 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVersatile Framework for Song Generation with Prompt-based Control
Apr 29, 2025Song generation focuses on producing controllable high-quality songs based on various prompts. However, existing methods struggle to generate vocals and accompaniments with prompt-based control and proper alignment. Additionally, they fall short in supporting various tasks. To address these challenges, we introduce VersBand, a multi-task song generation framework for synthesizing high-quality, aligned songs with prompt-based control. VersBand comprises these primary models: 1) VocalBand, a decoupled model, leverages the flow-matching method for generating singing styles, pitches, and mel-spectrograms, allowing fast, high-quality vocal generation with style control. 2) AccompBand, a flow-based transformer model, incorporates the Band-MOE, selecting suitable experts for enhanced quality, alignment, and control. This model allows for generating controllable, high-quality accompaniments aligned with vocals. 3) Two generation models, LyricBand for lyrics and MelodyBand for melodies, contribute to the comprehensive multi-task song generation system, allowing for extensive control based on multiple prompts. Experimental results demonstrate that VersBand performs better over baseline models across multiple song generation tasks using objective and subjective metrics. Audio samples are available at https://aaronz345.github.io/VersBandDemo.
Unleashing the Power of Natural Audio Featuring Multiple Sound Sources
Apr 24, 2025Universal sound separation aims to extract clean audio tracks corresponding to distinct events from mixed audio, which is critical for artificial auditory perception. However, current methods heavily rely on artificially mixed audio for training, which limits their ability to generalize to naturally mixed audio collected in real-world environments. To overcome this limitation, we propose ClearSep, an innovative framework that employs a data engine to decompose complex naturally mixed audio into multiple independent tracks, thereby allowing effective sound separation in real-world scenarios. We introduce two remix-based evaluation metrics to quantitatively assess separation quality and use these metrics as thresholds to iteratively apply the data engine alongside model training, progressively optimizing separation performance. In addition, we propose a series of training strategies tailored to these separated independent tracks to make the best use of them. Extensive experiments demonstrate that ClearSep achieves state-of-the-art performance across multiple sound separation tasks, highlighting its potential for advancing sound separation in natural audio scenarios. For more examples and detailed results, please visit our demo page at https://clearsep.github.io.
OmniAudio: Generating Spatial Audio from 360-Degree Video
Apr 21, 2025


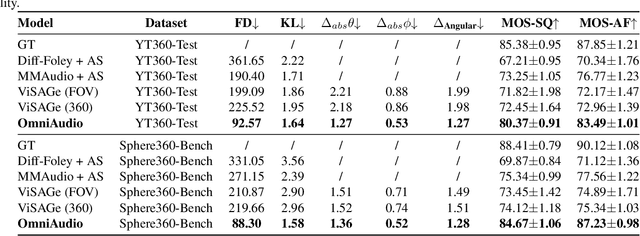
Traditional video-to-audio generation techniques primarily focus on field-of-view (FoV) video and non-spatial audio, often missing the spatial cues necessary for accurately representing sound sources in 3D environments. To address this limitation, we introduce a novel task, 360V2SA, to generate spatial audio from 360-degree videos, specifically producing First-order Ambisonics (FOA) audio - a standard format for representing 3D spatial audio that captures sound directionality and enables realistic 3D audio reproduction. We first create Sphere360, a novel dataset tailored for this task that is curated from real-world data. We also design an efficient semi-automated pipeline for collecting and cleaning paired video-audio data. To generate spatial audio from 360-degree video, we propose a novel framework OmniAudio, which leverages self-supervised pre-training using both spatial audio data (in FOA format) and large-scale non-spatial data. Furthermore, OmniAudio features a dual-branch framework that utilizes both panoramic and FoV video inputs to capture comprehensive local and global information from 360-degree videos. Experimental results demonstrate that OmniAudio achieves state-of-the-art performance across both objective and subjective metrics on Sphere360. Code and datasets will be released at https://github.com/liuhuadai/OmniAudio. The demo page is available at https://OmniAudio-360V2SA.github.io.
OmniChat: Enhancing Spoken Dialogue Systems with Scalable Synthetic Data for Diverse Scenarios
Jan 02, 2025



With the rapid development of large language models, researchers have created increasingly advanced spoken dialogue systems that can naturally converse with humans. However, these systems still struggle to handle the full complexity of real-world conversations, including audio events, musical contexts, and emotional expressions, mainly because current dialogue datasets are constrained in both scale and scenario diversity. In this paper, we propose leveraging synthetic data to enhance the dialogue models across diverse scenarios. We introduce ShareChatX, the first comprehensive, large-scale dataset for spoken dialogue that spans diverse scenarios. Based on this dataset, we introduce OmniChat, a multi-turn dialogue system with a heterogeneous feature fusion module, designed to optimize feature selection in different dialogue contexts. In addition, we explored critical aspects of training dialogue systems using synthetic data. Through comprehensive experimentation, we determined the ideal balance between synthetic and real data, achieving state-of-the-art results on the real-world dialogue dataset DailyTalk. We also highlight the crucial importance of synthetic data in tackling diverse, complex dialogue scenarios, especially those involving audio and music. For more details, please visit our demo page at \url{https://sharechatx.github.io/}.
MoMu-Diffusion: On Learning Long-Term Motion-Music Synchronization and Correspondence
Nov 04, 2024



Motion-to-music and music-to-motion have been studied separately, each attracting substantial research interest within their respective domains. The interaction between human motion and music is a reflection of advanced human intelligence, and establishing a unified relationship between them is particularly important. However, to date, there has been no work that considers them jointly to explore the modality alignment within. To bridge this gap, we propose a novel framework, termed MoMu-Diffusion, for long-term and synchronous motion-music generation. Firstly, to mitigate the huge computational costs raised by long sequences, we propose a novel Bidirectional Contrastive Rhythmic Variational Auto-Encoder (BiCoR-VAE) that extracts the modality-aligned latent representations for both motion and music inputs. Subsequently, leveraging the aligned latent spaces, we introduce a multi-modal Transformer-based diffusion model and a cross-guidance sampling strategy to enable various generation tasks, including cross-modal, multi-modal, and variable-length generation. Extensive experiments demonstrate that MoMu-Diffusion surpasses recent state-of-the-art methods both qualitatively and quantitatively, and can synthesize realistic, diverse, long-term, and beat-matched music or motion sequences. The generated samples and codes are available at https://momu-diffusion.github.io/
OmniSep: Unified Omni-Modality Sound Separation with Query-Mixup
Oct 28, 2024



The scaling up has brought tremendous success in the fields of vision and language in recent years. When it comes to audio, however, researchers encounter a major challenge in scaling up the training data, as most natural audio contains diverse interfering signals. To address this limitation, we introduce Omni-modal Sound Separation (OmniSep), a novel framework capable of isolating clean soundtracks based on omni-modal queries, encompassing both single-modal and multi-modal composed queries. Specifically, we introduce the Query-Mixup strategy, which blends query features from different modalities during training. This enables OmniSep to optimize multiple modalities concurrently, effectively bringing all modalities under a unified framework for sound separation. We further enhance this flexibility by allowing queries to influence sound separation positively or negatively, facilitating the retention or removal of specific sounds as desired. Finally, OmniSep employs a retrieval-augmented approach known as Query-Aug, which enables open-vocabulary sound separation. Experimental evaluations on MUSIC, VGGSOUND-CLEAN+, and MUSIC-CLEAN+ datasets demonstrate effectiveness of OmniSep, achieving state-of-the-art performance in text-, image-, and audio-queried sound separation tasks. For samples and further information, please visit the demo page at \url{https://omnisep.github.io/}.
FlashAudio: Rectified Flows for Fast and High-Fidelity Text-to-Audio Generation
Oct 16, 2024



Recent advancements in latent diffusion models (LDMs) have markedly enhanced text-to-audio generation, yet their iterative sampling processes impose substantial computational demands, limiting practical deployment. While recent methods utilizing consistency-based distillation aim to achieve few-step or single-step inference, their one-step performance is constrained by curved trajectories, preventing them from surpassing traditional diffusion models. In this work, we introduce FlashAudio with rectified flows to learn straight flow for fast simulation. To alleviate the inefficient timesteps allocation and suboptimal distribution of noise, FlashAudio optimizes the time distribution of rectified flow with Bifocal Samplers and proposes immiscible flow to minimize the total distance of data-noise pairs in a batch vias assignment. Furthermore, to address the amplified accumulation error caused by the classifier-free guidance (CFG), we propose Anchored Optimization, which refines the guidance scale by anchoring it to a reference trajectory. Experimental results on text-to-audio generation demonstrate that FlashAudio's one-step generation performance surpasses the diffusion-based models with hundreds of sampling steps on audio quality and enables a sampling speed of 400x faster than real-time on a single NVIDIA 4090Ti GPU.
MimicTalk: Mimicking a personalized and expressive 3D talking face in minutes
Oct 09, 2024



Talking face generation (TFG) aims to animate a target identity's face to create realistic talking videos. Personalized TFG is a variant that emphasizes the perceptual identity similarity of the synthesized result (from the perspective of appearance and talking style). While previous works typically solve this problem by learning an individual neural radiance field (NeRF) for each identity to implicitly store its static and dynamic information, we find it inefficient and non-generalized due to the per-identity-per-training framework and the limited training data. To this end, we propose MimicTalk, the first attempt that exploits the rich knowledge from a NeRF-based person-agnostic generic model for improving the efficiency and robustness of personalized TFG. To be specific, (1) we first come up with a person-agnostic 3D TFG model as the base model and propose to adapt it into a specific identity; (2) we propose a static-dynamic-hybrid adaptation pipeline to help the model learn the personalized static appearance and facial dynamic features; (3) To generate the facial motion of the personalized talking style, we propose an in-context stylized audio-to-motion model that mimics the implicit talking style provided in the reference video without information loss by an explicit style representation. The adaptation process to an unseen identity can be performed in 15 minutes, which is 47 times faster than previous person-dependent methods. Experiments show that our MimicTalk surpasses previous baselines regarding video quality, efficiency, and expressiveness. Source code and video samples are available at https://mimictalk.github.io .
TCSinger: Zero-Shot Singing Voice Synthesis with Style Transfer and Multi-Level Style Control
Sep 26, 2024



Zero-shot singing voice synthesis (SVS) with style transfer and style control aims to generate high-quality singing voices with unseen timbres and styles (including singing method, emotion, rhythm, technique, and pronunciation) from audio and text prompts. However, the multifaceted nature of singing styles poses a significant challenge for effective modeling, transfer, and control. Furthermore, current SVS models often fail to generate singing voices rich in stylistic nuances for unseen singers. To address these challenges, we introduce TCSinger, the first zero-shot SVS model for style transfer across cross-lingual speech and singing styles, along with multi-level style control. Specifically, TCSinger proposes three primary modules: 1) the clustering style encoder employs a clustering vector quantization model to stably condense style information into a compact latent space; 2) the Style and Duration Language Model (S\&D-LM) concurrently predicts style information and phoneme duration, which benefits both; 3) the style adaptive decoder uses a novel mel-style adaptive normalization method to generate singing voices with enhanced details. Experimental results show that TCSinger outperforms all baseline models in synthesis quality, singer similarity, and style controllability across various tasks, including zero-shot style transfer, multi-level style control, cross-lingual style transfer, and speech-to-singing style transfer. Singing voice samples can be accessed at https://tcsinger.github.io/.
WavTokenizer: an Efficient Acoustic Discrete Codec Tokenizer for Audio Language Modeling
Aug 29, 2024



Language models have been effectively applied to modeling natural signals, such as images, video, speech, and audio. A crucial component of these models is the codec tokenizer, which compresses high-dimensional natural signals into lower-dimensional discrete tokens. In this paper, we introduce WavTokenizer, which offers several advantages over previous SOTA acoustic codec models in the audio domain: 1)extreme compression. By compressing the layers of quantizers and the temporal dimension of the discrete codec, one-second audio of 24kHz sampling rate requires only a single quantizer with 40 or 75 tokens. 2)improved subjective quality. Despite the reduced number of tokens, WavTokenizer achieves state-of-the-art reconstruction quality with outstanding UTMOS scores and inherently contains richer semantic information. Specifically, we achieve these results by designing a broader VQ space, extended contextual windows, and improved attention networks, as well as introducing a powerful multi-scale discriminator and an inverse Fourier transform structure. We conducted extensive reconstruction experiments in the domains of speech, audio, and music. WavTokenizer exhibited strong performance across various objective and subjective metrics compared to state-of-the-art models. We also tested semantic information, VQ utilization, and adaptability to generative models. Comprehensive ablation studies confirm the necessity of each module in WavTokenizer. The related code, demos, and pre-trained models are available at https://github.com/jishengpeng/WavTokenizer.