 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenRR-1k: A Scalable Dataset for Real-World Reflection Removal
Jun 10, 2025Reflection removal technology plays a crucial role in photography and computer vision applications. However, existing techniques are hindered by the lack of high-quality in-the-wild datasets. In this paper, we propose a novel paradigm for collecting reflection datasets from a fresh perspective. Our approach is convenient, cost-effective, and scalable, while ensuring that the collected data pairs are of high quality, perfectly aligned, and represent natural and diverse scenarios. Following this paradigm, we collect a Real-world, Diverse, and Pixel-aligned dataset (named OpenRR-1k dataset), which contains 1,000 high-quality transmission-reflection image pairs collected in the wild. Through the analysis of several reflection removal methods and benchmark evaluation experiments on our dataset, we demonstrate its effectiveness in improving robustness in challenging real-world environments. Our dataset is available at https://github.com/caijie0620/OpenRR-1k.
F2T2-HiT: A U-Shaped FFT Transformer and Hierarchical Transformer for Reflection Removal
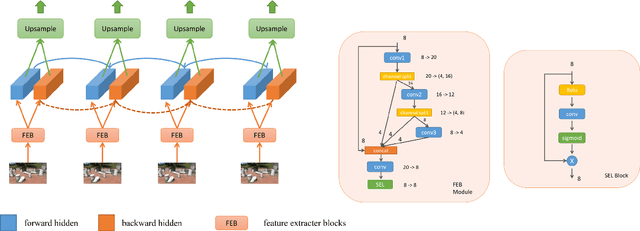
Jun 05, 2025Single Image Reflection Removal (SIRR) technique plays a crucial role in image processing by eliminating unwanted reflections from the background. These reflections, often caused by photographs taken through glass surfaces, can significantly degrade image quality. SIRR remains a challenging problem due to the complex and varied reflections encountered in real-world scenarios. These reflections vary significantly in intensity, shapes, light sources, sizes, and coverage areas across the image, posing challenges for most existing methods to effectively handle all cases. To address these challenges, this paper introduces a U-shaped Fast Fourier Transform Transformer and Hierarchical Transformer (F2T2-HiT) architecture, an innovative Transformer-based design for SIRR. Our approach uniquely combines Fast Fourier Transform (FFT) Transformer blocks and Hierarchical Transformer blocks within a UNet framework. The FFT Transformer blocks leverage the global frequency domain information to effectively capture and separate reflection patterns, while the Hierarchical Transformer blocks utilize multi-scale feature extraction to handle reflections of varying sizes and complexities. Extensive experiments conducted on three publicly available testing datasets demonstrate state-of-the-art performance, validating the effectiveness of our approach.
Survey on Single-Image Reflection Removal using Deep Learning Techniques
Feb 12, 2025The phenomenon of reflection is quite common in digital images, posing significant challenges for various applications such as computer vision, photography, and image processing. Traditional methods for reflection removal often struggle to achieve clean results while maintaining high fidelity and robustness, particularly in real-world scenarios. Over the past few decades, numerous deep learning-based approaches for reflection removal have emerged, yielding impressive results. In this survey, we conduct a comprehensive review of the current literature by focusing on key venues such as ICCV, ECCV, CVPR, NeurIPS, etc., as these conferences and journals have been central to advances in the field. Our review follows a structured paper selection process, and we critically assess both single-stage and two-stage deep learning methods for reflection removal. The contribution of this survey is three-fold: first, we provide a comprehensive summary of the most recent work on single-image reflection removal; second, we outline task hypotheses, current deep learning techniques, publicly available datasets, and relevant evaluation metrics; and third, we identify key challenges and opportunities in deep learning-based reflection removal, highlighting the potential of this rapidly evolving research area.
Real-Time Super-Resolution for Real-World Images on Mobile Devices
Jun 03, 2022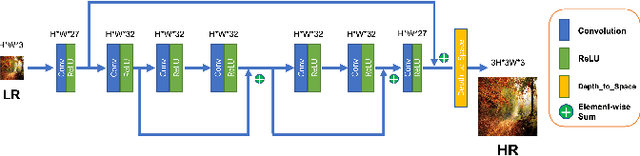
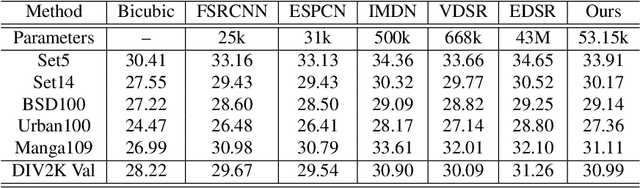
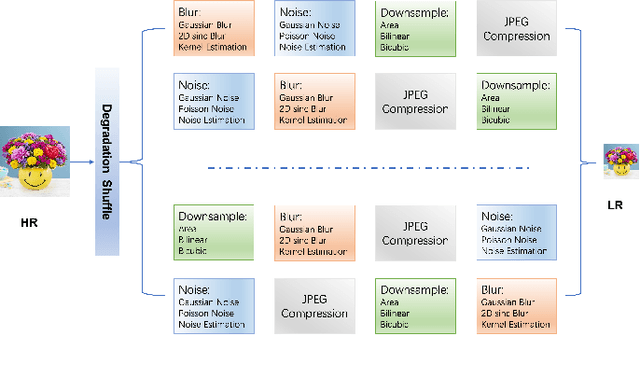
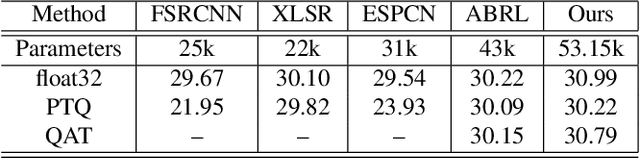
Image Super-Resolution (ISR), which aims at recovering High-Resolution (HR) images from the corresponding Low-Resolution (LR) counterparts. Although recent progress in ISR has been remarkable. However, they are way too computationally intensive to be deployed on edge devices, since most of the recent approaches are deep learning-based. Besides, these methods always fail in real-world scenes, since most of them adopt a simple fixed "ideal" bicubic downsampling kernel from high-quality images to construct LR/HR training pairs which may lose track of frequency-related details. In this work, an approach for real-time ISR on mobile devices is presented, which is able to deal with a wide range of degradations in real-world scenarios. Extensive experiments on traditional super-resolution datasets (Set5, Set14, BSD100, Urban100, Manga109, DIV2K) and real-world images with a variety of degradations demonstrate that our method outperforms the state-of-art methods, resulting in higher PSNR and SSIM, lower noise and better visual quality. Most importantly, our method achieves real-time performance on mobile or edge devices.
MM-ViT: Multi-Modal Video Transformer for Compressed Video Action Recognition
Aug 20, 2021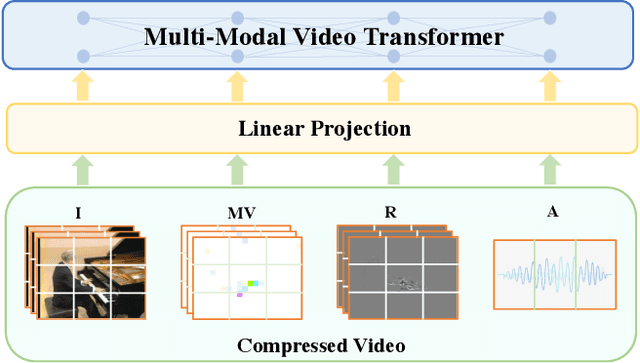
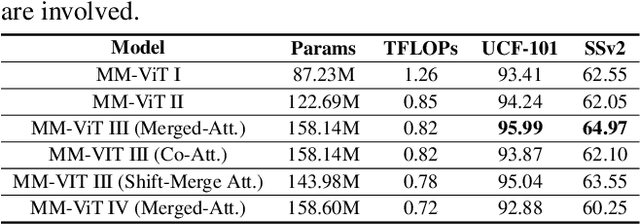
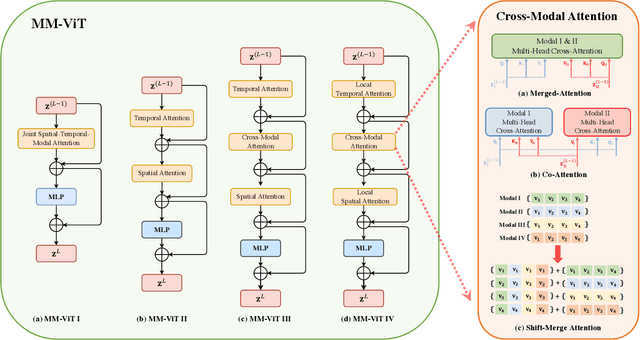
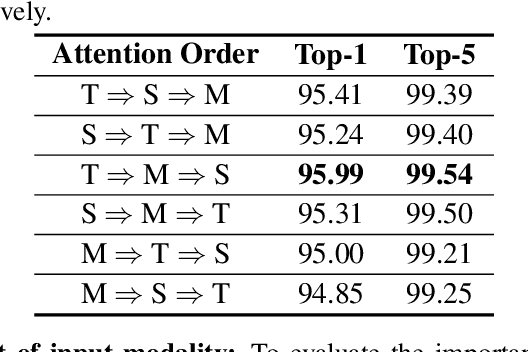
This paper presents a pure transformer-based approach, dubbed the Multi-Modal Video Transformer (MM-ViT), for video action recognition. Different from other schemes which solely utilize the decoded RGB frames, MM-ViT operates exclusively in the compressed video domain and exploits all readily available modalities, i.e., I-frames, motion vectors, residuals and audio waveform. In order to handle the large number of spatiotemporal tokens extracted from multiple modalities, we develop several scalable model variants which factorize self-attention across the space, time and modality dimensions. In addition, to further explore the rich inter-modal interactions and their effects, we develop and compare three distinct cross-modal attention mechanisms that can be seamlessly integrated into the transformer building block. Extensive experiments on three public action recognition benchmarks (UCF-101, Something-Something-v2, Kinetics-600) demonstrate that MM-ViT outperforms the state-of-the-art video transformers in both efficiency and accuracy, and performs better or equally well to the state-of-the-art CNN counterparts with computationally-heavy optical flow.
RSCA: Real-time Segmentation-based Context-Aware Scene Text Detection
May 26, 2021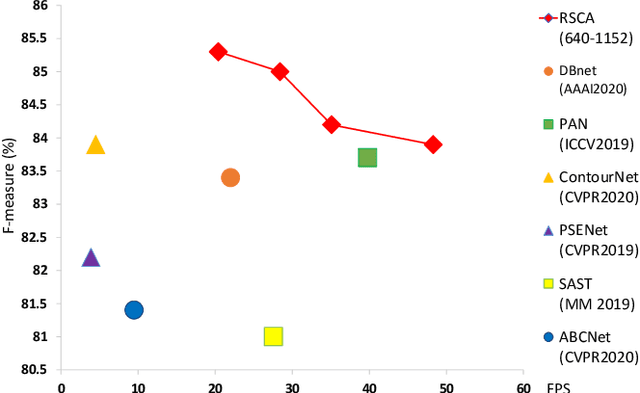
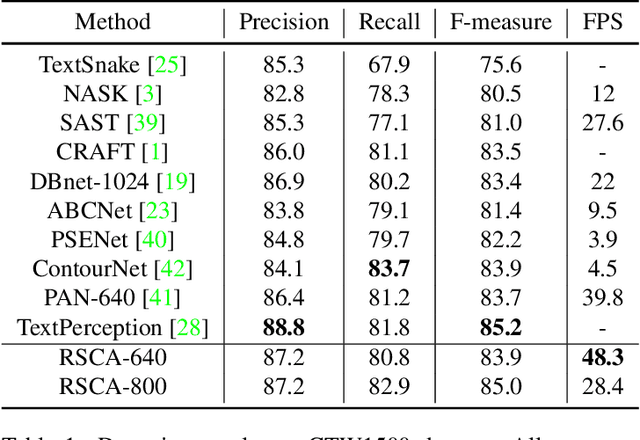
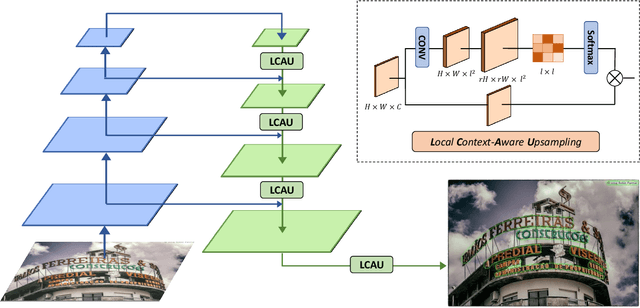
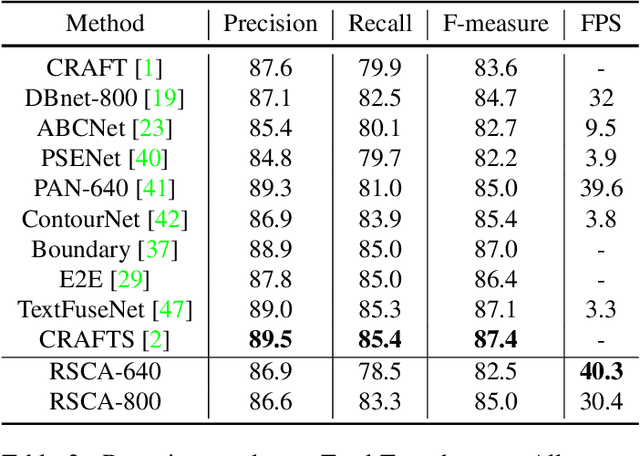
Segmentation-based scene text detection methods have been widely adopted for arbitrary-shaped text detection recently, since they make accurate pixel-level predictions on curved text instances and can facilitate real-time inference without time-consuming processing on anchors. However, current segmentation-based models are unable to learn the shapes of curved texts and often require complex label assignments or repeated feature aggregations for more accurate detection. In this paper, we propose RSCA: a Real-time Segmentation-based Context-Aware model for arbitrary-shaped scene text detection, which sets a strong baseline for scene text detection with two simple yet effective strategies: Local Context-Aware Upsampling and Dynamic Text-Spine Labeling, which model local spatial transformation and simplify label assignments separately. Based on these strategies, RSCA achieves state-of-the-art performance in both speed and accuracy, without complex label assignments or repeated feature aggregations. We conduct extensive experiments on multiple benchmarks to validate the effectiveness of our method. RSCA-640 reaches 83.9% F-measure at 48.3 FPS on CTW1500 dataset.
Real-Time Video Super-Resolution on Smartphones with Deep Learning, Mobile AI 2021 Challenge: Report
May 17, 2021

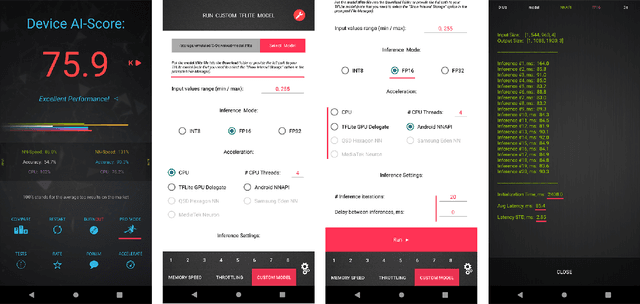
Video super-resolution has recently become one of the most important mobile-related problems due to the rise of video communication and streaming services. While many solutions have been proposed for this task, the majority of them are too computationally expensive to run on portable devices with limited hardware resources. To address this problem, we introduce the first Mobile AI challenge, where the target is to develop an end-to-end deep learning-based video super-resolution solutions that can achieve a real-time performance on mobile GPUs. The participants were provided with the REDS dataset and trained their models to do an efficient 4X video upscaling. The runtime of all models was evaluated on the OPPO Find X2 smartphone with the Snapdragon 865 SoC capable of accelerating floating-point networks on its Adreno GPU. The proposed solutions are fully compatible with any mobile GPU and can upscale videos to HD resolution at up to 80 FPS while demonstrating high fidelity results. A detailed description of all models developed in the challenge is provided in this paper.
AIM 2020 Challenge on Efficient Super-Resolution: Methods and Results
Sep 15, 2020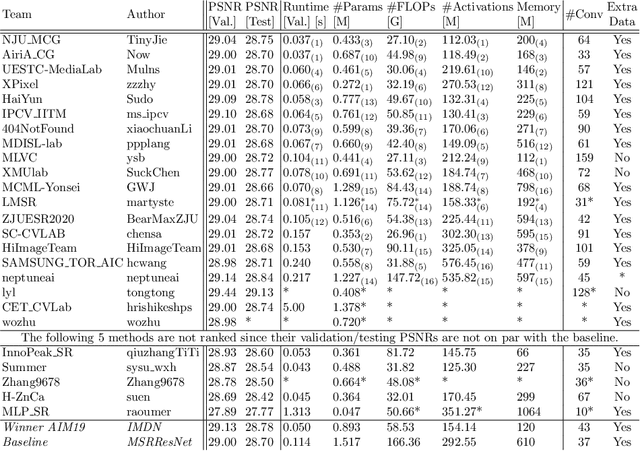
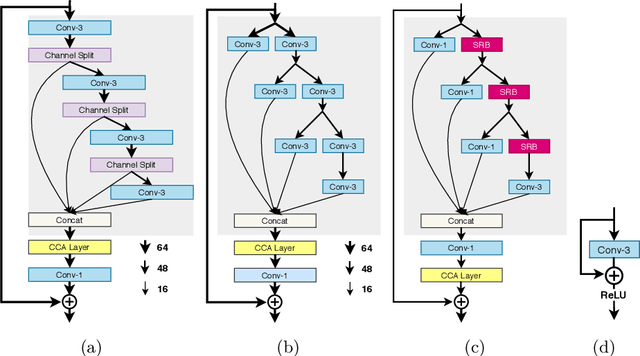
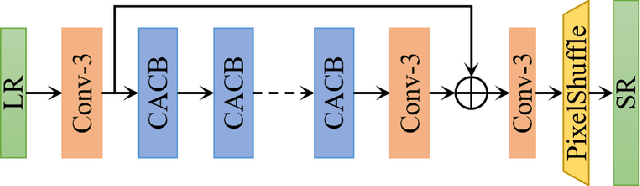
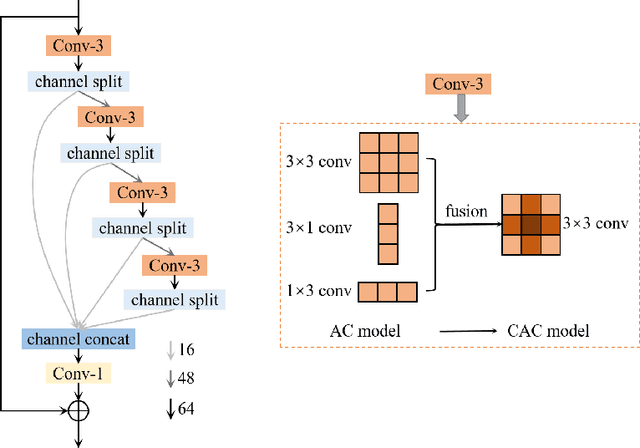
This paper reviews the AIM 2020 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The challenge task was to super-resolve an input image with a magnification factor x4 based on a set of prior examples of low and corresponding high resolution images. The goal is to devise a network that reduces one or several aspects such as runtime, parameter count, FLOPs, activations, and memory consumption while at least maintaining PSNR of MSRResNet. The track had 150 registered participants, and 25 teams submitted the final results. They gauge the state-of-the-art in efficient single image super-resolution.
GIA-Net: Global Information Aware Network for Low-light Imaging
Sep 14, 2020
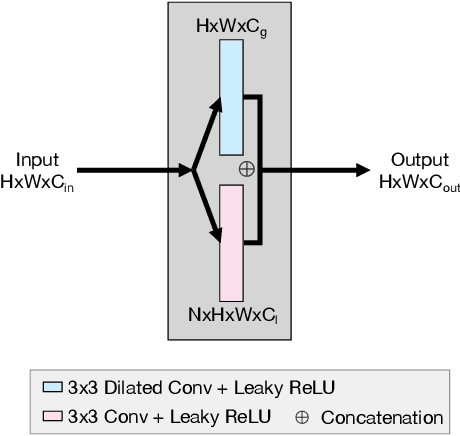
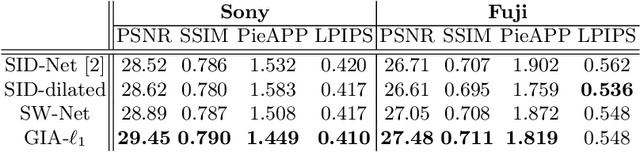
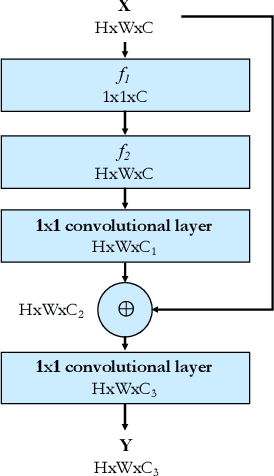
It is extremely challenging to acquire perceptually plausible images under low-light conditions due to low SNR. Most recently, U-Nets have shown promising results for low-light imaging. However, vanilla U-Nets generate images with artifacts such as color inconsistency due to the lack of global color information. In this paper, we propose a global information aware (GIA) module, which is capable of extracting and integrating the global information into the network to improve the performance of low-light imaging. The GIA module can be inserted into a vanilla U-Net with negligible extra learnable parameters or computational cost. Moreover, a GIA-Net is constructed, trained and evaluated on a large scale real-world low-light imaging dataset. Experimental results show that the proposed GIA-Net outperforms the state-of-the-art methods in terms of four metrics, including deep metrics that measure perceptual similarities. Extensive ablation studies have been conducted to verify the effectiveness of the proposed GIA-Net for low-light imaging by utilizing global information.
Residual Frames with Efficient Pseudo-3D CNN for Human Action Recognition
Aug 03, 2020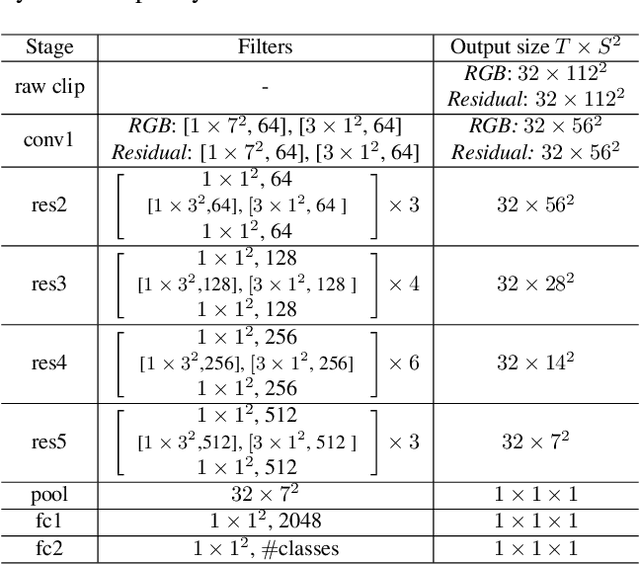
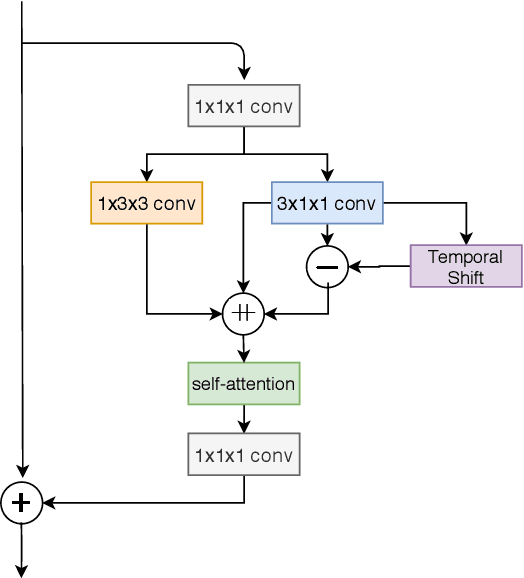
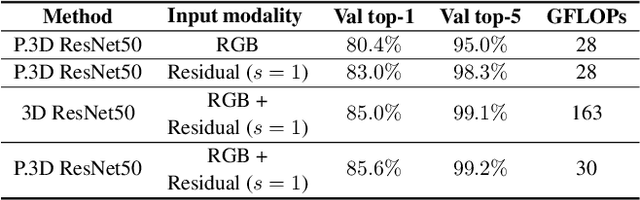

Human action recognition is regarded as a key cornerstone in domains such as surveillance or video understanding. Despite recent progress in the development of end-to-end solutions for video-based action recognition, achieving state-of-the-art performance still requires using auxiliary hand-crafted motion representations, e.g., optical flow, which are usually computationally demanding. In this work, we propose to use residual frames (i.e., differences between adjacent RGB frames) as an alternative "lightweight" motion representation, which carries salient motion information and is computationally efficient. In addition, we develop a new pseudo-3D convolution module which decouples 3D convolution into 2D and 1D convolution. The proposed module exploits residual information in the feature space to better structure motions, and is equipped with a self-attention mechanism that assists to recalibrate the appearance and motion features. Empirical results confirm the efficiency and effectiveness of residual frames as well as the proposed pseudo-3D convolution module.