 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComSim: Building Scalable Real-World Robot Data Generation via Compositional Simulation
Apr 13, 2026Recent advancements in foundational models, such as large language models and world models, have greatly enhanced the capabilities of robotics, enabling robots to autonomously perform complex tasks. However, acquiring large-scale, high-quality training data for robotics remains a challenge, as it often requires substantial manual effort and is limited in its coverage of diverse real-world environments. To address this, we propose a novel hybrid approach called Compositional Simulation, which combines classical simulation and neural simulation to generate accurate action-video pairs while maintaining real-world consistency. Our approach utilizes a closed-loop real-sim-real data augmentation pipeline, leveraging a small amount of real-world data to generate diverse, large-scale training datasets that cover a broader spectrum of real-world scenarios. We train a neural simulator to transform classical simulation videos into real-world representations, improving the accuracy of policy models trained in real-world environments. Through extensive experiments, we demonstrate that our method significantly reduces the sim2real domain gap, resulting in higher success rates in real-world policy model training. Our approach offers a scalable solution for generating robust training data and bridging the gap between simulated and real-world robotics.
Referring-Aware Visuomotor Policy Learning for Closed-Loop Manipulation
Apr 07, 2026This paper addresses a fundamental problem of visuomotor policy learning for robotic manipulation: how to enhance robustness in out-of-distribution execution errors or dynamically re-routing trajectories, where the model relies solely on the original expert demonstrations for training. We introduce the Referring-Aware Visuomotor Policy (ReV), a closed-loop framework that can adapt to unforeseen circumstances by instantly incorporating sparse referring points provided by a human or a high-level reasoning planner. Specifically, ReV leverages the coupled diffusion heads to preserve standard task execution patterns while seamlessly integrating sparse referring via a trajectory-steering strategy. Upon receiving a specific referring point, the global diffusion head firstly generates a sequence of globally consistent yet temporally sparse action anchors, while identifies the precise temporal position for the referring point within this sequence. Subsequently, the local diffusion head adaptively interpolates adjacent anchors based on the current temporal position for specific tasks. This closed-loop process repeats at every execution step, enabling real-time trajectory replanning in response to dynamic changes in the scene. In practice, rather than relying on elaborate annotations, ReV is trained only by applying targeted perturbations to expert demonstrations. Without any additional data or fine-tuning scheme, ReV achieve higher success rates across challenging simulated and real-world tasks.
Ego to World: Collaborative Spatial Reasoning in Embodied Systems via Reinforcement Learning
Mar 16, 2026Understanding the world from distributed, partial viewpoints is a fundamental challenge for embodied multi-agent systems. Each agent perceives the environment through an ego-centric view that is often limited by occlusion and ambiguity. To study this problem, we introduce the Ego-to-World (E2W) benchmark, which evaluates a vision-language model's ability to fuse heterogeneous viewpoints across three tasks: (i) global counting, (ii) relational location reasoning, and (iii) action-oriented grasping that requires predicting view-specific image coordinates. To address this setting, we propose CoRL, a two-stage framework that combines Chain-of-Thought supervised fine-tuning with reinforcement learning using Group-Relative Policy Optimization. Its core component, the Cross-View Spatial Reward (CVSR), provides dense task-aligned feedback by linking reasoning steps to visual evidence, ensuring coherent cross-view entity resolution, and guiding the model toward correct final predictions. Experiments on E2W show that CoRL consistently surpasses strong proprietary and open-source baselines on both reasoning and perception-grounding metrics, while ablations further confirm the necessity of each CVSR component. Beyond that, CoRL generalizes to external spatial reasoning benchmarks and enables effective real-world multi-robot manipulation with calibrated multi-camera rigs, demonstrating cross-view localization and successful grasp-and-place execution. Together, E2W and CoRL provide a principled foundation for learning world-centric scene understanding from distributed, ego-centric observations, advancing collaborative embodied AI.
TouchGuide: Inference-Time Steering of Visuomotor Policies via Touch Guidance
Jan 28, 2026Fine-grained and contact-rich manipulation remain challenging for robots, largely due to the underutilization of tactile feedback. To address this, we introduce TouchGuide, a novel cross-policy visuo-tactile fusion paradigm that fuses modalities within a low-dimensional action space. Specifically, TouchGuide operates in two stages to guide a pre-trained diffusion or flow-matching visuomotor policy at inference time. First, the policy produces a coarse, visually-plausible action using only visual inputs during early sampling. Second, a task-specific Contact Physical Model (CPM) provides tactile guidance to steer and refine the action, ensuring it aligns with realistic physical contact conditions. Trained through contrastive learning on limited expert demonstrations, the CPM provides a tactile-informed feasibility score to steer the sampling process toward refined actions that satisfy physical contact constraints. Furthermore, to facilitate TouchGuide training with high-quality and cost-effective data, we introduce TacUMI, a data collection system. TacUMI achieves a favorable trade-off between precision and affordability; by leveraging rigid fingertips, it obtains direct tactile feedback, thereby enabling the collection of reliable tactile data. Extensive experiments on five challenging contact-rich tasks, such as shoe lacing and chip handover, show that TouchGuide consistently and significantly outperforms state-of-the-art visuo-tactile policies.
Advances and Innovations in the Multi-Agent Robotic System (MARS) Challenge
Jan 26, 2026Recent advancements in multimodal large language models and vision-languageaction models have significantly driven progress in Embodied AI. As the field transitions toward more complex task scenarios, multi-agent system frameworks are becoming essential for achieving scalable, efficient, and collaborative solutions. This shift is fueled by three primary factors: increasing agent capabilities, enhancing system efficiency through task delegation, and enabling advanced human-agent interactions. To address the challenges posed by multi-agent collaboration, we propose the Multi-Agent Robotic System (MARS) Challenge, held at the NeurIPS 2025 Workshop on SpaVLE. The competition focuses on two critical areas: planning and control, where participants explore multi-agent embodied planning using vision-language models (VLMs) to coordinate tasks and policy execution to perform robotic manipulation in dynamic environments. By evaluating solutions submitted by participants, the challenge provides valuable insights into the design and coordination of embodied multi-agent systems, contributing to the future development of advanced collaborative AI systems.
CDP: Towards Robust Autoregressive Visuomotor Policy Learning via Causal Diffusion
Jun 17, 2025Diffusion Policy (DP) enables robots to learn complex behaviors by imitating expert demonstrations through action diffusion. However, in practical applications, hardware limitations often degrade data quality, while real-time constraints restrict model inference to instantaneous state and scene observations. These limitations seriously reduce the efficacy of learning from expert demonstrations, resulting in failures in object localization, grasp planning, and long-horizon task execution. To address these challenges, we propose Causal Diffusion Policy (CDP), a novel transformer-based diffusion model that enhances action prediction by conditioning on historical action sequences, thereby enabling more coherent and context-aware visuomotor policy learning. To further mitigate the computational cost associated with autoregressive inference, a caching mechanism is also introduced to store attention key-value pairs from previous timesteps, substantially reducing redundant computations during execution. Extensive experiments in both simulated and real-world environments, spanning diverse 2D and 3D manipulation tasks, demonstrate that CDP uniquely leverages historical action sequences to achieve significantly higher accuracy than existing methods. Moreover, even when faced with degraded input observation quality, CDP maintains remarkable precision by reasoning through temporal continuity, which highlights its practical robustness for robotic control under realistic, imperfect conditions.
WeThink: Toward General-purpose Vision-Language Reasoning via Reinforcement Learning
Jun 09, 2025Building on the success of text-based reasoning models like DeepSeek-R1, extending these capabilities to multimodal reasoning holds great promise. While recent works have attempted to adapt DeepSeek-R1-style reinforcement learning (RL) training paradigms to multimodal large language models (MLLM), focusing on domain-specific tasks like math and visual perception, a critical question remains: How can we achieve the general-purpose visual-language reasoning through RL? To address this challenge, we make three key efforts: (1) A novel Scalable Multimodal QA Synthesis pipeline that autonomously generates context-aware, reasoning-centric question-answer (QA) pairs directly from the given images. (2) The open-source WeThink dataset containing over 120K multimodal QA pairs with annotated reasoning paths, curated from 18 diverse dataset sources and covering various question domains. (3) A comprehensive exploration of RL on our dataset, incorporating a hybrid reward mechanism that combines rule-based verification with model-based assessment to optimize RL training efficiency across various task domains. Across 14 diverse MLLM benchmarks, we demonstrate that our WeThink dataset significantly enhances performance, from mathematical reasoning to diverse general multimodal tasks. Moreover, we show that our automated data pipeline can continuously increase data diversity to further improve model performance.
DFVO: Learning Darkness-free Visible and Infrared Image Disentanglement and Fusion All at Once
May 07, 2025



Visible and infrared image fusion is one of the most crucial tasks in the field of image fusion, aiming to generate fused images with clear structural information and high-quality texture features for high-level vision tasks. However, when faced with severe illumination degradation in visible images, the fusion results of existing image fusion methods often exhibit blurry and dim visual effects, posing major challenges for autonomous driving. To this end, a Darkness-Free network is proposed to handle Visible and infrared image disentanglement and fusion all at Once (DFVO), which employs a cascaded multi-task approach to replace the traditional two-stage cascaded training (enhancement and fusion), addressing the issue of information entropy loss caused by hierarchical data transmission. Specifically, we construct a latent-common feature extractor (LCFE) to obtain latent features for the cascaded tasks strategy. Firstly, a details-extraction module (DEM) is devised to acquire high-frequency semantic information. Secondly, we design a hyper cross-attention module (HCAM) to extract low-frequency information and preserve texture features from source images. Finally, a relevant loss function is designed to guide the holistic network learning, thereby achieving better image fusion. Extensive experiments demonstrate that our proposed approach outperforms state-of-the-art alternatives in terms of qualitative and quantitative evaluations. Particularly, DFVO can generate clearer, more informative, and more evenly illuminated fusion results in the dark environments, achieving best performance on the LLVIP dataset with 63.258 dB PSNR and 0.724 CC, providing more effective information for high-level vision tasks. Our code is publicly accessible at https://github.com/DaVin-Qi530/DFVO.
RoboFactory: Exploring Embodied Agent Collaboration with Compositional Constraints
Mar 20, 2025Designing effective embodied multi-agent systems is critical for solving complex real-world tasks across domains. Due to the complexity of multi-agent embodied systems, existing methods fail to automatically generate safe and efficient training data for such systems. To this end, we propose the concept of compositional constraints for embodied multi-agent systems, addressing the challenges arising from collaboration among embodied agents. We design various interfaces tailored to different types of constraints, enabling seamless interaction with the physical world. Leveraging compositional constraints and specifically designed interfaces, we develop an automated data collection framework for embodied multi-agent systems and introduce the first benchmark for embodied multi-agent manipulation, RoboFactory. Based on RoboFactory benchmark, we adapt and evaluate the method of imitation learning and analyzed its performance in different difficulty agent tasks. Furthermore, we explore the architectures and training strategies for multi-agent imitation learning, aiming to build safe and efficient embodied multi-agent systems.
DriveGEN: Generalized and Robust 3D Detection in Driving via Controllable Text-to-Image Diffusion Generation
Mar 14, 2025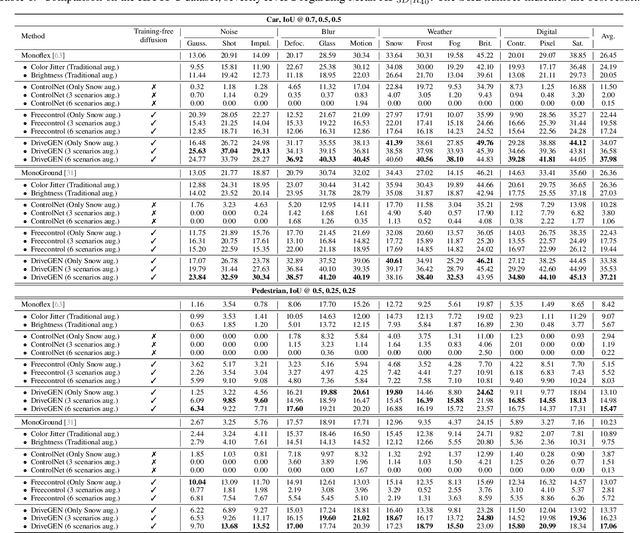


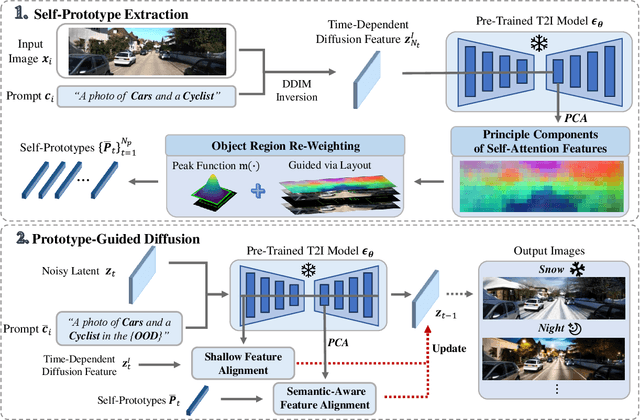
In autonomous driving, vision-centric 3D detection aims to identify 3D objects from images. However, high data collection costs and diverse real-world scenarios limit the scale of training data. Once distribution shifts occur between training and test data, existing methods often suffer from performance degradation, known as Out-of-Distribution (OOD) problems. To address this, controllable Text-to-Image (T2I) diffusion offers a potential solution for training data enhancement, which is required to generate diverse OOD scenarios with precise 3D object geometry. Nevertheless, existing controllable T2I approaches are restricted by the limited scale of training data or struggle to preserve all annotated 3D objects. In this paper, we present DriveGEN, a method designed to improve the robustness of 3D detectors in Driving via Training-Free Controllable Text-to-Image Diffusion Generation. Without extra diffusion model training, DriveGEN consistently preserves objects with precise 3D geometry across diverse OOD generations, consisting of 2 stages: 1) Self-Prototype Extraction: We empirically find that self-attention features are semantic-aware but require accurate region selection for 3D objects. Thus, we extract precise object features via layouts to capture 3D object geometry, termed self-prototypes. 2) Prototype-Guided Diffusion: To preserve objects across various OOD scenarios, we perform semantic-aware feature alignment and shallow feature alignment during denoising. Extensive experiments demonstrate the effectiveness of DriveGEN in improving 3D detection. The code is available at https://github.com/Hongbin98/DriveGEN.