 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrete Diffusion for Complex and Congested Multi-Agent Path Finding with Sparse Social Attention
May 13, 2026Multi-Agent Path Finding (MAPF) is a coordination problem that requires computing globally consistent, collision-free trajectories from individual start positions to assigned goal positions under combinatorial planning complexity. In dense environments, suboptimal initial plans induce compound conflicts that hinder feasible repair. For repair-based solvers like LNS2, initial plan quality critically affects downstream repair, yet this factor remains underexplored. We propose DiffLNS, a hybrid framework that integrates a discrete denoising diffusion probabilistic model (D3PM) with LNS2. The D3PM serves as an initializer with sparse social attention that learns a spatiotemporal prior over coordinated multi-agent action trajectories from expert demonstrations and samples multiple joint plans. Operating directly on the categorical action space, our discrete diffusion preserves the MAPF action structure and samples from a multimodal joint-plan distribution to produce diverse drafts well suited for neighborhood repair. These drafts act as warm starts for downstream repair, which completes unfinished trajectories and resolves remaining conflicts under hard MAPF constraints. Experimental results show that despite being trained only on instances with at most 96 agents, the initializer generalizes to scenarios with up to 312 agents at inference time. Across 20 complex and congested settings, DiffLNS achieves an average success rate of 95.8%, outperforming the strongest tested baseline by 9.6 percentage points and matching or exceeding all baselines in all 20 settings. To the best of our knowledge, this is the first work to leverage discrete diffusion for warm-starting an LNS-based MAPF solver.
GS-STVSR: Ultra-Efficient Continuous Spatio-Temporal Video Super-Resolution via 2D Gaussian Splatting
Apr 20, 2026Continuous Spatio-Temporal Video Super-Resolution (C-STVSR) aims to simultaneously enhance the spatial resolution and frame rate of videos by arbitrary scale factors, offering greater flexibility than fixed-scale methods that are constrained by predefined upsampling ratios. In recent years, methods based on Implicit Neural Representations (INR) have made significant progress in C-STVSR by learning continuous mappings from spatio-temporal coordinates to pixel values. However, these methods fundamentally rely on dense pixel-wise grid queries, causing computational cost to scale linearly with the number of interpolated frames and severely limiting inference efficiency. We propose GS-STVSR, an ultra-efficient C-STVSR framework based on 2D Gaussian Splatting (2D-GS) that drives the spatiotemporal evolution of Gaussian kernels through continuous motion modeling, bypassing dense grid queries entirely. We exploit the strong temporal stability of covariance parameters for lightweight intermediate fitting, design an optical flow-guided motion module to derive Gaussian position and color at arbitrary time steps, introduce a Covariance resampling alignment module to prevent covariance drift, and propose an adaptive offset window for large-scale motion. Extensive experiments on Vid4, GoPro, and Adobe240 show that GS-STVSR achieves state-of-the-art quality across all benchmarks. Moreover, its inference time remains nearly constant at conventional temporal scales (X2--X8) and delivers over X3 speedup at extreme scales X32, demonstrating strong practical applicability.
QiMeng-PRepair: Precise Code Repair via Edit-Aware Reward Optimization
Apr 07, 2026Large Language Models (LLMs) achieve strong program repair performance but often suffer from over-editing, where excessive modifications overwrite correct code and hinder bug localization. We systematically quantify its impact and introduce precise repair task, which maximizes reuse of correct code while fixing only buggy parts. Building on this insight, we propose PRepair, a framework that mitigates over-editing and improves repair accuracy. PRepair has two components: Self-Breaking, which generates diverse buggy programs via controlled bug injection and min-max sampling, and Self-Repairing, which trains models with Edit-Aware Group Relative Policy Optimization (EA-GRPO) using an edit-aware reward to encourage minimal yet correct edits. Experiments show that PRepair improves repair precision by up to 31.4% under $\mathrm{fix}_1@1$, a metric that jointly considers repair correctness and extent, and significantly increases decoding throughput when combined with speculative editing, demonstrating its potential for precise and practical code repair.
ColorFLUX: A Structure-Color Decoupling Framework for Old Photo Colorization
Mar 30, 2026Old photos preserve invaluable historical memories, making their restoration and colorization highly desirable. While existing restoration models can address some degradation issues like denoising and scratch removal, they often struggle with accurate colorization. This limitation arises from the unique degradation inherent in old photos, such as faded brightness and altered color hues, which are different from modern photo distributions, creating a substantial domain gap during colorization. In this paper, we propose a novel old photo colorization framework based on the generative diffusion model FLUX. Our approach introduces a structure-color decoupling strategy that separates structure preservation from color restoration, enabling accurate colorization of old photos while maintaining structural consistency. We further enhance the model with a progressive Direct Preference Optimization (Pro-DPO) strategy, which allows the model to learn subtle color preferences through coarse-to-fine transitions in color augmentation. Additionally, we address the limitations of text-based prompts by introducing visual semantic prompts, which extract fine-grained semantic information directly from old photos, helping to eliminate the color bias inherent in old photos. Experimental results on both synthetic and real datasets demonstrate that our approach outperforms existing state-of-the-art colorization methods, including closed-source commercial models, producing high-quality and vivid colorization.
ShotFinder: Imagination-Driven Open-Domain Video Shot Retrieval via Web Search
Jan 30, 2026In recent years, large language models (LLMs) have made rapid progress in information retrieval, yet existing research has mainly focused on text or static multimodal settings. Open-domain video shot retrieval, which involves richer temporal structure and more complex semantics, still lacks systematic benchmarks and analysis. To fill this gap, we introduce ShotFinder, a benchmark that formalizes editing requirements as keyframe-oriented shot descriptions and introduces five types of controllable single-factor constraints: Temporal order, Color, Visual style, Audio, and Resolution. We curate 1,210 high-quality samples from YouTube across 20 thematic categories, using large models for generation with human verification. Based on the benchmark, we propose ShotFinder, a text-driven three-stage retrieval and localization pipeline: (1) query expansion via video imagination, (2) candidate video retrieval with a search engine, and (3) description-guided temporal localization. Experiments on multiple closed-source and open-source models reveal a significant gap to human performance, with clear imbalance across constraints: temporal localization is relatively tractable, while color and visual style remain major challenges. These results reveal that open-domain video shot retrieval is still a critical capability that multimodal large models have yet to overcome.
Segmental Advantage Estimation: Enhancing PPO for Long-Context LLM Training
Jan 12, 2026Training Large Language Models (LLMs) for reasoning tasks is increasingly driven by Reinforcement Learning with Verifiable Rewards (RLVR), where Proximal Policy Optimization (PPO) provides a principled framework for stable policy updates. However, the practical application of PPO is hindered by unreliable advantage estimation in the sparse-reward RLVR regime. This issue arises because the sparse rewards in RLVR lead to inaccurate intermediate value predictions, which in turn introduce significant bias when aggregated at every token by Generalized Advantage Estimation (GAE). To address this, we introduce Segmental Advantage Estimation (SAE), which mitigates the bias that GAE can incur in RLVR. Our key insight is that aggregating $n$-step advantages at every token(as in GAE) is unnecessary and often introduces excessive bias, since individual tokens carry minimal information. Instead, SAE first partitions the generated sequence into coherent sub-segments using low-probability tokens as heuristic boundaries. It then selectively computes variance-reduced advantage estimates only from these information-rich segment transitions, effectively filtering out noise from intermediate tokens. Our experiments demonstrate that SAE achieves superior performance, with marked improvements in final scores, training stability, and sample efficiency. These gains are shown to be consistent across multiple model sizes, and a correlation analysis confirms that our proposed advantage estimator achieves a higher correlation with an approximate ground-truth advantage, justifying its superior performance.
Run, Ruminate, and Regulate: A Dual-process Thinking System for Vision-and-Language Navigation
Nov 18, 2025Vision-and-Language Navigation (VLN) requires an agent to dynamically explore complex 3D environments following human instructions. Recent research underscores the potential of harnessing large language models (LLMs) for VLN, given their commonsense knowledge and general reasoning capabilities. Despite their strengths, a substantial gap in task completion performance persists between LLM-based approaches and domain experts, as LLMs inherently struggle to comprehend real-world spatial correlations precisely. Additionally, introducing LLMs is accompanied with substantial computational cost and inference latency. To address these issues, we propose a novel dual-process thinking framework dubbed R3, integrating LLMs' generalization capabilities with VLN-specific expertise in a zero-shot manner. The framework comprises three core modules: Runner, Ruminator, and Regulator. The Runner is a lightweight transformer-based expert model that ensures efficient and accurate navigation under regular circumstances. The Ruminator employs a powerful multimodal LLM as the backbone and adopts chain-of-thought (CoT) prompting to elicit structured reasoning. The Regulator monitors the navigation progress and controls the appropriate thinking mode according to three criteria, integrating Runner and Ruminator harmoniously. Experimental results illustrate that R3 significantly outperforms other state-of-the-art methods, exceeding 3.28% and 3.30% in SPL and RGSPL respectively on the REVERIE benchmark. This pronounced enhancement highlights the effectiveness of our method in handling challenging VLN tasks.
QiMeng-SALV: Signal-Aware Learning for Verilog Code Generation
Oct 22, 2025The remarkable progress of Large Language Models (LLMs) presents promising opportunities for Verilog code generation which is significantly important for automated circuit design. The lacking of meaningful functional rewards hinders the preference optimization based on Reinforcement Learning (RL) for producing functionally correct Verilog code. In this paper, we propose Signal-Aware Learning for Verilog code generation (QiMeng-SALV) by leveraging code segments of functionally correct output signal to optimize RL training. Considering Verilog code specifies the structural interconnection of hardware gates and wires so that different output signals are independent, the key insight of QiMeng-SALV is to extract verified signal-aware implementations in partially incorrect modules, so as to enhance the extraction of meaningful functional rewards. Roughly, we verify the functional correctness of signals in generated module by comparing with that of reference module in the training data. Then abstract syntax tree (AST) is employed to identify signal-aware code segments which can provide meaningful functional rewards from erroneous modules. Finally, we introduce signal-aware DPO which is optimized on the correct signal-level code segments, thereby preventing noise and interference from incorrect signals. The proposed QiMeng-SALV underscores the paradigm shift from conventional module-level to fine-grained signal-level optimization in Verilog code generation, addressing the issue of insufficient functional rewards. Experiments demonstrate that our method achieves state-of-the-art performance on VerilogEval and RTLLM, with a 7B parameter model matching the performance of the DeepSeek v3 671B model and significantly outperforming the leading open-source model CodeV trained on the same dataset. Our code is available at https://github.com/zy1xxx/SALV.
Mutual-Supervised Learning for Sequential-to-Parallel Code Translation
Jun 11, 2025



The rise of GPU-based high-performance computing (HPC) has driven the widespread adoption of parallel programming models such as CUDA. Yet, the inherent complexity of parallel programming creates a demand for the automated sequential-to-parallel approaches. However, data scarcity poses a significant challenge for machine learning-based sequential-to-parallel code translation. Although recent back-translation methods show promise, they still fail to ensure functional equivalence in the translated code. In this paper, we propose a novel Mutual-Supervised Learning (MSL) framework for sequential-to-parallel code translation to address the functional equivalence issue. MSL consists of two models, a Translator and a Tester. Through an iterative loop consisting of Co-verify and Co-evolve steps, the Translator and the Tester mutually generate data for each other and improve collectively. The Tester generates unit tests to verify and filter functionally equivalent translated code, thereby evolving the Translator, while the Translator generates translated code as augmented input to evolve the Tester. Experimental results demonstrate that MuSL significantly enhances the performance of the base model: when applied to Qwen2.5-Coder, it not only improves Pass@1 by up to 28.91% and boosts Tester performance by 68.90%, but also outperforms the previous state-of-the-art method CodeRosetta by 1.56 and 6.92 in BLEU and CodeBLEU scores, while achieving performance comparable to DeepSeek-R1 and GPT-4.1. Our code is available at https://github.com/kcxain/musl.
QiMeng: Fully Automated Hardware and Software Design for Processor Chip
Jun 05, 2025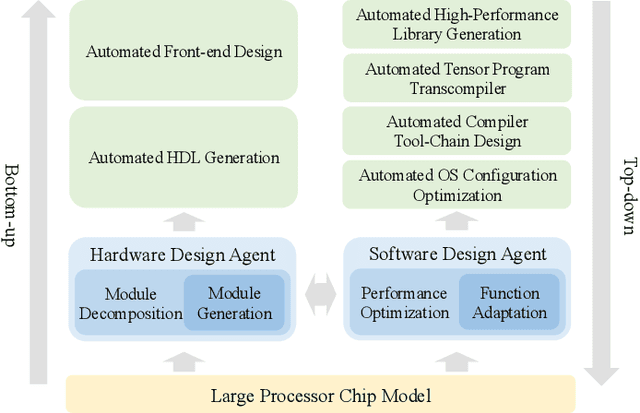
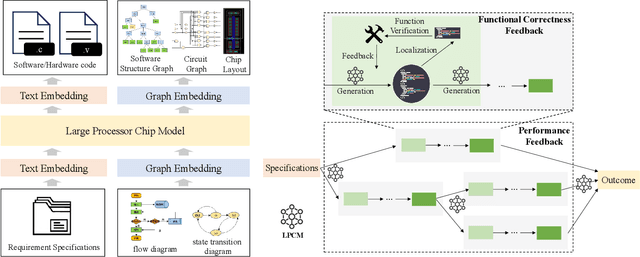
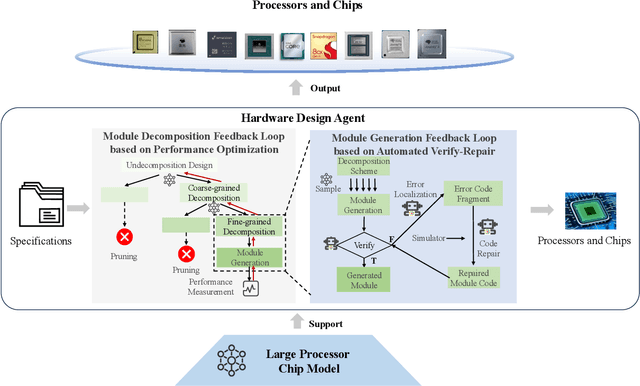
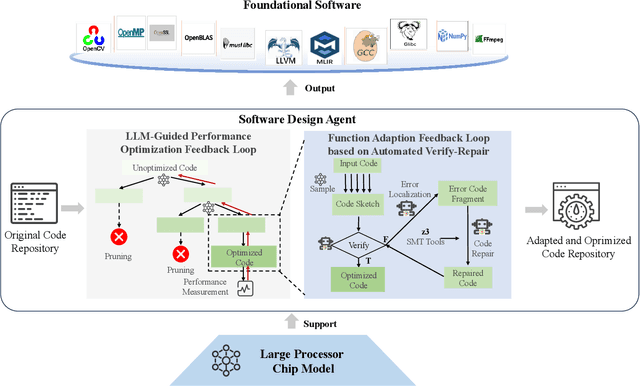
Processor chip design technology serves as a key frontier driving breakthroughs in computer science and related fields. With the rapid advancement of information technology, conventional design paradigms face three major challenges: the physical constraints of fabrication technologies, the escalating demands for design resources, and the increasing diversity of ecosystems. Automated processor chip design has emerged as a transformative solution to address these challenges. While recent breakthroughs in Artificial Intelligence (AI), particularly Large Language Models (LLMs) techniques, have opened new possibilities for fully automated processor chip design, substantial challenges remain in establishing domain-specific LLMs for processor chip design. In this paper, we propose QiMeng, a novel system for fully automated hardware and software design of processor chips. QiMeng comprises three hierarchical layers. In the bottom-layer, we construct a domain-specific Large Processor Chip Model (LPCM) that introduces novel designs in architecture, training, and inference, to address key challenges such as knowledge representation gap, data scarcity, correctness assurance, and enormous solution space. In the middle-layer, leveraging the LPCM's knowledge representation and inference capabilities, we develop the Hardware Design Agent and the Software Design Agent to automate the design of hardware and software for processor chips. Currently, several components of QiMeng have been completed and successfully applied in various top-layer applications, demonstrating significant advantages and providing a feasible solution for efficient, fully automated hardware/software design of processor chips. Future research will focus on integrating all components and performing iterative top-down and bottom-up design processes to establish a comprehensive QiMeng system.