 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeedance 2.0: Advancing Video Generation for World Complexity
Apr 15, 2026Seedance 2.0 is a new native multi-modal audio-video generation model, officially released in China in early February 2026. Compared with its predecessors, Seedance 1.0 and 1.5 Pro, Seedance 2.0 adopts a unified, highly efficient, and large-scale architecture for multi-modal audio-video joint generation. This allows it to support four input modalities: text, image, audio, and video, by integrating one of the most comprehensive suites of multi-modal content reference and editing capabilities available in the industry to date. It delivers substantial, well-rounded improvements across all key sub-dimensions of video and audio generation. In both expert evaluations and public user tests, the model has demonstrated performance on par with the leading levels in the field. Seedance 2.0 supports direct generation of audio-video content with durations ranging from 4 to 15 seconds, with native output resolutions of 480p and 720p. For multi-modal inputs as reference, its current open platform supports up to 3 video clips, 9 images, and 3 audio clips. In addition, we provide Seedance 2.0 Fast version, an accelerated variant of Seedance 2.0 designed to boost generation speed for low-latency scenarios. Seedance 2.0 has delivered significant improvements to its foundational generation capabilities and multi-modal generation performance, bringing an enhanced creative experience for end users.
LAER-MoE: Load-Adaptive Expert Re-layout for Efficient Mixture-of-Experts Training
Feb 12, 2026Expert parallelism is vital for effectively training Mixture-of-Experts (MoE) models, enabling different devices to host distinct experts, with each device processing different input data. However, during expert parallel training, dynamic routing results in significant load imbalance among experts: a handful of overloaded experts hinder overall iteration, emerging as a training bottleneck. In this paper, we introduce LAER-MoE, an efficient MoE training framework. The core of LAER-MoE is a novel parallel paradigm, Fully Sharded Expert Parallel (FSEP), which fully partitions each expert parameter by the number of devices and restores partial experts at expert granularity through All-to-All communication during training. This allows for flexible re-layout of expert parameters during training to enhance load balancing. In particular, we perform fine-grained scheduling of communication operations to minimize communication overhead. Additionally, we develop a load balancing planner to formulate re-layout strategies of experts and routing schemes for tokens during training. We perform experiments on an A100 cluster, and the results indicate that our system achieves up to 1.69x acceleration compared to the current state-of-the-art training systems. Source code available at https://github.com/PKU-DAIR/Hetu-Galvatron/tree/laer-moe.
Flow caching for autoregressive video generation
Feb 11, 2026Autoregressive models, often built on Transformer architectures, represent a powerful paradigm for generating ultra-long videos by synthesizing content in sequential chunks. However, this sequential generation process is notoriously slow. While caching strategies have proven effective for accelerating traditional video diffusion models, existing methods assume uniform denoising across all frames-an assumption that breaks down in autoregressive models where different video chunks exhibit varying similarity patterns at identical timesteps. In this paper, we present FlowCache, the first caching framework specifically designed for autoregressive video generation. Our key insight is that each video chunk should maintain independent caching policies, allowing fine-grained control over which chunks require recomputation at each timestep. We introduce a chunkwise caching strategy that dynamically adapts to the unique denoising characteristics of each chunk, complemented by a joint importance-redundancy optimized KV cache compression mechanism that maintains fixed memory bounds while preserving generation quality. Our method achieves remarkable speedups of 2.38 times on MAGI-1 and 6.7 times on SkyReels-V2, with negligible quality degradation (VBench: 0.87 increase and 0.79 decrease respectively). These results demonstrate that FlowCache successfully unlocks the potential of autoregressive models for real-time, ultra-long video generation-establishing a new benchmark for efficient video synthesis at scale. The code is available at https://github.com/mikeallen39/FlowCache.
Does Your Reasoning Model Implicitly Know When to Stop Thinking?
Feb 09, 2026Recent advancements in large reasoning models (LRMs) have greatly improved their capabilities on complex reasoning tasks through Long Chains of Thought (CoTs). However, this approach often results in substantial redundancy, impairing computational efficiency and causing significant delays in real-time applications. Recent studies show that longer reasoning chains are frequently uncorrelated with correctness and can even be detrimental to accuracy. In a further in-depth analysis of this phenomenon, we surprisingly uncover and empirically verify that LRMs implicitly know the appropriate time to stop thinking, while this capability is obscured by current sampling paradigms. Motivated by this, we introduce SAGE (Self-Aware Guided Efficient Reasoning), a novel sampling paradigm that unleashes this efficient reasoning potential. Furthermore, integrating SAGE as mixed sampling into group-based reinforcement learning (SAGE-RL) enables SAGE-RL to effectively incorporate SAGE-discovered efficient reasoning patterns into standard pass@1 inference, markedly enhancing both the reasoning accuracy and efficiency of LRMs across multiple challenging mathematical benchmarks.
Real-Time Aligned Reward Model beyond Semantics
Jan 30, 2026Reinforcement Learning from Human Feedback (RLHF) is a pivotal technique for aligning large language models (LLMs) with human preferences, yet it is susceptible to reward overoptimization, in which policy models overfit to the reward model, exploit spurious reward patterns instead of faithfully capturing human intent. Prior mitigations primarily relies on surface semantic information and fails to efficiently address the misalignment between the reward model (RM) and the policy model caused by continuous policy distribution shifts. This inevitably leads to an increasing reward discrepancy, exacerbating reward overoptimization. To address these limitations, we introduce R2M (Real-Time Aligned Reward Model), a novel lightweight RLHF framework. R2M goes beyond vanilla reward models that solely depend on the semantic representations of a pretrained LLM. Instead, it leverages the evolving hidden states of the policy (namely policy feedback) to align with the real-time distribution shift of the policy during the RL process. This work points to a promising new direction for improving the performance of reward models through real-time utilization of feedback from policy models.
Polybasic Speculative Decoding Through a Theoretical Perspective
Oct 30, 2025



Inference latency stands as a critical bottleneck in the large-scale deployment of Large Language Models (LLMs). Speculative decoding methods have recently shown promise in accelerating inference without compromising the output distribution. However, existing work typically relies on a dualistic draft-verify framework and lacks rigorous theoretical grounding. In this paper, we introduce a novel \emph{polybasic} speculative decoding framework, underpinned by a comprehensive theoretical analysis. Specifically, we prove a fundamental theorem that characterizes the optimal inference time for multi-model speculative decoding systems, shedding light on how to extend beyond the dualistic approach to a more general polybasic paradigm. Through our theoretical investigation of multi-model token generation, we expose and optimize the interplay between model capabilities, acceptance lengths, and overall computational cost. Our framework supports both standalone implementation and integration with existing speculative techniques, leading to accelerated performance in practice. Experimental results across multiple model families demonstrate that our approach yields speedup ratios ranging from $3.31\times$ to $4.01\times$ for LLaMA2-Chat 7B, up to $3.87 \times$ for LLaMA3-8B, up to $4.43 \times$ for Vicuna-7B and up to $3.85 \times$ for Qwen2-7B -- all while preserving the original output distribution. We release our theoretical proofs and implementation code to facilitate further investigation into polybasic speculative decoding.
Adversarial Distribution Matching for Diffusion Distillation Towards Efficient Image and Video Synthesis
Jul 24, 2025



Distribution Matching Distillation (DMD) is a promising score distillation technique that compresses pre-trained teacher diffusion models into efficient one-step or multi-step student generators. Nevertheless, its reliance on the reverse Kullback-Leibler (KL) divergence minimization potentially induces mode collapse (or mode-seeking) in certain applications. To circumvent this inherent drawback, we propose Adversarial Distribution Matching (ADM), a novel framework that leverages diffusion-based discriminators to align the latent predictions between real and fake score estimators for score distillation in an adversarial manner. In the context of extremely challenging one-step distillation, we further improve the pre-trained generator by adversarial distillation with hybrid discriminators in both latent and pixel spaces. Different from the mean squared error used in DMD2 pre-training, our method incorporates the distributional loss on ODE pairs collected from the teacher model, and thus providing a better initialization for score distillation fine-tuning in the next stage. By combining the adversarial distillation pre-training with ADM fine-tuning into a unified pipeline termed DMDX, our proposed method achieves superior one-step performance on SDXL compared to DMD2 while consuming less GPU time. Additional experiments that apply multi-step ADM distillation on SD3-Medium, SD3.5-Large, and CogVideoX set a new benchmark towards efficient image and video synthesis.
Autoregressive Adversarial Post-Training for Real-Time Interactive Video Generation
Jun 11, 2025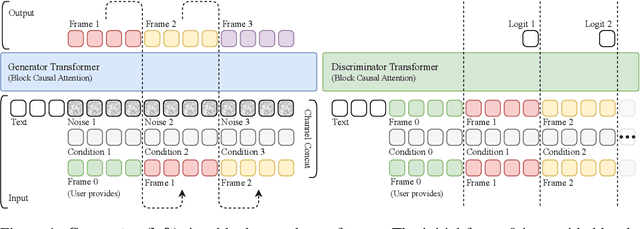
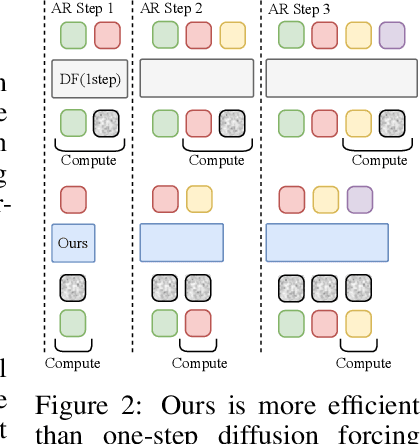
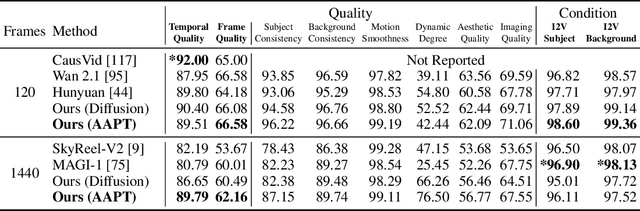

Existing large-scale video generation models are computationally intensive, preventing adoption in real-time and interactive applications. In this work, we propose autoregressive adversarial post-training (AAPT) to transform a pre-trained latent video diffusion model into a real-time, interactive video generator. Our model autoregressively generates a latent frame at a time using a single neural function evaluation (1NFE). The model can stream the result to the user in real time and receive interactive responses as controls to generate the next latent frame. Unlike existing approaches, our method explores adversarial training as an effective paradigm for autoregressive generation. This not only allows us to design an architecture that is more efficient for one-step generation while fully utilizing the KV cache, but also enables training the model in a student-forcing manner that proves to be effective in reducing error accumulation during long video generation. Our experiments demonstrate that our 8B model achieves real-time, 24fps, streaming video generation at 736x416 resolution on a single H100, or 1280x720 on 8xH100 up to a minute long (1440 frames). Visit our research website at https://seaweed-apt.com/2
Seedance 1.0: Exploring the Boundaries of Video Generation Models
Jun 10, 2025



Notable breakthroughs in diffusion modeling have propelled rapid improvements in video generation, yet current foundational model still face critical challenges in simultaneously balancing prompt following, motion plausibility, and visual quality. In this report, we introduce Seedance 1.0, a high-performance and inference-efficient video foundation generation model that integrates several core technical improvements: (i) multi-source data curation augmented with precision and meaningful video captioning, enabling comprehensive learning across diverse scenarios; (ii) an efficient architecture design with proposed training paradigm, which allows for natively supporting multi-shot generation and jointly learning of both text-to-video and image-to-video tasks. (iii) carefully-optimized post-training approaches leveraging fine-grained supervised fine-tuning, and video-specific RLHF with multi-dimensional reward mechanisms for comprehensive performance improvements; (iv) excellent model acceleration achieving ~10x inference speedup through multi-stage distillation strategies and system-level optimizations. Seedance 1.0 can generate a 5-second video at 1080p resolution only with 41.4 seconds (NVIDIA-L20). Compared to state-of-the-art video generation models, Seedance 1.0 stands out with high-quality and fast video generation having superior spatiotemporal fluidity with structural stability, precise instruction adherence in complex multi-subject contexts, native multi-shot narrative coherence with consistent subject representation.
SeedEdit 3.0: Fast and High-Quality Generative Image Editing
Jun 06, 2025We introduce SeedEdit 3.0, in companion with our T2I model Seedream 3.0, which significantly improves over our previous SeedEdit versions in both aspects of edit instruction following and image content (e.g., ID/IP) preservation on real image inputs. Additional to model upgrading with T2I, in this report, we present several key improvements. First, we develop an enhanced data curation pipeline with a meta-info paradigm and meta-info embedding strategy that help mix images from multiple data sources. This allows us to scale editing data effectively, and meta information is helpfult to connect VLM with diffusion model more closely. Second, we introduce a joint learning pipeline for computing a diffusion loss and reward losses. Finally, we evaluate SeedEdit 3.0 on our testing benchmarks, for real/synthetic image editing, where it achieves a best trade-off between multiple aspects, yielding a high usability rate of 56.1%, compared to SeedEdit 1.6 (38.4%), GPT4o (37.1%) and Gemini 2.0 (30.3%).