 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision SmolMamba: Spike-Guided Token Pruning for Energy-Efficient Spiking State-Space Vision Models
Apr 28, 2026Spiking Transformers have shown strong potential for long-range visual modeling through spike-driven self-attention. However, their quadratic token interactions remain fundamentally misaligned with the sparse and event-driven nature of spiking neural computation. To address this limitation, we propose Vision SmolMamba, an energy-efficient spiking state-space architecture that integrates spike-driven dynamics with linear-time selective recurrence. The key idea is a Spike-Guided Spatio-Temporal Token Pruner (SST-TP), which estimates token importance using both spike activation strength and first-spike latency. This mechanism progressively removes redundant tokens while preserving salient spatio-temporal information, enabling efficient scaling with token sparsity. Based on this mechanism, the proposed SmolMamba block incorporates spike events directly into bidirectional state-space recurrence, forming a spiking state-space vision backbone for efficient long-range modeling. Extensive experiments on both static and event-based benchmarks, including ImageNet-1K, CIFAR10/100, CIFAR10-DVS, and DVS128 Gesture, demonstrate that Vision SmolMamba consistently achieves superior accuracy-efficiency trade-offs. In particular, it reduces the estimated energy cost by at least 1.5x compared with prior spiking Transformer baselines and a Spiking Mamba variant while maintaining competitive or improved accuracy. These results demonstrate that combining spike-guided token sparsity with state-space modeling offers a scalable and energy-efficient paradigm for spiking vision systems.
UniSonate: A Unified Model for Speech, Music, and Sound Effect Generation with Text Instructions
Apr 24, 2026Generative audio modeling has largely been fragmented into specialized tasks, text-to-speech (TTS), text-to-music (TTM), and text-to-audio (TTA), each operating under heterogeneous control paradigms. Unifying these modalities remains a fundamental challenge due to the intrinsic dissonance between structured semantic representations (speech/music) and unstructured acoustic textures (sound effects). In this paper, we introduce UniSonate, a unified flow-matching framework capable of synthesizing speech, music, and sound effects through a standardized, reference-free natural language instruction interface. To reconcile structural disparities, we propose a novel dynamic token injection mechanism that projects unstructured environmental sounds into a structured temporal latent space, enabling precise duration control within a phoneme-driven Multimodal Diffusion Transformer (MM-DiT). Coupled with a multi-stage curriculum learning strategy, this approach effectively mitigates cross-modal optimization conflicts. Extensive experiments demonstrate that UniSonate achieves state-of-the-art performance in instruction-based TTS (WER 1.47%) and TTM (SongEval Coherence 3.18), while maintaining competitive fidelity in TTA. Crucially, we observe positive transfer, where joint training on diverse audio data significantly enhances structural coherence and prosodic expressiveness compared to single-task baselines. Audio samples are available at https://qiangchunyu.github.io/UniSonate/.
Fast Converging 3D Gaussian Splatting for 1-Minute Reconstruction
Jan 27, 2026We present a fast 3DGS reconstruction pipeline designed to converge within one minute, developed for the SIGGRAPH Asia 3DGS Fast Reconstruction Challenge. The challenge consists of an initial round using SLAM-generated camera poses (with noisy trajectories) and a final round using COLMAP poses (highly accurate). To robustly handle these heterogeneous settings, we develop a two-stage solution. In the first round, we use reverse per-Gaussian parallel optimization and compact forward splatting based on Taming-GS and Speedy-splat, load-balanced tiling, an anchor-based Neural-Gaussian representation enabling rapid convergence with fewer learnable parameters, initialization from monocular depth and partially from feed-forward 3DGS models, and a global pose refinement module for noisy SLAM trajectories. In the final round, the accurate COLMAP poses change the optimization landscape; we disable pose refinement, revert from Neural-Gaussians back to standard 3DGS to eliminate MLP inference overhead, introduce multi-view consistency-guided Gaussian splitting inspired by Fast-GS, and introduce a depth estimator to supervise the rendered depth. Together, these techniques enable high-fidelity reconstruction under a strict one-minute budget. Our method achieved the top performance with a PSNR of 28.43 and ranked first in the competition.
VoiceSculptor: Your Voice, Designed By You
Jan 15, 2026Despite rapid progress in text-to-speech (TTS), open-source systems still lack truly instruction-following, fine-grained control over core speech attributes (e.g., pitch, speaking rate, age, emotion, and style). We present VoiceSculptor, an open-source unified system that bridges this gap by integrating instruction-based voice design and high-fidelity voice cloning in a single framework. It generates controllable speaker timbre directly from natural-language descriptions, supports iterative refinement via Retrieval-Augmented Generation (RAG), and provides attribute-level edits across multiple dimensions. The designed voice is then rendered into a prompt waveform and fed into a cloning model to enable high-fidelity timbre transfer for downstream speech synthesis. VoiceSculptor achieves open-source state-of-the-art (SOTA) on InstructTTSEval-Zh, and is fully open-sourced, including code and pretrained models, to advance reproducible instruction-controlled TTS research.
Atlas is Your Perfect Context: One-Shot Customization for Generalizable Foundational Medical Image Segmentation
Dec 20, 2025



Accurate medical image segmentation is essential for clinical diagnosis and treatment planning. While recent interactive foundation models (e.g., nnInteractive) enhance generalization through large-scale multimodal pretraining, they still depend on precise prompts and often perform below expectations in contexts that are underrepresented in their training data. We present AtlasSegFM, an atlas-guided framework that customizes available foundation models to clinical contexts with a single annotated example. The core innovations are: 1) a pipeline that provides context-aware prompts for foundation models via registration between a context atlas and query images, and 2) a test-time adapter to fuse predictions from both atlas registration and the foundation model. Extensive experiments across public and in-house datasets spanning multiple modalities and organs demonstrate that AtlasSegFM consistently improves segmentation, particularly for small, delicate structures. AtlasSegFM provides a lightweight, deployable solution one-shot customization of foundation models in real-world clinical workflows. The code will be made publicly available.
KramaBench: A Benchmark for AI Systems on Data-to-Insight Pipelines over Data Lakes
Jun 06, 2025Constructing real-world data-to-insight pipelines often involves data extraction from data lakes, data integration across heterogeneous data sources, and diverse operations from data cleaning to analysis. The design and implementation of data science pipelines require domain knowledge, technical expertise, and even project-specific insights. AI systems have shown remarkable reasoning, coding, and understanding capabilities. However, it remains unclear to what extent these capabilities translate into successful design and execution of such complex pipelines. We introduce KRAMABENCH: a benchmark composed of 104 manually-curated real-world data science pipelines spanning 1700 data files from 24 data sources in 6 different domains. We show that these pipelines test the end-to-end capabilities of AI systems on data processing, requiring data discovery, wrangling and cleaning, efficient processing, statistical reasoning, and orchestrating data processing steps given a high-level task. Our evaluation tests 5 general models and 3 code generation models using our reference framework, DS-GURU, which instructs the AI model to decompose a question into a sequence of subtasks, reason through each step, and synthesize Python code that implements the proposed design. Our results on KRAMABENCH show that, although the models are sufficiently capable of solving well-specified data science code generation tasks, when extensive data processing and domain knowledge are required to construct real-world data science pipelines, existing out-of-box models fall short. Progress on KramaBench represents crucial steps towards developing autonomous data science agents for real-world applications. Our code, reference framework, and data are available at https://github.com/mitdbg/KramaBench.
Decomposability-Guaranteed Cooperative Coevolution for Large-Scale Itinerary Planning
Jun 06, 2025Large-scale itinerary planning is a variant of the traveling salesman problem, aiming to determine an optimal path that maximizes the collected points of interest (POIs) scores while minimizing travel time and cost, subject to travel duration constraints. This paper analyzes the decomposability of large-scale itinerary planning, proving that strict decomposability is difficult to satisfy, and introduces a weak decomposability definition based on a necessary condition, deriving the corresponding graph structures that fulfill this property. With decomposability guaranteed, we propose a novel multi-objective cooperative coevolutionary algorithm for large-scale itinerary planning, addressing the challenges of component imbalance and interactions. Specifically, we design a dynamic decomposition strategy based on the normalized fitness within each component, define optimization potential considering component scale and contribution, and develop a computational resource allocation strategy. Finally, we evaluate the proposed algorithm on a set of real-world datasets. Comparative experiments with state-of-the-art multi-objective itinerary planning algorithms demonstrate the superiority of our approach, with performance advantages increasing as the problem scale grows.
Decoding Speaker-Normalized Pitch from EEG for Mandarin Perception
May 26, 2025The same speech content produced by different speakers exhibits significant differences in pitch contour, yet listeners' semantic perception remains unaffected. This phenomenon may stem from the brain's perception of pitch contours being independent of individual speakers' pitch ranges. In this work, we recorded electroencephalogram (EEG) while participants listened to Mandarin monosyllables with varying tones, phonemes, and speakers. The CE-ViViT model is proposed to decode raw or speaker-normalized pitch contours directly from EEG. Experimental results demonstrate that the proposed model can decode pitch contours with modest errors, achieving performance comparable to state-of-the-art EEG regression methods. Moreover, speaker-normalized pitch contours were decoded more accurately, supporting the neural encoding of relative pitch.
ADD: Physics-Based Motion Imitation with Adversarial Differential Discriminators
May 08, 2025



Multi-objective optimization problems, which require the simultaneous optimization of multiple terms, are prevalent across numerous applications. Existing multi-objective optimization methods often rely on manually tuned aggregation functions to formulate a joint optimization target. The performance of such hand-tuned methods is heavily dependent on careful weight selection, a time-consuming and laborious process. These limitations also arise in the setting of reinforcement-learning-based motion tracking for physically simulated characters, where intricately crafted reward functions are typically used to achieve high-fidelity results. Such solutions not only require domain expertise and significant manual adjustment, but also limit the applicability of the resulting reward function across diverse skills. To bridge this gap, we present a novel adversarial multi-objective optimization technique that is broadly applicable to a range of multi-objective optimization problems, including motion tracking. The proposed adversarial differential discriminator receives a single positive sample, yet is still effective at guiding the optimization process. We demonstrate that our technique can enable characters to closely replicate a variety of acrobatic and agile behaviors, achieving comparable quality to state-of-the-art motion-tracking methods, without relying on manually tuned reward functions. Results are best visualized through https://youtu.be/rz8BYCE9E2w.
Spark-TTS: An Efficient LLM-Based Text-to-Speech Model with Single-Stream Decoupled Speech Tokens
Mar 03, 2025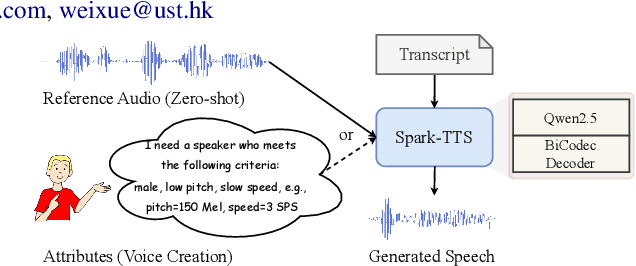



Recent advancements in large language models (LLMs) have driven significant progress in zero-shot text-to-speech (TTS) synthesis. However, existing foundation models rely on multi-stage processing or complex architectures for predicting multiple codebooks, limiting efficiency and integration flexibility. To overcome these challenges, we introduce Spark-TTS, a novel system powered by BiCodec, a single-stream speech codec that decomposes speech into two complementary token types: low-bitrate semantic tokens for linguistic content and fixed-length global tokens for speaker attributes. This disentangled representation, combined with the Qwen2.5 LLM and a chain-of-thought (CoT) generation approach, enables both coarse-grained control (e.g., gender, speaking style) and fine-grained adjustments (e.g., precise pitch values, speaking rate). To facilitate research in controllable TTS, we introduce VoxBox, a meticulously curated 100,000-hour dataset with comprehensive attribute annotations. Extensive experiments demonstrate that Spark-TTS not only achieves state-of-the-art zero-shot voice cloning but also generates highly customizable voices that surpass the limitations of reference-based synthesis. Source code, pre-trained models, and audio samples are available at https://github.com/SparkAudio/Spark-TTS.