 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWavReward: Spoken Dialogue Models With Generalist Reward Evaluators
May 14, 2025End-to-end spoken dialogue models such as GPT-4o-audio have recently garnered significant attention in the speech domain. However, the evaluation of spoken dialogue models' conversational performance has largely been overlooked. This is primarily due to the intelligent chatbots convey a wealth of non-textual information which cannot be easily measured using text-based language models like ChatGPT. To address this gap, we propose WavReward, a reward feedback model based on audio language models that can evaluate both the IQ and EQ of spoken dialogue systems with speech input. Specifically, 1) based on audio language models, WavReward incorporates the deep reasoning process and the nonlinear reward mechanism for post-training. By utilizing multi-sample feedback via the reinforcement learning algorithm, we construct a specialized evaluator tailored to spoken dialogue models. 2) We introduce ChatReward-30K, a preference dataset used to train WavReward. ChatReward-30K includes both comprehension and generation aspects of spoken dialogue models. These scenarios span various tasks, such as text-based chats, nine acoustic attributes of instruction chats, and implicit chats. WavReward outperforms previous state-of-the-art evaluation models across multiple spoken dialogue scenarios, achieving a substantial improvement about Qwen2.5-Omni in objective accuracy from 55.1$\%$ to 91.5$\%$. In subjective A/B testing, WavReward also leads by a margin of 83$\%$. Comprehensive ablation studies confirm the necessity of each component of WavReward. All data and code will be publicly at https://github.com/jishengpeng/WavReward after the paper is accepted.
Rejoining fragmented ancient bamboo slips with physics-driven deep learning
May 13, 2025



Bamboo slips are a crucial medium for recording ancient civilizations in East Asia, and offers invaluable archaeological insights for reconstructing the Silk Road, studying material culture exchanges, and global history. However, many excavated bamboo slips have been fragmented into thousands of irregular pieces, making their rejoining a vital yet challenging step for understanding their content. Here we introduce WisePanda, a physics-driven deep learning framework designed to rejoin fragmented bamboo slips. Based on the physics of fracture and material deterioration, WisePanda automatically generates synthetic training data that captures the physical properties of bamboo fragmentations. This approach enables the training of a matching network without requiring manually paired samples, providing ranked suggestions to facilitate the rejoining process. Compared to the leading curve matching method, WisePanda increases Top-50 matching accuracy from 36\% to 52\%. Archaeologists using WisePanda have experienced substantial efficiency improvements (approximately 20 times faster) when rejoining fragmented bamboo slips. This research demonstrates that incorporating physical principles into deep learning models can significantly enhance their performance, transforming how archaeologists restore and study fragmented artifacts. WisePanda provides a new paradigm for addressing data scarcity in ancient artifact restoration through physics-driven machine learning.
LiftFeat: 3D Geometry-Aware Local Feature Matching
May 06, 2025



Robust and efficient local feature matching plays a crucial role in applications such as SLAM and visual localization for robotics. Despite great progress, it is still very challenging to extract robust and discriminative visual features in scenarios with drastic lighting changes, low texture areas, or repetitive patterns. In this paper, we propose a new lightweight network called \textit{LiftFeat}, which lifts the robustness of raw descriptor by aggregating 3D geometric feature. Specifically, we first adopt a pre-trained monocular depth estimation model to generate pseudo surface normal label, supervising the extraction of 3D geometric feature in terms of predicted surface normal. We then design a 3D geometry-aware feature lifting module to fuse surface normal feature with raw 2D descriptor feature. Integrating such 3D geometric feature enhances the discriminative ability of 2D feature description in extreme conditions. Extensive experimental results on relative pose estimation, homography estimation, and visual localization tasks, demonstrate that our LiftFeat outperforms some lightweight state-of-the-art methods. Code will be released at : https://github.com/lyp-deeplearning/LiftFeat.
RoboGround: Robotic Manipulation with Grounded Vision-Language Priors
Apr 30, 2025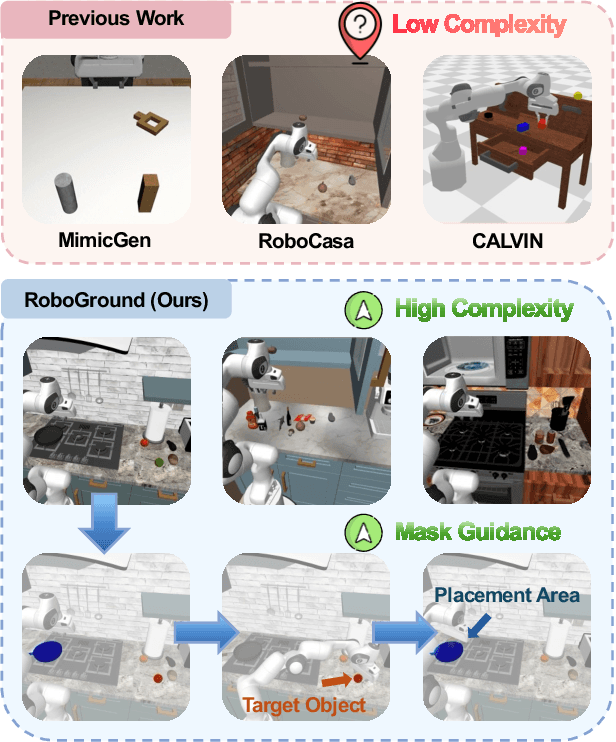

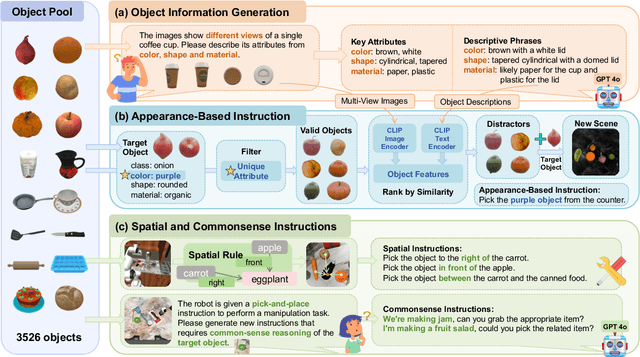
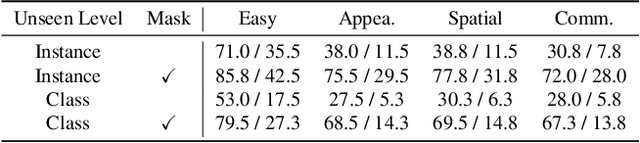
Recent advancements in robotic manipulation have highlighted the potential of intermediate representations for improving policy generalization. In this work, we explore grounding masks as an effective intermediate representation, balancing two key advantages: (1) effective spatial guidance that specifies target objects and placement areas while also conveying information about object shape and size, and (2) broad generalization potential driven by large-scale vision-language models pretrained on diverse grounding datasets. We introduce RoboGround, a grounding-aware robotic manipulation system that leverages grounding masks as an intermediate representation to guide policy networks in object manipulation tasks. To further explore and enhance generalization, we propose an automated pipeline for generating large-scale, simulated data with a diverse set of objects and instructions. Extensive experiments show the value of our dataset and the effectiveness of grounding masks as intermediate guidance, significantly enhancing the generalization abilities of robot policies.
ISDrama: Immersive Spatial Drama Generation through Multimodal Prompting
Apr 29, 2025Multimodal immersive spatial drama generation focuses on creating continuous multi-speaker binaural speech with dramatic prosody based on multimodal prompts, with potential applications in AR, VR, and others. This task requires simultaneous modeling of spatial information and dramatic prosody based on multimodal inputs, with high data collection costs. To the best of our knowledge, our work is the first attempt to address these challenges. We construct MRSDrama, the first multimodal recorded spatial drama dataset, containing binaural drama audios, scripts, videos, geometric poses, and textual prompts. Then, we propose ISDrama, the first immersive spatial drama generation model through multimodal prompting. ISDrama comprises these primary components: 1) Multimodal Pose Encoder, based on contrastive learning, considering the Doppler effect caused by moving speakers to extract unified pose information from multimodal prompts. 2) Immersive Drama Transformer, a flow-based mamba-transformer model that generates high-quality drama, incorporating Drama-MOE to select proper experts for enhanced prosody and pose control. We also design a context-consistent classifier-free guidance strategy to coherently generate complete drama. Experimental results show that ISDrama outperforms baseline models on objective and subjective metrics. The demos and dataset are available at https://aaronz345.github.io/ISDramaDemo.
Versatile Framework for Song Generation with Prompt-based Control
Apr 29, 2025Song generation focuses on producing controllable high-quality songs based on various prompts. However, existing methods struggle to generate vocals and accompaniments with prompt-based control and proper alignment. Additionally, they fall short in supporting various tasks. To address these challenges, we introduce VersBand, a multi-task song generation framework for synthesizing high-quality, aligned songs with prompt-based control. VersBand comprises these primary models: 1) VocalBand, a decoupled model, leverages the flow-matching method for generating singing styles, pitches, and mel-spectrograms, allowing fast, high-quality vocal generation with style control. 2) AccompBand, a flow-based transformer model, incorporates the Band-MOE, selecting suitable experts for enhanced quality, alignment, and control. This model allows for generating controllable, high-quality accompaniments aligned with vocals. 3) Two generation models, LyricBand for lyrics and MelodyBand for melodies, contribute to the comprehensive multi-task song generation system, allowing for extensive control based on multiple prompts. Experimental results demonstrate that VersBand performs better over baseline models across multiple song generation tasks using objective and subjective metrics. Audio samples are available at https://aaronz345.github.io/VersBandDemo.
Unleashing the Power of Natural Audio Featuring Multiple Sound Sources
Apr 24, 2025Universal sound separation aims to extract clean audio tracks corresponding to distinct events from mixed audio, which is critical for artificial auditory perception. However, current methods heavily rely on artificially mixed audio for training, which limits their ability to generalize to naturally mixed audio collected in real-world environments. To overcome this limitation, we propose ClearSep, an innovative framework that employs a data engine to decompose complex naturally mixed audio into multiple independent tracks, thereby allowing effective sound separation in real-world scenarios. We introduce two remix-based evaluation metrics to quantitatively assess separation quality and use these metrics as thresholds to iteratively apply the data engine alongside model training, progressively optimizing separation performance. In addition, we propose a series of training strategies tailored to these separated independent tracks to make the best use of them. Extensive experiments demonstrate that ClearSep achieves state-of-the-art performance across multiple sound separation tasks, highlighting its potential for advancing sound separation in natural audio scenarios. For more examples and detailed results, please visit our demo page at https://clearsep.github.io.
OmniAudio: Generating Spatial Audio from 360-Degree Video
Apr 21, 2025


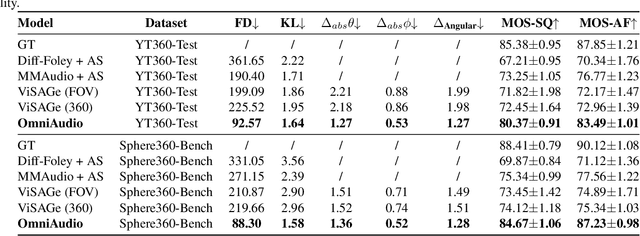
Traditional video-to-audio generation techniques primarily focus on field-of-view (FoV) video and non-spatial audio, often missing the spatial cues necessary for accurately representing sound sources in 3D environments. To address this limitation, we introduce a novel task, 360V2SA, to generate spatial audio from 360-degree videos, specifically producing First-order Ambisonics (FOA) audio - a standard format for representing 3D spatial audio that captures sound directionality and enables realistic 3D audio reproduction. We first create Sphere360, a novel dataset tailored for this task that is curated from real-world data. We also design an efficient semi-automated pipeline for collecting and cleaning paired video-audio data. To generate spatial audio from 360-degree video, we propose a novel framework OmniAudio, which leverages self-supervised pre-training using both spatial audio data (in FOA format) and large-scale non-spatial data. Furthermore, OmniAudio features a dual-branch framework that utilizes both panoramic and FoV video inputs to capture comprehensive local and global information from 360-degree videos. Experimental results demonstrate that OmniAudio achieves state-of-the-art performance across both objective and subjective metrics on Sphere360. Code and datasets will be released at https://github.com/liuhuadai/OmniAudio. The demo page is available at https://OmniAudio-360V2SA.github.io.
Continual Cross-Modal Generalization
Apr 01, 2025Cross-modal generalization aims to learn a shared discrete representation space from multimodal pairs, enabling knowledge transfer across unannotated modalities. However, achieving a unified representation for all modality pairs requires extensive paired data, which is often impractical. Inspired by the availability of abundant bimodal data (e.g., in ImageBind), we explore a continual learning approach that incrementally maps new modalities into a shared discrete codebook via a mediator modality. We propose the Continual Mixture of Experts Adapter (CMoE-Adapter) to project diverse modalities into a unified space while preserving prior knowledge. To align semantics across stages, we introduce a Pseudo-Modality Replay (PMR) mechanism with a dynamically expanding codebook, enabling the model to adaptively incorporate new modalities using learned ones as guidance. Extensive experiments on image-text, audio-text, video-text, and speech-text show that our method achieves strong performance on various cross-modal generalization tasks. Code is provided in the supplementary material.
Pathological Prior-Guided Multiple Instance Learning For Mitigating Catastrophic Forgetting in Breast Cancer Whole Slide Image Classification
Mar 08, 2025In histopathology, intelligent diagnosis of Whole Slide Images (WSIs) is essential for automating and objectifying diagnoses, reducing the workload of pathologists. However, diagnostic models often face the challenge of forgetting previously learned data during incremental training on datasets from different sources. To address this issue, we propose a new framework PaGMIL to mitigate catastrophic forgetting in breast cancer WSI classification. Our framework introduces two key components into the common MIL model architecture. First, it leverages microscopic pathological prior to select more accurate and diverse representative patches for MIL. Secondly, it trains separate classification heads for each task and uses macroscopic pathological prior knowledge, treating the thumbnail as a prompt guide (PG) to select the appropriate classification head. We evaluate the continual learning performance of PaGMIL across several public breast cancer datasets. PaGMIL achieves a better balance between the performance of the current task and the retention of previous tasks, outperforming other continual learning methods. Our code will be open-sourced upon acceptance.