection Removal in the Wild: Datasets, Results, and Methods
Apr 11, 2026In this paper, we review the NTIRE 2026 challenge on single-image reflection removal (SIRR) in the Wild. SIRR is a fundamental task in image restoration. Despite progress in academic research, most methods are tested on synthetic images or limited real-world images, creating a gap in real-world applications. In this challenge, we provide participants with the OpenRR-5k dataset, which requires them to process real-world images that cover a range of reflection scenarios and intensities, with the goal of generating clean images without reflections. The challenge attracted more than 100 registrations, with 11 of them participating in the final testing phase. The top-ranked methods advanced the state-of-the-art reflection removal performance and earned unanimous recognition from the five experts in the field. The proposed OpenRR-5k dataset is available at https://huggingface.co/datasets/qiuzhangTiTi/OpenRR-5k, and the homepage of this challenge is at https://github.com/caijie0620/OpenRR-5k. Due to page limitations, this article only presents partial content; the full report and detailed analyses are available in the extended arXiv version.
OpenRR-1k: A Scalable Dataset for Real-World Reflection Removal
Jun 10, 2025Reflection removal technology plays a crucial role in photography and computer vision applications. However, existing techniques are hindered by the lack of high-quality in-the-wild datasets. In this paper, we propose a novel paradigm for collecting reflection datasets from a fresh perspective. Our approach is convenient, cost-effective, and scalable, while ensuring that the collected data pairs are of high quality, perfectly aligned, and represent natural and diverse scenarios. Following this paradigm, we collect a Real-world, Diverse, and Pixel-aligned dataset (named OpenRR-1k dataset), which contains 1,000 high-quality transmission-reflection image pairs collected in the wild. Through the analysis of several reflection removal methods and benchmark evaluation experiments on our dataset, we demonstrate its effectiveness in improving robustness in challenging real-world environments. Our dataset is available at https://github.com/caijie0620/OpenRR-1k.
F2T2-HiT: A U-Shaped FFT Transformer and Hierarchical Transformer for Reflection Removal
Jun 05, 2025Single Image Reflection Removal (SIRR) technique plays a crucial role in image processing by eliminating unwanted reflections from the background. These reflections, often caused by photographs taken through glass surfaces, can significantly degrade image quality. SIRR remains a challenging problem due to the complex and varied reflections encountered in real-world scenarios. These reflections vary significantly in intensity, shapes, light sources, sizes, and coverage areas across the image, posing challenges for most existing methods to effectively handle all cases. To address these challenges, this paper introduces a U-shaped Fast Fourier Transform Transformer and Hierarchical Transformer (F2T2-HiT) architecture, an innovative Transformer-based design for SIRR. Our approach uniquely combines Fast Fourier Transform (FFT) Transformer blocks and Hierarchical Transformer blocks within a UNet framework. The FFT Transformer blocks leverage the global frequency domain information to effectively capture and separate reflection patterns, while the Hierarchical Transformer blocks utilize multi-scale feature extraction to handle reflections of varying sizes and complexities. Extensive experiments conducted on three publicly available testing datasets demonstrate state-of-the-art performance, validating the effectiveness of our approach.
Degradation-Aware Image Enhancement via Vision-Language Classification
Jun 05, 2025Image degradation is a prevalent issue in various real-world applications, affecting visual quality and downstream processing tasks. In this study, we propose a novel framework that employs a Vision-Language Model (VLM) to automatically classify degraded images into predefined categories. The VLM categorizes an input image into one of four degradation types: (A) super-resolution degradation (including noise, blur, and JPEG compression), (B) reflection artifacts, (C) motion blur, or (D) no visible degradation (high-quality image). Once classified, images assigned to categories A, B, or C undergo targeted restoration using dedicated models tailored for each specific degradation type. The final output is a restored image with improved visual quality. Experimental results demonstrate the effectiveness of our approach in accurately classifying image degradations and enhancing image quality through specialized restoration models. Our method presents a scalable and automated solution for real-world image enhancement tasks, leveraging the capabilities of VLMs in conjunction with state-of-the-art restoration techniques.
OpenRR-5k: A Large-Scale Benchmark for Reflection Removal in the Wild
Jun 05, 2025Removing reflections is a crucial task in computer vision, with significant applications in photography and image enhancement. Nevertheless, existing methods are constrained by the absence of large-scale, high-quality, and diverse datasets. In this paper, we present a novel benchmark for Single Image Reflection Removal (SIRR). We have developed a large-scale dataset containing 5,300 high-quality, pixel-aligned image pairs, each consisting of a reflection image and its corresponding clean version. Specifically, the dataset is divided into two parts: 5,000 images are used for training, and 300 images are used for validation. Additionally, we have included 100 real-world testing images without ground truth (GT) to further evaluate the practical performance of reflection removal methods. All image pairs are precisely aligned at the pixel level to guarantee accurate supervision. The dataset encompasses a broad spectrum of real-world scenarios, featuring various lighting conditions, object types, and reflection patterns, and is segmented into training, validation, and test sets to facilitate thorough evaluation. To validate the usefulness of our dataset, we train a U-Net-based model and evaluate it using five widely-used metrics, including PSNR, SSIM, LPIPS, DISTS, and NIQE. We will release both the dataset and the code on https://github.com/caijie0620/OpenRR-5k to facilitate future research in this field.
Survey on Single-Image Reflection Removal using Deep Learning Techniques
Feb 12, 2025The phenomenon of reflection is quite common in digital images, posing significant challenges for various applications such as computer vision, photography, and image processing. Traditional methods for reflection removal often struggle to achieve clean results while maintaining high fidelity and robustness, particularly in real-world scenarios. Over the past few decades, numerous deep learning-based approaches for reflection removal have emerged, yielding impressive results. In this survey, we conduct a comprehensive review of the current literature by focusing on key venues such as ICCV, ECCV, CVPR, NeurIPS, etc., as these conferences and journals have been central to advances in the field. Our review follows a structured paper selection process, and we critically assess both single-stage and two-stage deep learning methods for reflection removal. The contribution of this survey is three-fold: first, we provide a comprehensive summary of the most recent work on single-image reflection removal; second, we outline task hypotheses, current deep learning techniques, publicly available datasets, and relevant evaluation metrics; and third, we identify key challenges and opportunities in deep learning-based reflection removal, highlighting the potential of this rapidly evolving research area.
EVD4UAV: An Altitude-Sensitive Benchmark to Evade Vehicle Detection in UAV
Mar 08, 2024



Vehicle detection in Unmanned Aerial Vehicle (UAV) captured images has wide applications in aerial photography and remote sensing. There are many public benchmark datasets proposed for the vehicle detection and tracking in UAV images. Recent studies show that adding an adversarial patch on objects can fool the well-trained deep neural networks based object detectors, posing security concerns to the downstream tasks. However, the current public UAV datasets might ignore the diverse altitudes, vehicle attributes, fine-grained instance-level annotation in mostly side view with blurred vehicle roof, so none of them is good to study the adversarial patch based vehicle detection attack problem. In this paper, we propose a new dataset named EVD4UAV as an altitude-sensitive benchmark to evade vehicle detection in UAV with 6,284 images and 90,886 fine-grained annotated vehicles. The EVD4UAV dataset has diverse altitudes (50m, 70m, 90m), vehicle attributes (color, type), fine-grained annotation (horizontal and rotated bounding boxes, instance-level mask) in top view with clear vehicle roof. One white-box and two black-box patch based attack methods are implemented to attack three classic deep neural networks based object detectors on EVD4UAV. The experimental results show that these representative attack methods could not achieve the robust altitude-insensitive attack performance.
Defense against Adversarial Cloud Attack on Remote Sensing Salient Object Detection
Jul 05, 2023Detecting the salient objects in a remote sensing image has wide applications for the interdisciplinary research. Many existing deep learning methods have been proposed for Salient Object Detection (SOD) in remote sensing images and get remarkable results. However, the recent adversarial attack examples, generated by changing a few pixel values on the original remote sensing image, could result in a collapse for the well-trained deep learning based SOD model. Different with existing methods adding perturbation to original images, we propose to jointly tune adversarial exposure and additive perturbation for attack and constrain image close to cloudy image as Adversarial Cloud. Cloud is natural and common in remote sensing images, however, camouflaging cloud based adversarial attack and defense for remote sensing images are not well studied before. Furthermore, we design DefenseNet as a learn-able pre-processing to the adversarial cloudy images so as to preserve the performance of the deep learning based remote sensing SOD model, without tuning the already deployed deep SOD model. By considering both regular and generalized adversarial examples, the proposed DefenseNet can defend the proposed Adversarial Cloud in white-box setting and other attack methods in black-box setting. Experimental results on a synthesized benchmark from the public remote sensing SOD dataset (EORSSD) show the promising defense against adversarial cloud attacks.
Real-Time Super-Resolution for Real-World Images on Mobile Devices
Jun 03, 2022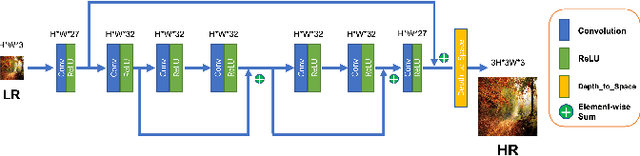
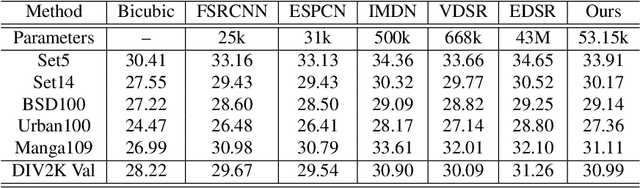
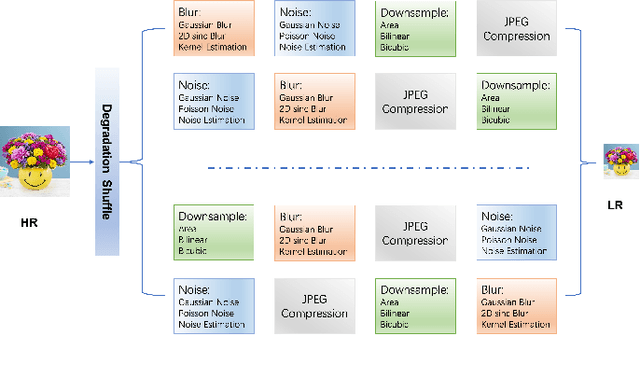
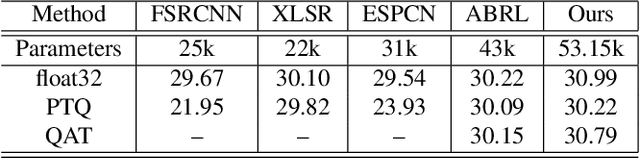
Image Super-Resolution (ISR), which aims at recovering High-Resolution (HR) images from the corresponding Low-Resolution (LR) counterparts. Although recent progress in ISR has been remarkable. However, they are way too computationally intensive to be deployed on edge devices, since most of the recent approaches are deep learning-based. Besides, these methods always fail in real-world scenes, since most of them adopt a simple fixed "ideal" bicubic downsampling kernel from high-quality images to construct LR/HR training pairs which may lose track of frequency-related details. In this work, an approach for real-time ISR on mobile devices is presented, which is able to deal with a wide range of degradations in real-world scenarios. Extensive experiments on traditional super-resolution datasets (Set5, Set14, BSD100, Urban100, Manga109, DIV2K) and real-world images with a variety of degradations demonstrate that our method outperforms the state-of-art methods, resulting in higher PSNR and SSIM, lower noise and better visual quality. Most importantly, our method achieves real-time performance on mobile or edge devices.
Pik-Fix: Restoring and Colorizing Old Photos
May 11, 2022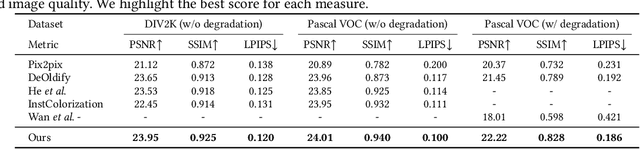
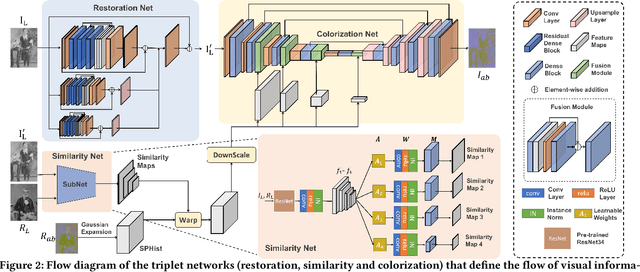
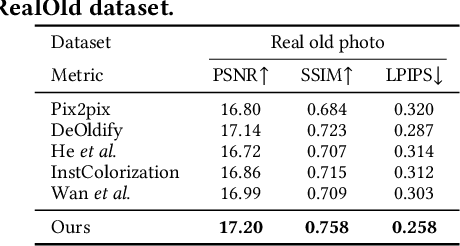

Restoring and inpainting the visual memories that are present, but often impaired, in old photos remains an intriguing but unsolved research topic. Decades-old photos often suffer from severe and commingled degradation such as cracks, defocus, and color-fading, which are difficult to treat individually and harder to repair when they interact. Deep learning presents a plausible avenue, but the lack of large-scale datasets of old photos makes addressing this restoration task very challenging. Here we present a novel reference-based end-to-end learning framework that is able to both repair and colorize old and degraded pictures. Our proposed framework consists of three modules: a restoration sub-network that conducts restoration from degradations, a similarity sub-network that performs color histogram matching and color transfer, and a colorization subnet that learns to predict the chroma elements of images that have been conditioned on chromatic reference signals. The overall system makes use of color histogram priors from reference images, which greatly reduces the need for large-scale training data. We have also created a first-of-a-kind public dataset of real old photos that are paired with ground truth "pristine" photos that have been that have been manually restored by PhotoShop experts. We conducted extensive experiments on this dataset and synthetic datasets, and found that our method significantly outperforms previous state-of-the-art models using both qualitative comparisons and quantitative measurements.