 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMADE: Beyond Scoring via a Multilingual Agentic Diagnosing Engine for Fine-Grained Evaluation Insights
Jun 05, 2026Multilingual and multicultural benchmarks now cover dozens of languages and model families, but the resulting score landscapes remain metric-rich and insight-poor, necessitating fine-grained multilingual post-evaluation diagnosis. However, single LLMs and open-ended agents are easily swamped by the long, noisy diagnostic input, and no reusable taxonomy exists for it. To address this, we propose MADE, a Multilingual Agentic Diagnosing Engine that decomposes post-evaluation analysis into planning, aggregate analysis, instance-level case inspection, multilingual and cultural reflection, and grounded report synthesis. MADE is paired with an expert-led 54-query and 15-language diagnostic set, evaluated on top of a large-scale multilingual evaluation substrate (33 model families, 11 benchmarks, 26 languages, 34 cultures, 8.66M evaluation records). Experiments show that MADE outperforms the strongest shared baseline by 47% in diagnosis report quality and is preferred by human multilingual experts in 87.9% of pairwise comparisons. Applied with multilingual experts, MADE further surfaces four actionable findings on deployment, iteration, and cross-cultural pitfalls, turning benchmark score tables into model-selection and remediation guidance.
The GaoYao Benchmark: A Comprehensive Framework for Evaluating Multilingual and Multicultural Abilities of Large Language Models
Apr 22, 2026Evaluating the multilingual and multicultural capabilities of Large Language Models (LLMs) is essential for their global utility. However, current benchmarks face three critical limitations: (1) fragmented evaluation dimensions that often neglect deep cultural nuances; (2) insufficient language coverage in subjective tasks relying on low-quality machine translation; and (3) shallow analysis that lacks diagnostic depth beyond simple rankings. To address these, we introduce GaoYao, a comprehensive benchmark with 182.3k samples, 26 languages and 51 nations/areas. First, GaoYao proposes a unified framework categorizing evaluation tasks into three cultural layers (General Multilingual, Cross-cultural, Monocultural) and nine cognitive sub-layers. Second, we achieve native-quality expansion by leveraging experts to rigorously localize subjective benchmarks into 19 languages and synthesizing cross-cultural test sets for 34 cultures, surpassing prior coverage by up to 111%. Third, we conduct an in-depth diagnostic analysis on 20+ flagship and compact LLMs. Our findings reveal significant geographical performance disparities and distinct gaps between tasks, offering a reliable map for future work. We release the benchmark (https://github.com/lunyiliu/GaoYao).
Pangu Ultra MoE: How to Train Your Big MoE on Ascend NPUs
May 07, 2025



Sparse large language models (LLMs) with Mixture of Experts (MoE) and close to a trillion parameters are dominating the realm of most capable language models. However, the massive model scale poses significant challenges for the underlying software and hardware systems. In this paper, we aim to uncover a recipe to harness such scale on Ascend NPUs. The key goals are better usage of the computing resources under the dynamic sparse model structures and materializing the expected performance gain on the actual hardware. To select model configurations suitable for Ascend NPUs without repeatedly running the expensive experiments, we leverage simulation to compare the trade-off of various model hyperparameters. This study led to Pangu Ultra MoE, a sparse LLM with 718 billion parameters, and we conducted experiments on the model to verify the simulation results. On the system side, we dig into Expert Parallelism to optimize the communication between NPU devices to reduce the synchronization overhead. We also optimize the memory efficiency within the devices to further reduce the parameter and activation management overhead. In the end, we achieve an MFU of 30.0% when training Pangu Ultra MoE, with performance comparable to that of DeepSeek R1, on 6K Ascend NPUs, and demonstrate that the Ascend system is capable of harnessing all the training stages of the state-of-the-art language models. Extensive experiments indicate that our recipe can lead to efficient training of large-scale sparse language models with MoE. We also study the behaviors of such models for future reference.
Pangu Ultra: Pushing the Limits of Dense Large Language Models on Ascend NPUs
Apr 10, 2025



We present Pangu Ultra, a Large Language Model (LLM) with 135 billion parameters and dense Transformer modules trained on Ascend Neural Processing Units (NPUs). Although the field of LLM has been witnessing unprecedented advances in pushing the scale and capability of LLM in recent years, training such a large-scale model still involves significant optimization and system challenges. To stabilize the training process, we propose depth-scaled sandwich normalization, which effectively eliminates loss spikes during the training process of deep models. We pre-train our model on 13.2 trillion diverse and high-quality tokens and further enhance its reasoning capabilities during post-training. To perform such large-scale training efficiently, we utilize 8,192 Ascend NPUs with a series of system optimizations. Evaluations on multiple diverse benchmarks indicate that Pangu Ultra significantly advances the state-of-the-art capabilities of dense LLMs such as Llama 405B and Mistral Large 2, and even achieves competitive results with DeepSeek-R1, whose sparse model structure contains much more parameters. Our exploration demonstrates that Ascend NPUs are capable of efficiently and effectively training dense models with more than 100 billion parameters. Our model and system will be available for our commercial customers.
SA-WavLM: Speaker-Aware Self-Supervised Pre-training for Mixture Speech
Jul 03, 2024


It was shown that pre-trained models with self-supervised learning (SSL) techniques are effective in various downstream speech tasks. However, most such models are trained on single-speaker speech data, limiting their effectiveness in mixture speech. This motivates us to explore pre-training on mixture speech. This work presents SA-WavLM, a novel pre-trained model for mixture speech. Specifically, SA-WavLM follows an "extract-merge-predict" pipeline in which the representations of each speaker in the input mixture are first extracted individually and then merged before the final prediction. In this pipeline, SA-WavLM performs speaker-informed extractions with the consideration of the interactions between different speakers. Furthermore, a speaker shuffling strategy is proposed to enhance the robustness towards the speaker absence. Experiments show that SA-WavLM either matches or improves upon the state-of-the-art pre-trained models.
Music-PAW: Learning Music Representations via Hierarchical Part-whole Interaction and Contrast
Dec 11, 2023The excellent performance of recent self-supervised learning methods on various downstream tasks has attracted great attention from academia and industry. Some recent research efforts have been devoted to self-supervised music representation learning. Nevertheless, most of them learn to represent equally-sized music clips in the waveform or a spectrogram. Despite being effective in some tasks, learning music representations in such a manner largely neglect the inherent part-whole hierarchies of music. Due to the hierarchical nature of the auditory cortex [24], understanding the bottom-up structure of music, i.e., how different parts constitute the whole at different levels, is essential for music understanding and representation learning. This work pursues hierarchical music representation learning and introduces the Music-PAW framework, which enables feature interactions of cropped music clips with part-whole hierarchies. From a technical perspective, we propose a transformer-based part-whole interaction module to progressively reason the structural relationships between part-whole music clips at adjacent levels. Besides, to create a multi-hierarchy representation space, we devise a hierarchical contrastive learning objective to align part-whole music representations in adjacent hierarchies. The merits of audio representation learning from part-whole hierarchies have been validated on various downstream tasks, including music classification (single-label and multi-label), cover song identification and acoustic scene classification.
Prompt-driven Target Speech Diarization
Oct 23, 2023We introduce a novel task named `target speech diarization', which seeks to determine `when target event occurred' within an audio signal. We devise a neural architecture called Prompt-driven Target Speech Diarization (PTSD), that works with diverse prompts that specify the target speech events of interest. We train and evaluate PTSD using sim2spk, sim3spk and sim4spk datasets, which are derived from the Librispeech. We show that the proposed framework accurately localizes target speech events. Furthermore, our framework exhibits versatility through its impressive performance in three diarization-related tasks: target speaker voice activity detection, overlapped speech detection and gender diarization. In particular, PTSD achieves comparable performance to specialized models across these tasks on both real and simulated data. This work serves as a reference benchmark and provides valuable insights into prompt-driven target speech processing.
USED: Universal Speaker Extraction and Diarization
Sep 19, 2023



Speaker extraction and diarization are two crucial enabling techniques for speech applications. Speaker extraction aims to extract a target speaker's voice from a multi-talk mixture, while speaker diarization demarcates speech segments by speaker, identifying `who spoke when'. The previous studies have typically treated the two tasks independently. However, the two tasks share a similar objective, that is to disentangle the speakers in the spectral domain for the former but in the temporal domain for the latter. It is logical to believe that the speaker turns obtained from speaker diarization can benefit speaker extraction, while the extracted speech offers more accurate speaker turns than the mixture speech. In this paper, we propose a unified framework called Universal Speaker Extraction and Diarization (USED). We extend the existing speaker extraction model to simultaneously extract the waveforms of all speakers. We also employ a scenario-aware differentiated loss function to address the problem of sparsely overlapped speech in real-world conversations. We show that the USED model significantly outperforms the baselines for both speaker extraction and diarization tasks, in both highly overlapped and sparsely overlapped scenarios. Audio samples are available at https://ajyy.github.io/demo/USED/.
DisCover: Disentangled Music Representation Learning for Cover Song Identification
Jul 19, 2023



In the field of music information retrieval (MIR), cover song identification (CSI) is a challenging task that aims to identify cover versions of a query song from a massive collection. Existing works still suffer from high intra-song variances and inter-song correlations, due to the entangled nature of version-specific and version-invariant factors in their modeling. In this work, we set the goal of disentangling version-specific and version-invariant factors, which could make it easier for the model to learn invariant music representations for unseen query songs. We analyze the CSI task in a disentanglement view with the causal graph technique, and identify the intra-version and inter-version effects biasing the invariant learning. To block these effects, we propose the disentangled music representation learning framework (DisCover) for CSI. DisCover consists of two critical components: (1) Knowledge-guided Disentanglement Module (KDM) and (2) Gradient-based Adversarial Disentanglement Module (GADM), which block intra-version and inter-version biased effects, respectively. KDM minimizes the mutual information between the learned representations and version-variant factors that are identified with prior domain knowledge. GADM identifies version-variant factors by simulating the representation transitions between intra-song versions, and exploits adversarial distillation for effect blocking. Extensive comparisons with best-performing methods and in-depth analysis demonstrate the effectiveness of DisCover and the and necessity of disentanglement for CSI.
CorrectSpeech: A Fully Automated System for Speech Correction and Accent Reduction
Apr 12, 2022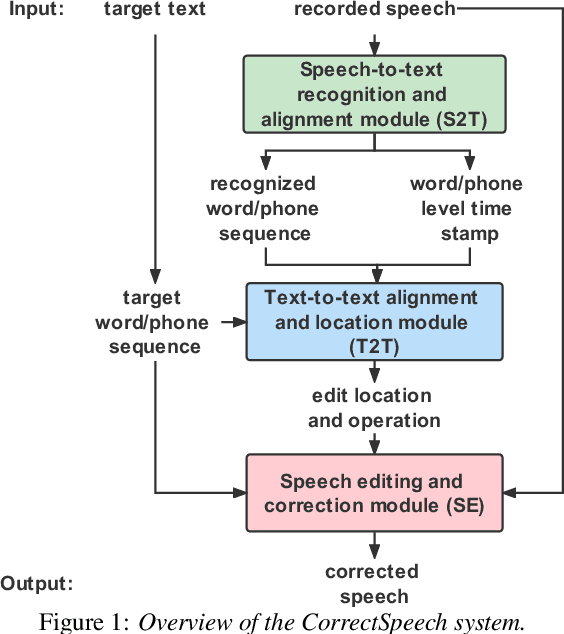
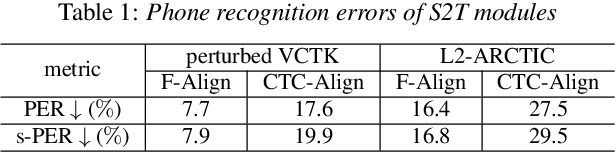
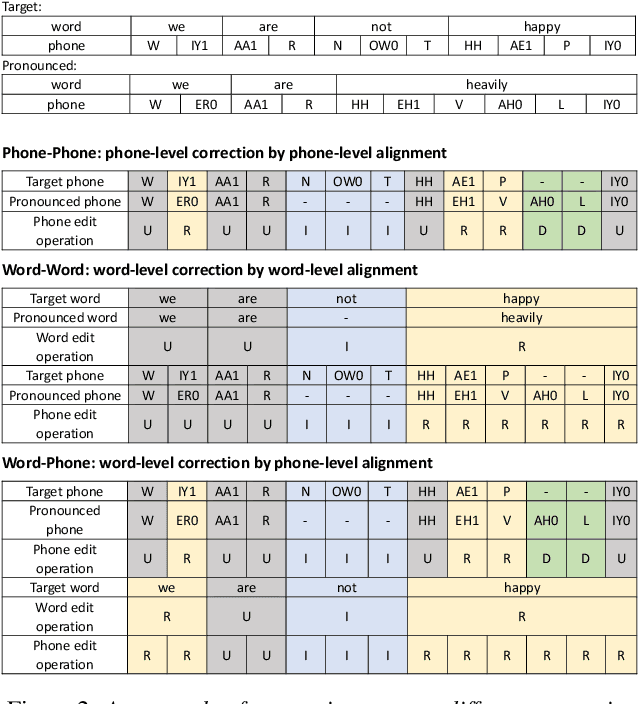
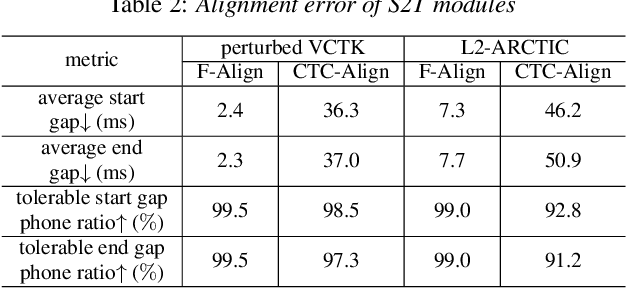
This study extends our previous work on text-based speech editing to developing a fully automated system for speech correction and accent reduction. Consider the application scenario that a recorded speech audio contains certain errors, e.g., inappropriate words, mispronunciations, that need to be corrected. The proposed system, named CorrectSpeech, performs the correction in three steps: recognizing the recorded speech and converting it into time-stamped symbol sequence, aligning recognized symbol sequence with target text to determine locations and types of required edit operations, and generating the corrected speech. Experiments show that the quality and naturalness of corrected speech depend on the performance of speech recognition and alignment modules, as well as the granularity level of editing operations. The proposed system is evaluated on two corpora: a manually perturbed version of VCTK and L2-ARCTIC. The results demonstrate that our system is able to correct mispronunciation and reduce accent in speech recordings. Audio samples are available online for demonstration https://daxintan-cuhk.github.io/CorrectSpeech/ .