 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTalker-T2AV: Joint Talking Audio-Video Generation with Autoregressive Diffusion Modeling
Apr 26, 2026Joint audio-video generation models have shown that unified generation yields stronger cross-modal coherence than cascaded approaches. However, existing models couple modalities throughout denoising via pervasive attention, treating high-level semantics and low-level details in a fully entangled manner. This is suboptimal for talking head synthesis: while audio and facial motion are semantically correlated, their low-level realizations (acoustic signals and visual textures) follow distinct rendering processes. Enforcing joint modeling across all levels causes unnecessary entanglement and reduces efficiency. We propose Talker-T2AV, an autoregressive diffusion framework where high-level cross-modal modeling occurs in a shared backbone, while low-level refinement uses modality-specific decoders. A shared autoregressive language model jointly reasons over audio and video in a unified patch-level token space. Two lightweight diffusion transformer heads decode the hidden states into frame-level audio and video latents. Experiments on talking portrait benchmarks show Talker-T2AV outperforms dual-branch baselines in lip-sync accuracy, video quality, and audio quality, achieving stronger cross-modal consistency than cascaded pipelines.
Pause or Fabricate? Training Language Models for Grounded Reasoning
Apr 21, 2026Large language models have achieved remarkable progress on complex reasoning tasks. However, they often implicitly fabricate information when inputs are incomplete, producing confident but unreliable conclusions -- a failure mode we term ungrounded reasoning. We argue that this issue arises not from insufficient reasoning capability, but from the lack of inferential boundary awareness -- the ability to recognize when the necessary premises for valid inference are missing. To address this issue, we propose Grounded Reasoning via Interactive Reinforcement Learning (GRIL), a multi-turn reinforcement learning framework for grounded reasoning under incomplete information. GRIL decomposes the reasoning process into two stages: clarify and pause, which identifies whether the available information is sufficient, and grounded reasoning, which performs task solving once the necessary premises are established. We design stage-specific rewards to penalize hallucinations, enabling models to detect gaps, stop proactively, and resume reasoning after clarification. Experiments on GSM8K-Insufficient and MetaMATH-Insufficient show that GRIL significantly improves premise detection (up to 45%), leading to a 30% increase in task success while reducing average response length by over 20%. Additional analyses confirm robustness to noisy user responses and generalization to out-of-distribution tasks.
VoxSafeBench: Not Just What Is Said, but Who, How, and Where
Apr 16, 2026As speech language models (SLMs) transition from personal devices into shared, multi-user environments, their responses must account for far more than the words alone. Who is speaking, how they sound, and where the conversation takes place can each turn an otherwise benign request into one that is unsafe, unfair, or privacy-violating. Existing benchmarks, however, largely focus on basic audio comprehension, study individual risks in isolation, or conflate content that is inherently harmful with content that only becomes problematic due to its acoustic context. We introduce VoxSafeBench, among the first benchmarks to jointly evaluate social alignment in SLMs across three dimensions: safety, fairness, and privacy. VoxSafeBench adopts a Two-Tier design: Tier1 evaluates content-centric risks using matched text and audio inputs, while Tier2 targets audio-conditioned risks in which the transcript is benign but the appropriate response hinges on the speaker, paralinguistic cues, or the surrounding environment. To validate Tier2, we include intermediate perception probes and confirm that frontier SLMs can successfully detect these acoustic cues yet still fail to act on them appropriately. Across 22 tasks with bilingual coverage, we find that safeguards appearing robust on text often degrade in speech: safety awareness drops for speaker- and scene-conditioned risks, fairness erodes when demographic differences are conveyed vocally, and privacy protections falter when contextual cues arrive acoustically. Together, these results expose a pervasive speech grounding gap: current SLMs frequently recognize the relevant social norm in text but fail to apply it when the decisive cue must be grounded in speech. Code and data are publicly available at: https://amphionteam.github.io/VoxSafeBench_demopage/
Reward Hacking in the Era of Large Models: Mechanisms, Emergent Misalignment, Challenges
Apr 15, 2026Reinforcement Learning from Human Feedback (RLHF) and related alignment paradigms have become central to steering large language models (LLMs) and multimodal large language models (MLLMs) toward human-preferred behaviors. However, these approaches introduce a systemic vulnerability: reward hacking, where models exploit imperfections in learned reward signals to maximize proxy objectives without fulfilling true task intent. As models scale and optimization intensifies, such exploitation manifests as verbosity bias, sycophancy, hallucinated justification, benchmark overfitting, and, in multimodal settings, perception--reasoning decoupling and evaluator manipulation. Recent evidence further suggests that seemingly benign shortcut behaviors can generalize into broader forms of misalignment, including deception and strategic gaming of oversight mechanisms. In this survey, we propose the Proxy Compression Hypothesis (PCH) as a unifying framework for understanding reward hacking. We formalize reward hacking as an emergent consequence of optimizing expressive policies against compressed reward representations of high-dimensional human objectives. Under this view, reward hacking arises from the interaction of objective compression, optimization amplification, and evaluator--policy co-adaptation. This perspective unifies empirical phenomena across RLHF, RLAIF, and RLVR regimes, and explains how local shortcut learning can generalize into broader forms of misalignment, including deception and strategic manipulation of oversight mechanisms. We further organize detection and mitigation strategies according to how they intervene on compression, amplification, or co-adaptation dynamics. By framing reward hacking as a structural instability of proxy-based alignment under scale, we highlight open challenges in scalable oversight, multimodal grounding, and agentic autonomy.
UI-Copilot: Advancing Long-Horizon GUI Automation via Tool-Integrated Policy Optimization
Apr 15, 2026MLLM-based GUI agents have demonstrated strong capabilities in complex user interface interaction tasks. However, long-horizon scenarios remain challenging, as these agents are burdened with tasks beyond their intrinsic capabilities, suffering from memory degradation, progress confusion, and math hallucination. To address these challenges, we present UI-Copilot, a collaborative framework where the GUI agent focuses on task execution while a lightweight copilot provides on-demand assistance for memory retrieval and numerical computation. We introduce memory decoupling to separate persistent observations from transient execution context, and train the policy agent to selectively invoke the copilot as Retriever or Calculator based on task demands. To enable effective tool invocation learning, we propose Tool-Integrated Policy Optimization (TIPO), which separately optimizes tool selection through single-turn prediction and task execution through on-policy multi-turn rollouts. Experimental results show that UI-Copilot-7B achieves state-of-the-art performance on challenging MemGUI-Bench, outperforming strong 7B-scale GUI agents such as GUI-Owl-7B and UI-TARS-1.5-7B. Moreover, UI-Copilot-7B delivers a 17.1% absolute improvement on AndroidWorld over the base Qwen model, highlighting UI-Copilot's strong generalization to real-world GUI tasks.
KnowU-Bench: Towards Interactive, Proactive, and Personalized Mobile Agent Evaluation
Apr 09, 2026Personalized mobile agents that infer user preferences and calibrate proactive assistance hold great promise as everyday digital assistants, yet existing benchmarks fail to capture what this requires. Prior work evaluates preference recovery from static histories or intent prediction from fixed contexts. Neither tests whether an agent can elicit missing preferences through interaction, nor whether it can decide when to intervene, seek consent, or remain silent in a live GUI environment. We introduce KnowU-Bench, an online benchmark for personalized mobile agents built on a reproducible Android emulation environment, covering 42 general GUI tasks, 86 personalized tasks, and 64 proactive tasks. Unlike prior work that treats user preferences as static context, KnowU-Bench hides the user profile from the agent and exposes only behavioral logs, forcing genuine preference inference rather than context lookup. To support multi-turn preference elicitation, it instantiates an LLM-driven user simulator grounded in structured profiles, enabling realistic clarification dialogues and proactive consent handling. Beyond personalization, KnowU-Bench provides comprehensive evaluation of the complete proactive decision chain, including grounded GUI execution, consent negotiation, and post-rejection restraint, evaluated through a hybrid protocol combining rule-based verification with LLM-as-a-Judge scoring. Our experiments reveal a striking degradation: agents that excel at explicit task execution fall below 50% under vague instructions requiring user preference inference or intervention calibration, even for frontier models like Claude Sonnet 4.6. The core bottlenecks are not GUI navigation but preference acquisition and intervention calibration, exposing a fundamental gap between competent interface operation and trustworthy personal assistance.
Towards Fine-Grained and Multi-Granular Contrastive Language-Speech Pre-training
Jan 06, 2026Modeling fine-grained speaking styles remains challenging for language-speech representation pre-training, as existing speech-text models are typically trained with coarse captions or task-specific supervision, and scalable fine-grained style annotations are unavailable. We present FCaps, a large-scale dataset with fine-grained free-text style descriptions, encompassing 47k hours of speech and 19M fine-grained captions annotated via a novel end-to-end pipeline that directly grounds detailed captions in audio, thereby avoiding the error propagation caused by LLM-based rewriting in existing cascaded pipelines. Evaluations using LLM-as-a-judge demonstrate that our annotations surpass existing cascaded annotations in terms of correctness, coverage, and naturalness. Building on FCaps, we propose CLSP, a contrastive language-speech pre-trained model that integrates global and fine-grained supervision, enabling unified representations across multiple granularities. Extensive experiments demonstrate that CLSP learns fine-grained and multi-granular speech-text representations that perform reliably across global and fine-grained speech-text retrieval, zero-shot paralinguistic classification, and speech style similarity scoring, with strong alignment to human judgments. All resources will be made publicly available.
Chain-of-Model Learning for Language Model
May 17, 2025In this paper, we propose a novel learning paradigm, termed Chain-of-Model (CoM), which incorporates the causal relationship into the hidden states of each layer as a chain style, thereby introducing great scaling efficiency in model training and inference flexibility in deployment. We introduce the concept of Chain-of-Representation (CoR), which formulates the hidden states at each layer as a combination of multiple sub-representations (i.e., chains) at the hidden dimension level. In each layer, each chain from the output representations can only view all of its preceding chains in the input representations. Consequently, the model built upon CoM framework can progressively scale up the model size by increasing the chains based on the previous models (i.e., chains), and offer multiple sub-models at varying sizes for elastic inference by using different chain numbers. Based on this principle, we devise Chain-of-Language-Model (CoLM), which incorporates the idea of CoM into each layer of Transformer architecture. Based on CoLM, we further introduce CoLM-Air by introducing a KV sharing mechanism, that computes all keys and values within the first chain and then shares across all chains. This design demonstrates additional extensibility, such as enabling seamless LM switching, prefilling acceleration and so on. Experimental results demonstrate our CoLM family can achieve comparable performance to the standard Transformer, while simultaneously enabling greater flexiblity, such as progressive scaling to improve training efficiency and offer multiple varying model sizes for elastic inference, paving a a new way toward building language models. Our code will be released in the future at: https://github.com/microsoft/CoLM.
Kimi-Audio Technical Report
Apr 25, 2025
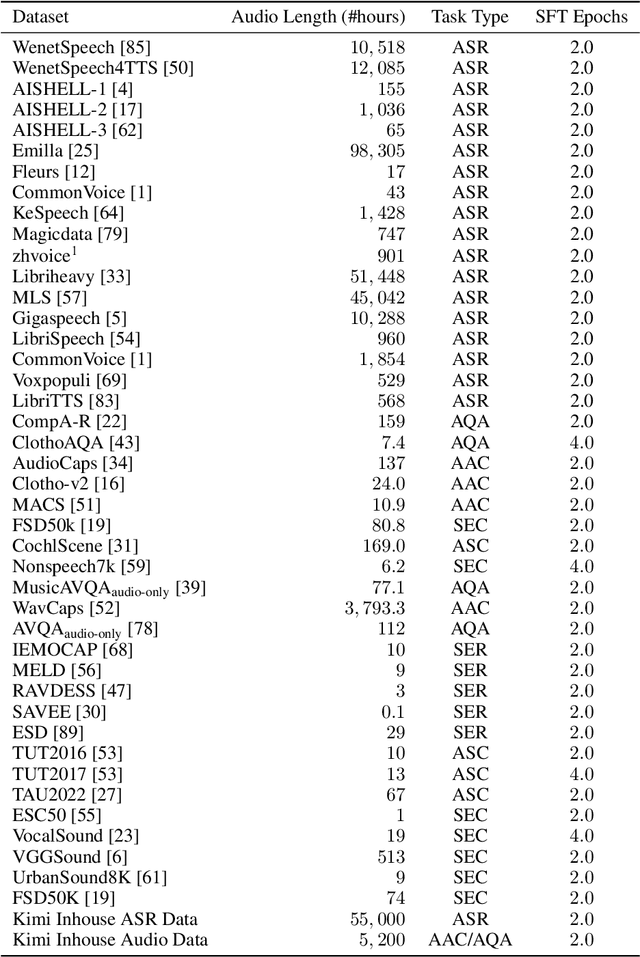
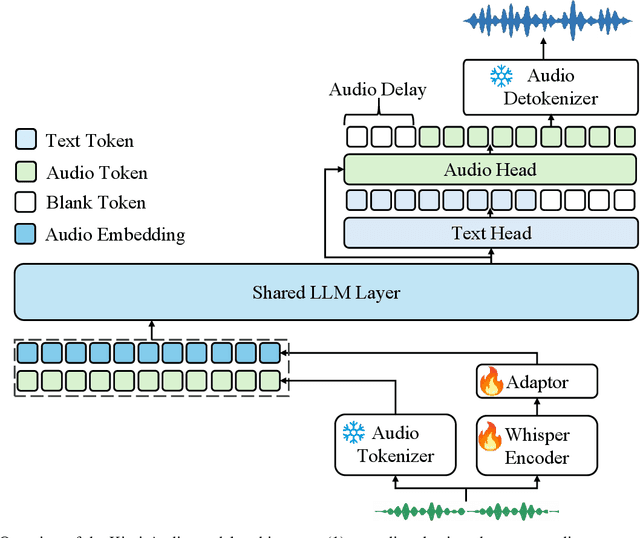
We present Kimi-Audio, an open-source audio foundation model that excels in audio understanding, generation, and conversation. We detail the practices in building Kimi-Audio, including model architecture, data curation, training recipe, inference deployment, and evaluation. Specifically, we leverage a 12.5Hz audio tokenizer, design a novel LLM-based architecture with continuous features as input and discrete tokens as output, and develop a chunk-wise streaming detokenizer based on flow matching. We curate a pre-training dataset that consists of more than 13 million hours of audio data covering a wide range of modalities including speech, sound, and music, and build a pipeline to construct high-quality and diverse post-training data. Initialized from a pre-trained LLM, Kimi-Audio is continual pre-trained on both audio and text data with several carefully designed tasks, and then fine-tuned to support a diverse of audio-related tasks. Extensive evaluation shows that Kimi-Audio achieves state-of-the-art performance on a range of audio benchmarks including speech recognition, audio understanding, audio question answering, and speech conversation. We release the codes, model checkpoints, as well as the evaluation toolkits in https://github.com/MoonshotAI/Kimi-Audio.
MoonCast: High-Quality Zero-Shot Podcast Generation
Mar 19, 2025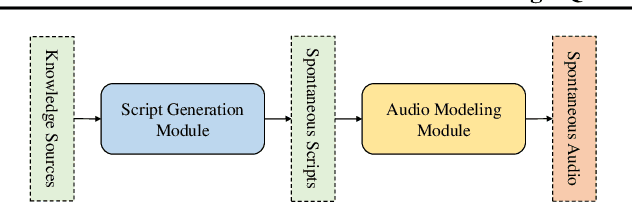



Recent advances in text-to-speech synthesis have achieved notable success in generating high-quality short utterances for individual speakers. However, these systems still face challenges when extending their capabilities to long, multi-speaker, and spontaneous dialogues, typical of real-world scenarios such as podcasts. These limitations arise from two primary challenges: 1) long speech: podcasts typically span several minutes, exceeding the upper limit of most existing work; 2) spontaneity: podcasts are marked by their spontaneous, oral nature, which sharply contrasts with formal, written contexts; existing works often fall short in capturing this spontaneity. In this paper, we propose MoonCast, a solution for high-quality zero-shot podcast generation, aiming to synthesize natural podcast-style speech from text-only sources (e.g., stories, technical reports, news in TXT, PDF, or Web URL formats) using the voices of unseen speakers. To generate long audio, we adopt a long-context language model-based audio modeling approach utilizing large-scale long-context speech data. To enhance spontaneity, we utilize a podcast generation module to generate scripts with spontaneous details, which have been empirically shown to be as crucial as the text-to-speech modeling itself. Experiments demonstrate that MoonCast outperforms baselines, with particularly notable improvements in spontaneity and coherence.