 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV-FAT: Benchmarking Visual Fidelity Against Text-bias
Jan 08, 2026Recent advancements in Multimodal Large Language Models (MLLMs) have demonstrated impressive performance on standard visual reasoning benchmarks. However, there is growing concern that these models rely excessively on linguistic shortcuts rather than genuine visual grounding, a phenomenon we term Text Bias. In this paper, we investigate the fundamental tension between visual perception and linguistic priors. We decouple the sources of this bias into two dimensions: Internal Corpus Bias, stemming from statistical correlations in pretraining, and External Instruction Bias, arising from the alignment-induced tendency toward sycophancy. To quantify this effect, we introduce V-FAT (Visual Fidelity Against Text-bias), a diagnostic benchmark comprising 4,026 VQA instances across six semantic domains. V-FAT employs a Three-Level Evaluation Framework that systematically increases the conflict between visual evidence and textual information: (L1) internal bias from atypical images, (L2) external bias from misleading instructions, and (L3) synergistic bias where both coincide. We introduce the Visual Robustness Score (VRS), a metric designed to penalize "lucky" linguistic guesses and reward true visual fidelity. Our evaluation of 12 frontier MLLMs reveals that while models excel in existing benchmarks, they experience significant visual collapse under high linguistic dominance.
Kimi-Audio Technical Report
Apr 25, 2025
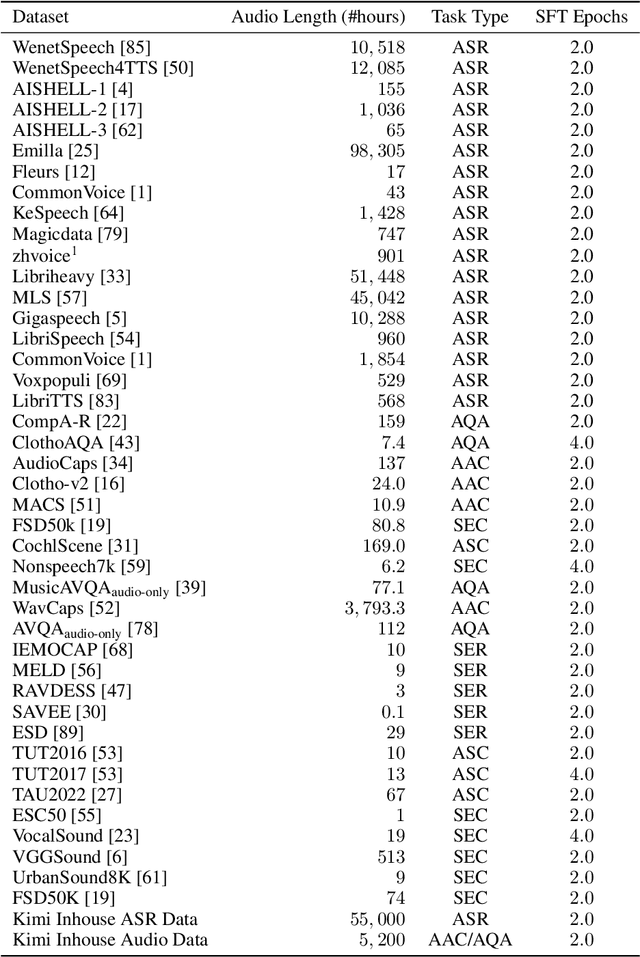
We present Kimi-Audio, an open-source audio foundation model that excels in audio understanding, generation, and conversation. We detail the practices in building Kimi-Audio, including model architecture, data curation, training recipe, inference deployment, and evaluation. Specifically, we leverage a 12.5Hz audio tokenizer, design a novel LLM-based architecture with continuous features as input and discrete tokens as output, and develop a chunk-wise streaming detokenizer based on flow matching. We curate a pre-training dataset that consists of more than 13 million hours of audio data covering a wide range of modalities including speech, sound, and music, and build a pipeline to construct high-quality and diverse post-training data. Initialized from a pre-trained LLM, Kimi-Audio is continual pre-trained on both audio and text data with several carefully designed tasks, and then fine-tuned to support a diverse of audio-related tasks. Extensive evaluation shows that Kimi-Audio achieves state-of-the-art performance on a range of audio benchmarks including speech recognition, audio understanding, audio question answering, and speech conversation. We release the codes, model checkpoints, as well as the evaluation toolkits in https://github.com/MoonshotAI/Kimi-Audio.
Spark-TTS: An Efficient LLM-Based Text-to-Speech Model with Single-Stream Decoupled Speech Tokens
Mar 03, 2025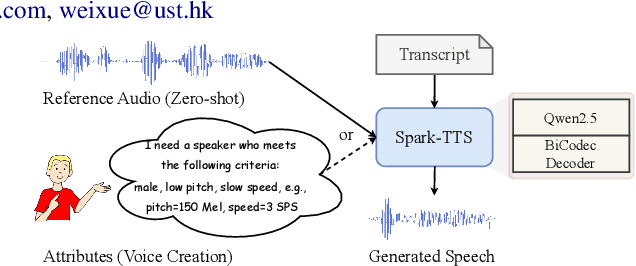



Recent advancements in large language models (LLMs) have driven significant progress in zero-shot text-to-speech (TTS) synthesis. However, existing foundation models rely on multi-stage processing or complex architectures for predicting multiple codebooks, limiting efficiency and integration flexibility. To overcome these challenges, we introduce Spark-TTS, a novel system powered by BiCodec, a single-stream speech codec that decomposes speech into two complementary token types: low-bitrate semantic tokens for linguistic content and fixed-length global tokens for speaker attributes. This disentangled representation, combined with the Qwen2.5 LLM and a chain-of-thought (CoT) generation approach, enables both coarse-grained control (e.g., gender, speaking style) and fine-grained adjustments (e.g., precise pitch values, speaking rate). To facilitate research in controllable TTS, we introduce VoxBox, a meticulously curated 100,000-hour dataset with comprehensive attribute annotations. Extensive experiments demonstrate that Spark-TTS not only achieves state-of-the-art zero-shot voice cloning but also generates highly customizable voices that surpass the limitations of reference-based synthesis. Source code, pre-trained models, and audio samples are available at https://github.com/SparkAudio/Spark-TTS.
Codec-SUPERB @ SLT 2024: A lightweight benchmark for neural audio codec models
Sep 21, 2024



Neural audio codec models are becoming increasingly important as they serve as tokenizers for audio, enabling efficient transmission or facilitating speech language modeling. The ideal neural audio codec should maintain content, paralinguistics, speaker characteristics, and audio information even at low bitrates. Recently, numerous advanced neural codec models have been proposed. However, codec models are often tested under varying experimental conditions. As a result, we introduce the Codec-SUPERB challenge at SLT 2024, designed to facilitate fair and lightweight comparisons among existing codec models and inspire advancements in the field. This challenge brings together representative speech applications and objective metrics, and carefully selects license-free datasets, sampling them into small sets to reduce evaluation computation costs. This paper presents the challenge's rules, datasets, five participant systems, results, and findings.
UniAudio: An Audio Foundation Model Toward Universal Audio Generation
Oct 11, 2023



Large Language models (LLM) have demonstrated the capability to handle a variety of generative tasks. This paper presents the UniAudio system, which, unlike prior task-specific approaches, leverages LLM techniques to generate multiple types of audio (including speech, sounds, music, and singing) with given input conditions. UniAudio 1) first tokenizes all types of target audio along with other condition modalities, 2) concatenates source-target pair as a single sequence, and 3) performs next-token prediction using LLM. Also, a multi-scale Transformer model is proposed to handle the overly long sequences caused by the residual vector quantization based neural codec in tokenization. Training of UniAudio is scaled up to 165K hours of audio and 1B parameters, based on all generative tasks, aiming to obtain sufficient prior knowledge not only in the intrinsic properties of audio but also the inter-relationship between audio and other modalities. Therefore, the trained UniAudio model has the potential to become a foundation model for universal audio generation: it shows strong capability in all trained tasks and can seamlessly support new audio generation tasks after simple fine-tuning. Experiments demonstrate that UniAudio achieves state-of-the-art or at least competitive results on most of the 11 tasks. Demo and code are released at https://github.com/yangdongchao/UniAudio
SnakeGAN: A Universal Vocoder Leveraging DDSP Prior Knowledge and Periodic Inductive Bias
Sep 14, 2023



Generative adversarial network (GAN)-based neural vocoders have been widely used in audio synthesis tasks due to their high generation quality, efficient inference, and small computation footprint. However, it is still challenging to train a universal vocoder which can generalize well to out-of-domain (OOD) scenarios, such as unseen speaking styles, non-speech vocalization, singing, and musical pieces. In this work, we propose SnakeGAN, a GAN-based universal vocoder, which can synthesize high-fidelity audio in various OOD scenarios. SnakeGAN takes a coarse-grained signal generated by a differentiable digital signal processing (DDSP) model as prior knowledge, aiming at recovering high-fidelity waveform from a Mel-spectrogram. We introduce periodic nonlinearities through the Snake activation function and anti-aliased representation into the generator, which further brings the desired inductive bias for audio synthesis and significantly improves the extrapolation capacity for universal vocoding in unseen scenarios. To validate the effectiveness of our proposed method, we train SnakeGAN with only speech data and evaluate its performance for various OOD distributions with both subjective and objective metrics. Experimental results show that SnakeGAN significantly outperforms the compared approaches and can generate high-fidelity audio samples including unseen speakers with unseen styles, singing voices, instrumental pieces, and nonverbal vocalization.
The Singing Voice Conversion Challenge 2023
Jul 06, 2023



We present the latest iteration of the voice conversion challenge (VCC) series, a bi-annual scientific event aiming to compare and understand different voice conversion (VC) systems based on a common dataset. This year we shifted our focus to singing voice conversion (SVC), thus named the challenge the Singing Voice Conversion Challenge (SVCC). A new database was constructed for two tasks, namely in-domain and cross-domain SVC. The challenge was run for two months, and in total we received 26 submissions, including 2 baselines. Through a large-scale crowd-sourced listening test, we observed that for both tasks, although human-level naturalness was achieved by the top system, no team was able to obtain a similarity score as high as the target speakers. Also, as expected, cross-domain SVC is harder than in-domain SVC, especially in the similarity aspect. We also investigated whether existing objective measurements were able to predict perceptual performance, and found that only few of them could reach a significant correlation.
Diverse and Expressive Speech Prosody Prediction with Denoising Diffusion Probabilistic Model
May 26, 2023



Expressive human speech generally abounds with rich and flexible speech prosody variations. The speech prosody predictors in existing expressive speech synthesis methods mostly produce deterministic predictions, which are learned by directly minimizing the norm of prosody prediction error. Its unimodal nature leads to a mismatch with ground truth distribution and harms the model's ability in making diverse predictions. Thus, we propose a novel prosody predictor based on the denoising diffusion probabilistic model to take advantage of its high-quality generative modeling and training stability. Experiment results confirm that the proposed prosody predictor outperforms the deterministic baseline on both the expressiveness and diversity of prediction results with even fewer network parameters.
HiFi-Codec: Group-residual Vector quantization for High Fidelity Audio Codec
May 07, 2023Audio codec models are widely used in audio communication as a crucial technique for compressing audio into discrete representations. Nowadays, audio codec models are increasingly utilized in generation fields as intermediate representations. For instance, AudioLM is an audio generation model that uses the discrete representation of SoundStream as a training target, while VALL-E employs the Encodec model as an intermediate feature to aid TTS tasks. Despite their usefulness, two challenges persist: (1) training these audio codec models can be difficult due to the lack of publicly available training processes and the need for large-scale data and GPUs; (2) achieving good reconstruction performance requires many codebooks, which increases the burden on generation models. In this study, we propose a group-residual vector quantization (GRVQ) technique and use it to develop a novel \textbf{Hi}gh \textbf{Fi}delity Audio Codec model, HiFi-Codec, which only requires 4 codebooks. We train all the models using publicly available TTS data such as LibriTTS, VCTK, AISHELL, and more, with a total duration of over 1000 hours, using 8 GPUs. Our experimental results show that HiFi-Codec outperforms Encodec in terms of reconstruction performance despite requiring only 4 codebooks. To facilitate research in audio codec and generation, we introduce AcademiCodec, the first open-source audio codec toolkit that offers training codes and pre-trained models for Encodec, SoundStream, and HiFi-Codec. Code and pre-trained model can be found on: \href{https://github.com/yangdongchao/AcademiCodec}{https://github.com/yangdongchao/AcademiCodec}
InstructTTS: Modelling Expressive TTS in Discrete Latent Space with Natural Language Style Prompt
Jan 31, 2023



Expressive text-to-speech (TTS) aims to synthesize different speaking style speech according to human's demands. Nowadays, there are two common ways to control speaking styles: (1) Pre-defining a group of speaking style and using categorical index to denote different speaking style. However, there are limitations in the diversity of expressiveness, as these models can only generate the pre-defined styles. (2) Using reference speech as style input, which results in a problem that the extracted style information is not intuitive or interpretable. In this study, we attempt to use natural language as style prompt to control the styles in the synthetic speech, \textit{e.g.}, ``Sigh tone in full of sad mood with some helpless feeling". Considering that there is no existing TTS corpus which is proper to benchmark this novel task, we first construct a speech corpus, whose speech samples are annotated with not only content transcriptions but also style descriptions in natural language. Then we propose an expressive TTS model, named as InstructTTS, which is novel in the sense of following aspects: (1) We fully take the advantage of self-supervised learning and cross-modal metric learning, and propose a novel three-stage training procedure to obtain a robust sentence embedding model, which can effectively capture semantic information from the style prompts and control the speaking style in the generated speech. (2) We propose to model acoustic features in discrete latent space and train a novel discrete diffusion probabilistic model to generate vector-quantized (VQ) acoustic tokens rather than the commonly-used mel spectrogram. (3) We jointly apply mutual information (MI) estimation and minimization during acoustic model training to minimize style-speaker and style-content MI, avoiding possible content and speaker information leakage from the style prompt.