 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Restoration and Generation Manifolds in One-Step Diffusion for Real-World Super-Resolution
Apr 27, 2026Pretrained diffusion models have revolutionized real-world image super-resolution (Real-ISR) but suffer from computational bottlenecks due to iterative sampling. Recent single-step distillation accelerates inference but faces a stark perception-distortion trade-off due to rigid timestep initialization, distributional trajectory mismatches, and fragile stochastic modulation. To address this, we present Adaptive Inversion and Degradation-aware Sampling for Real-ISR (IDaS-SR), a one-step framework bridging the deterministic restoration and stochastic generation manifolds. At its core, the Manifold Inversion Noise Estimator (MINE) resolves these initialization and trajectory mismatches by predicting a severity-aware timestep and inversion noise, precisely anchoring low-quality latents onto the diffusion trajectory. Furthermore, to mitigate fragile stochastic modulation, we propose CHARIOT, a continuous generative steering mechanism. By rescheduling trajectories and interpolating noise, it enables explicit navigation of the perception-distortion boundary without compromising structural priors. Extensive experiments demonstrate that IDaS-SR outperforms state-of-the-art methods, seamlessly transitioning from a rigorous structural restorer to a sophisticated texture hallucinator in a single inference step.
Zero-shot Adaptation of Stable Diffusion via Plug-in Hierarchical Degradation Representation for Real-World Super-Resolution
Dec 11, 2025Real-World Image Super-Resolution (Real-ISR) aims to recover high-quality images from low-quality inputs degraded by unknown and complex real-world factors. Real-world scenarios involve diverse and coupled degradations, making it necessary to provide diffusion models with richer and more informative guidance. However, existing methods often assume known degradation severity and rely on CLIP text encoders that cannot capture numerical severity, limiting their generalization ability. To address this, we propose \textbf{HD-CLIP} (\textbf{H}ierarchical \textbf{D}egradation CLIP), which decomposes a low-quality image into a semantic embedding and an ordinal degradation embedding that captures ordered relationships and allows interpolation across unseen levels. Furthermore, we integrated it into diffusion models via classifier-free guidance (CFG) and proposed classifier-free projection guidance (CFPG). HD-CLIP leverages semantic cues to guide generative restoration while using degradation cues to suppress undesired hallucinations and artifacts. As a \textbf{plug-and-play module}, HD-CLIP can be seamlessly integrated into various super-resolution frameworks without training, significantly improving detail fidelity and perceptual realism across diverse real-world datasets.
AdaIR: Exploiting Underlying Similarities of Image Restoration Tasks with Adapters
Apr 17, 2024Existing image restoration approaches typically employ extensive networks specifically trained for designated degradations. Despite being effective, such methods inevitably entail considerable storage costs and computational overheads due to the reliance on task-specific networks. In this work, we go beyond this well-established framework and exploit the inherent commonalities among image restoration tasks. The primary objective is to identify components that are shareable across restoration tasks and augment the shared components with modules specifically trained for individual tasks. Towards this goal, we propose AdaIR, a novel framework that enables low storage cost and efficient training without sacrificing performance. Specifically, a generic restoration network is first constructed through self-supervised pre-training using synthetic degradations. Subsequent to the pre-training phase, adapters are trained to adapt the pre-trained network to specific degradations. AdaIR requires solely the training of lightweight, task-specific modules, ensuring a more efficient storage and training regimen. We have conducted extensive experiments to validate the effectiveness of AdaIR and analyze the influence of the pre-training strategy on discovering shareable components. Extensive experimental results show that AdaIR achieves outstanding results on multi-task restoration while utilizing significantly fewer parameters (1.9 MB) and less training time (7 hours) for each restoration task. The source codes and trained models will be released.
Cascaded Local Implicit Transformer for Arbitrary-Scale Super-Resolution
Mar 29, 2023Implicit neural representation has recently shown a promising ability in representing images with arbitrary resolutions. In this paper, we present a Local Implicit Transformer (LIT), which integrates the attention mechanism and frequency encoding technique into a local implicit image function. We design a cross-scale local attention block to effectively aggregate local features. To further improve representative power, we propose a Cascaded LIT (CLIT) that exploits multi-scale features, along with a cumulative training strategy that gradually increases the upsampling scales during training. We have conducted extensive experiments to validate the effectiveness of these components and analyze various training strategies. The qualitative and quantitative results demonstrate that LIT and CLIT achieve favorable results and outperform the prior works in arbitrary super-resolution tasks.
MicroISP: Processing 32MP Photos on Mobile Devices with Deep Learning
Nov 08, 2022



While neural networks-based photo processing solutions can provide a better image quality compared to the traditional ISP systems, their application to mobile devices is still very limited due to their very high computational complexity. In this paper, we present a novel MicroISP model designed specifically for edge devices, taking into account their computational and memory limitations. The proposed solution is capable of processing up to 32MP photos on recent smartphones using the standard mobile ML libraries and requiring less than 1 second to perform the inference, while for FullHD images it achieves real-time performance. The architecture of the model is flexible, allowing to adjust its complexity to devices of different computational power. To evaluate the performance of the model, we collected a novel Fujifilm UltraISP dataset consisting of thousands of paired photos captured with a normal mobile camera sensor and a professional 102MP medium-format FujiFilm GFX100 camera. The experiments demonstrated that, despite its compact size, the MicroISP model is able to provide comparable or better visual results than the traditional mobile ISP systems, while outperforming the previously proposed efficient deep learning based solutions. Finally, this model is also compatible with the latest mobile AI accelerators, achieving good runtime and low power consumption on smartphone NPUs and APUs. The code, dataset and pre-trained models are available on the project website: https://people.ee.ethz.ch/~ihnatova/microisp.html
PyNet-V2 Mobile: Efficient On-Device Photo Processing With Neural Networks
Nov 08, 2022The increased importance of mobile photography created a need for fast and performant RAW image processing pipelines capable of producing good visual results in spite of the mobile camera sensor limitations. While deep learning-based approaches can efficiently solve this problem, their computational requirements usually remain too large for high-resolution on-device image processing. To address this limitation, we propose a novel PyNET-V2 Mobile CNN architecture designed specifically for edge devices, being able to process RAW 12MP photos directly on mobile phones under 1.5 second and producing high perceptual photo quality. To train and to evaluate the performance of the proposed solution, we use the real-world Fujifilm UltraISP dataset consisting on thousands of RAW-RGB image pairs captured with a professional medium-format 102MP Fujifilm camera and a popular Sony mobile camera sensor. The results demonstrate that the PyNET-V2 Mobile model can substantially surpass the quality of tradition ISP pipelines, while outperforming the previously introduced neural network-based solutions designed for fast image processing. Furthermore, we show that the proposed architecture is also compatible with the latest mobile AI accelerators such as NPUs or APUs that can be used to further reduce the latency of the model to as little as 0.5 second. The dataset, code and pre-trained models used in this paper are available on the project website: https://github.com/gmalivenko/PyNET-v2
Power Efficient Video Super-Resolution on Mobile NPUs with Deep Learning, Mobile AI & AIM 2022 challenge: Report
Nov 07, 2022



Video super-resolution is one of the most popular tasks on mobile devices, being widely used for an automatic improvement of low-bitrate and low-resolution video streams. While numerous solutions have been proposed for this problem, they are usually quite computationally demanding, demonstrating low FPS rates and power efficiency on mobile devices. In this Mobile AI challenge, we address this problem and propose the participants to design an end-to-end real-time video super-resolution solution for mobile NPUs optimized for low energy consumption. The participants were provided with the REDS training dataset containing video sequences for a 4X video upscaling task. The runtime and power efficiency of all models was evaluated on the powerful MediaTek Dimensity 9000 platform with a dedicated AI processing unit capable of accelerating floating-point and quantized neural networks. All proposed solutions are fully compatible with the above NPU, demonstrating an up to 500 FPS rate and 0.2 [Watt / 30 FPS] power consumption. A detailed description of all models developed in the challenge is provided in this paper.
Learned Smartphone ISP on Mobile NPUs with Deep Learning, Mobile AI 2021 Challenge: Report
May 17, 2021
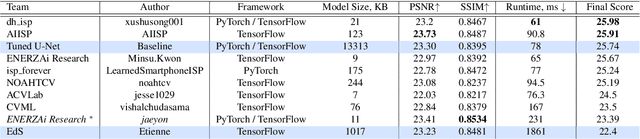
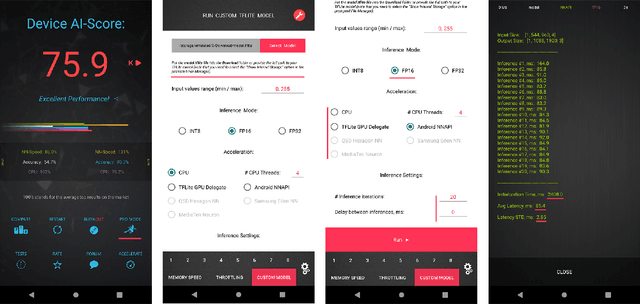
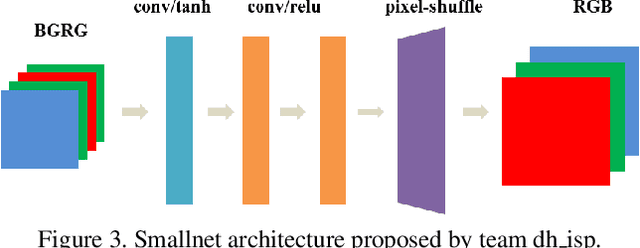
As the quality of mobile cameras starts to play a crucial role in modern smartphones, more and more attention is now being paid to ISP algorithms used to improve various perceptual aspects of mobile photos. In this Mobile AI challenge, the target was to develop an end-to-end deep learning-based image signal processing (ISP) pipeline that can replace classical hand-crafted ISPs and achieve nearly real-time performance on smartphone NPUs. For this, the participants were provided with a novel learned ISP dataset consisting of RAW-RGB image pairs captured with the Sony IMX586 Quad Bayer mobile sensor and a professional 102-megapixel medium format camera. The runtime of all models was evaluated on the MediaTek Dimensity 1000+ platform with a dedicated AI processing unit capable of accelerating both floating-point and quantized neural networks. The proposed solutions are fully compatible with the above NPU and are capable of processing Full HD photos under 60-100 milliseconds while achieving high fidelity results. A detailed description of all models developed in this challenge is provided in this paper.
Network Space Search for Pareto-Efficient Spaces
Apr 22, 2021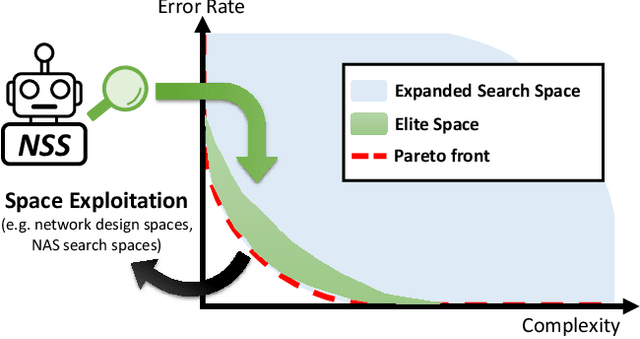
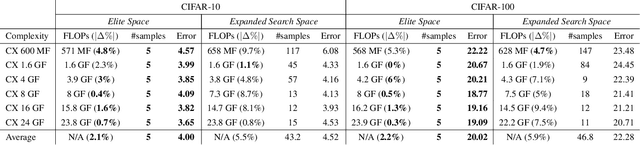
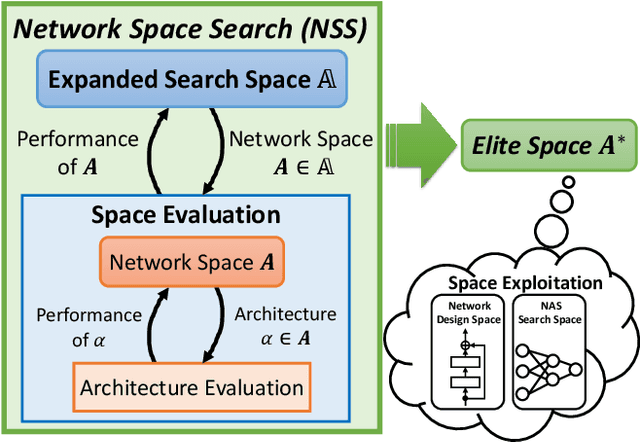
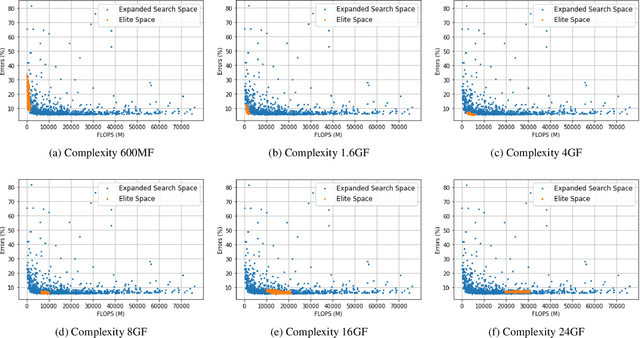
Network spaces have been known as a critical factor in both handcrafted network designs or defining search spaces for Neural Architecture Search (NAS). However, an effective space involves tremendous prior knowledge and/or manual effort, and additional constraints are required to discover efficiency-aware architectures. In this paper, we define a new problem, Network Space Search (NSS), as searching for favorable network spaces instead of a single architecture. We propose an NSS method to directly search for efficient-aware network spaces automatically, reducing the manual effort and immense cost in discovering satisfactory ones. The resultant network spaces, named Elite Spaces, are discovered from Expanded Search Space with minimal human expertise imposed. The Pareto-efficient Elite Spaces are aligned with the Pareto front under various complexity constraints and can be further served as NAS search spaces, benefiting differentiable NAS approaches (e.g. In CIFAR-100, an averagely 2.3% lower error rate and 3.7% closer to target constraint than the baseline with around 90% fewer samples required to find satisfactory networks). Moreover, our NSS approach is capable of searching for superior spaces in future unexplored spaces, revealing great potential in searching for network spaces automatically.
Deploying Image Deblurring across Mobile Devices: A Perspective of Quality and Latency
Apr 27, 2020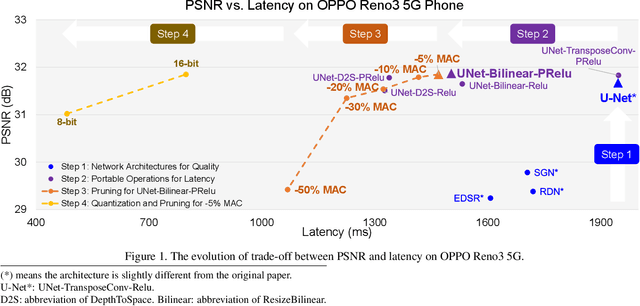
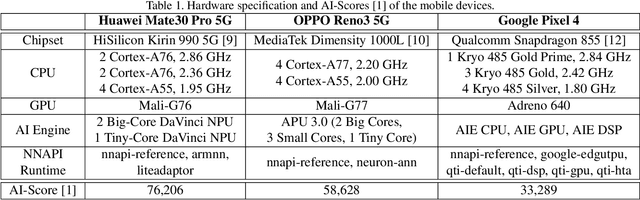
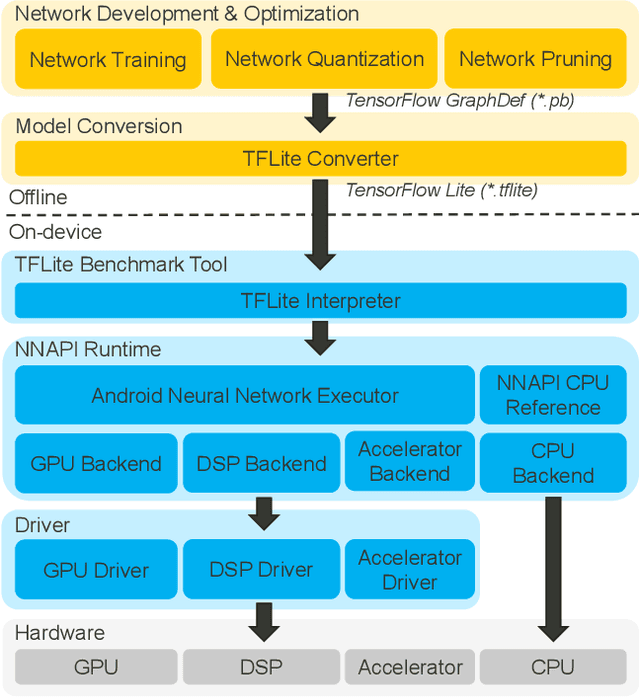
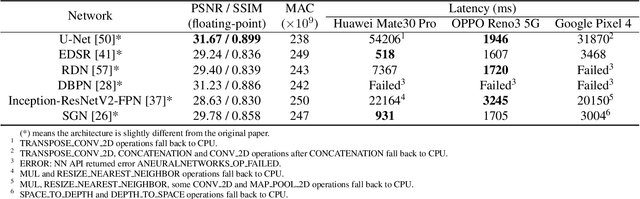
Recently, image enhancement and restoration have become important applications on mobile devices, such as super-resolution and image deblurring. However, most state-of-the-art networks present extremely high computational complexity. This makes them difficult to be deployed on mobile devices with acceptable latency. Moreover, when deploying to different mobile devices, there is a large latency variation due to the difference and limitation of deep learning accelerators on mobile devices. In this paper, we conduct a search of portable network architectures for better quality-latency trade-off across mobile devices. We further present the effectiveness of widely used network optimizations for image deblurring task. This paper provides comprehensive experiments and comparisons to uncover the in-depth analysis for both latency and image quality. Through all the above works, we demonstrate the successful deployment of image deblurring application on mobile devices with the acceleration of deep learning accelerators. To the best of our knowledge, this is the first paper that addresses all the deployment issues of image deblurring task across mobile devices. This paper provides practical deployment-guidelines, and is adopted by the championship-winning team in NTIRE 2020 Image Deblurring Challenge on Smartphone Track.