 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Your Driving World Model an All-Around Player?
May 11, 2026Today's driving world models can generate remarkably realistic dash-cam videos, yet no single model excels universally. Some generate photorealistic textures but violate basic physics; others maintain geometric consistency but fail when subjected to closed-loop planning. This disconnect exposes a critical gap: the field evaluates how real generated worlds appear, but rarely whether they behave realistically. We introduce WorldLens, a unified benchmark that measures world-model fidelity across the full spectrum, from pixel quality and 4D geometry to closed-loop driving and human perceptual alignment, through five complementary aspects and 24 standardized dimensions. Our evaluation of six representative models reveals that no existing approach dominates across all axes: texture-rich models violate geometry, geometry-aware models lack behavioral fidelity, and even the strongest performers achieve only 2-3 out of 10 on human realism ratings. To bridge algorithmic metrics with human perception, we further contribute WorldLens-26K, a 26,808-entry human-annotated preference dataset pairing numerical scores with textual rationales, and WorldLens-Agent, a vision-language evaluator distilled from these judgments that enables scalable, explainable auto-assessment. Together, the benchmark, dataset, and agent form a unified ecosystem for assessing generated worlds not merely by visual appeal, but by physical and behavioral fidelity.
Is Nano Banana Pro a Low-Level Vision All-Rounder? A Comprehensive Evaluation on 14 Tasks and 40 Datasets
Dec 19, 2025The rapid evolution of text-to-image generation models has revolutionized visual content creation. While commercial products like Nano Banana Pro have garnered significant attention, their potential as generalist solvers for traditional low-level vision challenges remains largely underexplored. In this study, we investigate the critical question: Is Nano Banana Pro a Low-Level Vision All-Rounder? We conducted a comprehensive zero-shot evaluation across 14 distinct low-level tasks spanning 40 diverse datasets. By utilizing simple textual prompts without fine-tuning, we benchmarked Nano Banana Pro against state-of-the-art specialist models. Our extensive analysis reveals a distinct performance dichotomy: while \textbf{Nano Banana Pro demonstrates superior subjective visual quality}, often hallucinating plausible high-frequency details that surpass specialist models, it lags behind in traditional reference-based quantitative metrics. We attribute this discrepancy to the inherent stochasticity of generative models, which struggle to maintain the strict pixel-level consistency required by conventional metrics. This report identifies Nano Banana Pro as a capable zero-shot contender for low-level vision tasks, while highlighting that achieving the high fidelity of domain specialists remains a significant hurdle.
WorldLens: Full-Spectrum Evaluations of Driving World Models in Real World
Dec 11, 2025Generative world models are reshaping embodied AI, enabling agents to synthesize realistic 4D driving environments that look convincing but often fail physically or behaviorally. Despite rapid progress, the field still lacks a unified way to assess whether generated worlds preserve geometry, obey physics, or support reliable control. We introduce WorldLens, a full-spectrum benchmark evaluating how well a model builds, understands, and behaves within its generated world. It spans five aspects -- Generation, Reconstruction, Action-Following, Downstream Task, and Human Preference -- jointly covering visual realism, geometric consistency, physical plausibility, and functional reliability. Across these dimensions, no existing world model excels universally: those with strong textures often violate physics, while geometry-stable ones lack behavioral fidelity. To align objective metrics with human judgment, we further construct WorldLens-26K, a large-scale dataset of human-annotated videos with numerical scores and textual rationales, and develop WorldLens-Agent, an evaluation model distilled from these annotations to enable scalable, explainable scoring. Together, the benchmark, dataset, and agent form a unified ecosystem for measuring world fidelity -- standardizing how future models are judged not only by how real they look, but by how real they behave.
Learning to Tell Apart: Weakly Supervised Video Anomaly Detection via Disentangled Semantic Alignment
Nov 13, 2025Recent advancements in weakly-supervised video anomaly detection have achieved remarkable performance by applying the multiple instance learning paradigm based on multimodal foundation models such as CLIP to highlight anomalous instances and classify categories. However, their objectives may tend to detect the most salient response segments, while neglecting to mine diverse normal patterns separated from anomalies, and are prone to category confusion due to similar appearance, leading to unsatisfactory fine-grained classification results. Therefore, we propose a novel Disentangled Semantic Alignment Network (DSANet) to explicitly separate abnormal and normal features from coarse-grained and fine-grained aspects, enhancing the distinguishability. Specifically, at the coarse-grained level, we introduce a self-guided normality modeling branch that reconstructs input video features under the guidance of learned normal prototypes, encouraging the model to exploit normality cues inherent in the video, thereby improving the temporal separation of normal patterns and anomalous events. At the fine-grained level, we present a decoupled contrastive semantic alignment mechanism, which first temporally decomposes each video into event-centric and background-centric components using frame-level anomaly scores and then applies visual-language contrastive learning to enhance class-discriminative representations. Comprehensive experiments on two standard benchmarks, namely XD-Violence and UCF-Crime, demonstrate that DSANet outperforms existing state-of-the-art methods.
VideoLucy: Deep Memory Backtracking for Long Video Understanding
Oct 14, 2025



Recent studies have shown that agent-based systems leveraging large language models (LLMs) for key information retrieval and integration have emerged as a promising approach for long video understanding. However, these systems face two major challenges. First, they typically perform modeling and reasoning on individual frames, struggling to capture the temporal context of consecutive frames. Second, to reduce the cost of dense frame-level captioning, they adopt sparse frame sampling, which risks discarding crucial information. To overcome these limitations, we propose VideoLucy, a deep memory backtracking framework for long video understanding. Inspired by the human recollection process from coarse to fine, VideoLucy employs a hierarchical memory structure with progressive granularity. This structure explicitly defines the detail level and temporal scope of memory at different hierarchical depths. Through an agent-based iterative backtracking mechanism, VideoLucy systematically mines video-wide, question-relevant deep memories until sufficient information is gathered to provide a confident answer. This design enables effective temporal understanding of consecutive frames while preserving critical details. In addition, we introduce EgoMem, a new benchmark for long video understanding. EgoMem is designed to comprehensively evaluate a model's ability to understand complex events that unfold over time and capture fine-grained details in extremely long videos. Extensive experiments demonstrate the superiority of VideoLucy. Built on open-source models, VideoLucy significantly outperforms state-of-the-art methods on multiple long video understanding benchmarks, achieving performance even surpassing the latest proprietary models such as GPT-4o. Our code and dataset will be made publicly at https://videolucy.github.io
ReID5o: Achieving Omni Multi-modal Person Re-identification in a Single Model
Jun 11, 2025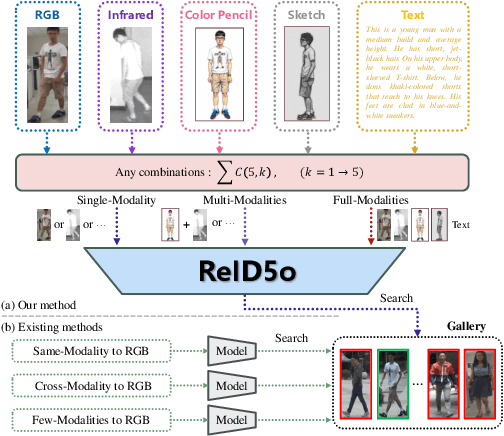
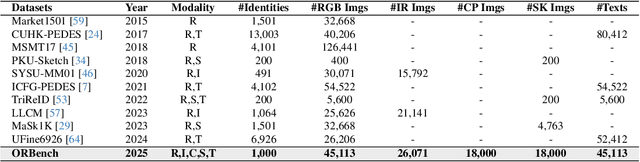
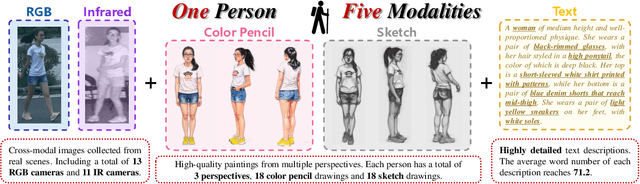
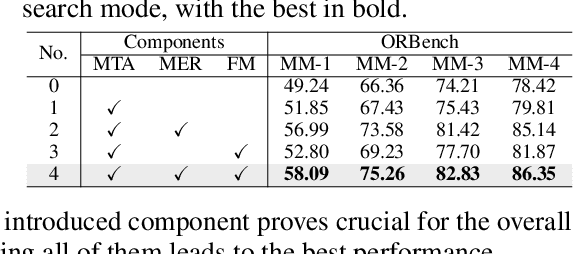
In real-word scenarios, person re-identification (ReID) expects to identify a person-of-interest via the descriptive query, regardless of whether the query is a single modality or a combination of multiple modalities. However, existing methods and datasets remain constrained to limited modalities, failing to meet this requirement. Therefore, we investigate a new challenging problem called Omni Multi-modal Person Re-identification (OM-ReID), which aims to achieve effective retrieval with varying multi-modal queries. To address dataset scarcity, we construct ORBench, the first high-quality multi-modal dataset comprising 1,000 unique identities across five modalities: RGB, infrared, color pencil, sketch, and textual description. This dataset also has significant superiority in terms of diversity, such as the painting perspectives and textual information. It could serve as an ideal platform for follow-up investigations in OM-ReID. Moreover, we propose ReID5o, a novel multi-modal learning framework for person ReID. It enables synergistic fusion and cross-modal alignment of arbitrary modality combinations in a single model, with a unified encoding and multi-expert routing mechanism proposed. Extensive experiments verify the advancement and practicality of our ORBench. A wide range of possible models have been evaluated and compared on it, and our proposed ReID5o model gives the best performance. The dataset and code will be made publicly available at https://github.com/Zplusdragon/ReID5o_ORBench.
Speech Token Prediction via Compressed-to-fine Language Modeling for Speech Generation
May 30, 2025Neural audio codecs, used as speech tokenizers, have demonstrated remarkable potential in the field of speech generation. However, to ensure high-fidelity audio reconstruction, neural audio codecs typically encode audio into long sequences of speech tokens, posing a significant challenge for downstream language models in long-context modeling. We observe that speech token sequences exhibit short-range dependency: due to the monotonic alignment between text and speech in text-to-speech (TTS) tasks, the prediction of the current token primarily relies on its local context, while long-range tokens contribute less to the current token prediction and often contain redundant information. Inspired by this observation, we propose a \textbf{compressed-to-fine language modeling} approach to address the challenge of long sequence speech tokens within neural codec language models: (1) \textbf{Fine-grained Initial and Short-range Information}: Our approach retains the prompt and local tokens during prediction to ensure text alignment and the integrity of paralinguistic information; (2) \textbf{Compressed Long-range Context}: Our approach compresses long-range token spans into compact representations to reduce redundant information while preserving essential semantics. Extensive experiments on various neural audio codecs and downstream language models validate the effectiveness and generalizability of the proposed approach, highlighting the importance of token compression in improving speech generation within neural codec language models. The demo of audio samples will be available at https://anonymous.4open.science/r/SpeechTokenPredictionViaCompressedToFinedLM.
WavReward: Spoken Dialogue Models With Generalist Reward Evaluators
May 14, 2025End-to-end spoken dialogue models such as GPT-4o-audio have recently garnered significant attention in the speech domain. However, the evaluation of spoken dialogue models' conversational performance has largely been overlooked. This is primarily due to the intelligent chatbots convey a wealth of non-textual information which cannot be easily measured using text-based language models like ChatGPT. To address this gap, we propose WavReward, a reward feedback model based on audio language models that can evaluate both the IQ and EQ of spoken dialogue systems with speech input. Specifically, 1) based on audio language models, WavReward incorporates the deep reasoning process and the nonlinear reward mechanism for post-training. By utilizing multi-sample feedback via the reinforcement learning algorithm, we construct a specialized evaluator tailored to spoken dialogue models. 2) We introduce ChatReward-30K, a preference dataset used to train WavReward. ChatReward-30K includes both comprehension and generation aspects of spoken dialogue models. These scenarios span various tasks, such as text-based chats, nine acoustic attributes of instruction chats, and implicit chats. WavReward outperforms previous state-of-the-art evaluation models across multiple spoken dialogue scenarios, achieving a substantial improvement about Qwen2.5-Omni in objective accuracy from 55.1$\%$ to 91.5$\%$. In subjective A/B testing, WavReward also leads by a margin of 83$\%$. Comprehensive ablation studies confirm the necessity of each component of WavReward. All data and code will be publicly at https://github.com/jishengpeng/WavReward after the paper is accepted.
Sparse Alignment Enhanced Latent Diffusion Transformer for Zero-Shot Speech Synthesis
Feb 26, 2025



While recent zero-shot text-to-speech (TTS) models have significantly improved speech quality and expressiveness, mainstream systems still suffer from issues related to speech-text alignment modeling: 1) models without explicit speech-text alignment modeling exhibit less robustness, especially for hard sentences in practical applications; 2) predefined alignment-based models suffer from naturalness constraints of forced alignments. This paper introduces \textit{S-DiT}, a TTS system featuring an innovative sparse alignment algorithm that guides the latent diffusion transformer (DiT). Specifically, we provide sparse alignment boundaries to S-DiT to reduce the difficulty of alignment learning without limiting the search space, thereby achieving high naturalness. Moreover, we employ a multi-condition classifier-free guidance strategy for accent intensity adjustment and adopt the piecewise rectified flow technique to accelerate the generation process. Experiments demonstrate that S-DiT achieves state-of-the-art zero-shot TTS speech quality and supports highly flexible control over accent intensity. Notably, our system can generate high-quality one-minute speech with only 8 sampling steps. Audio samples are available at https://sditdemo.github.io/sditdemo/.
Enhancing Expressive Voice Conversion with Discrete Pitch-Conditioned Flow Matching Model
Feb 08, 2025



This paper introduces PFlow-VC, a conditional flow matching voice conversion model that leverages fine-grained discrete pitch tokens and target speaker prompt information for expressive voice conversion (VC). Previous VC works primarily focus on speaker conversion, with further exploration needed in enhancing expressiveness (such as prosody and emotion) for timbre conversion. Unlike previous methods, we adopt a simple and efficient approach to enhance the style expressiveness of voice conversion models. Specifically, we pretrain a self-supervised pitch VQVAE model to discretize speaker-irrelevant pitch information and leverage a masked pitch-conditioned flow matching model for Mel-spectrogram synthesis, which provides in-context pitch modeling capabilities for the speaker conversion model, effectively improving the voice style transfer capacity. Additionally, we improve timbre similarity by combining global timbre embeddings with time-varying timbre tokens. Experiments on unseen LibriTTS test-clean and emotional speech dataset ESD show the superiority of the PFlow-VC model in both timbre conversion and style transfer. Audio samples are available on the demo page https://speechai-demo.github.io/PFlow-VC/.