 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaperX: A Unified Framework for Multimodal Academic Presentation Generation with Scholar DAG
Feb 05, 2026Transforming scientific papers into multimodal presentation content is essential for research dissemination but remains labor intensive. Existing automated solutions typically treat each format as an isolated downstream task, leading to redundant processing and semantic inconsistency. We introduce PaperX, a unified framework that models academic presentation generation as a structural transformation and rendering process. Central to our approach is the Scholar DAG, an intermediate representation that decouples the paper's logical structure from its final presentation syntax. By applying adaptive graph traversal strategies, PaperX generates diverse, high quality outputs from a single source. Comprehensive evaluations demonstrate that our framework achieves the state of the art performance in content fidelity and aesthetic quality while significantly improving cost efficiency compared to specialized single task agents.
BridgeV2W: Bridging Video Generation Models to Embodied World Models via Embodiment Masks
Feb 03, 2026Embodied world models have emerged as a promising paradigm in robotics, most of which leverage large-scale Internet videos or pretrained video generation models to enrich visual and motion priors. However, they still face key challenges: a misalignment between coordinate-space actions and pixel-space videos, sensitivity to camera viewpoint, and non-unified architectures across embodiments. To this end, we present BridgeV2W, which converts coordinate-space actions into pixel-aligned embodiment masks rendered from the URDF and camera parameters. These masks are then injected into a pretrained video generation model via a ControlNet-style pathway, which aligns the action control signals with predicted videos, adds view-specific conditioning to accommodate camera viewpoints, and yields a unified world model architecture across embodiments. To mitigate overfitting to static backgrounds, BridgeV2W further introduces a flow-based motion loss that focuses on learning dynamic and task-relevant regions. Experiments on single-arm (DROID) and dual-arm (AgiBot-G1) datasets, covering diverse and challenging conditions with unseen viewpoints and scenes, show that BridgeV2W improves video generation quality compared to prior state-of-the-art methods. We further demonstrate the potential of BridgeV2W on downstream real-world tasks, including policy evaluation and goal-conditioned planning. More results can be found on our project website at https://BridgeV2W.github.io .
ShotFinder: Imagination-Driven Open-Domain Video Shot Retrieval via Web Search
Jan 30, 2026In recent years, large language models (LLMs) have made rapid progress in information retrieval, yet existing research has mainly focused on text or static multimodal settings. Open-domain video shot retrieval, which involves richer temporal structure and more complex semantics, still lacks systematic benchmarks and analysis. To fill this gap, we introduce ShotFinder, a benchmark that formalizes editing requirements as keyframe-oriented shot descriptions and introduces five types of controllable single-factor constraints: Temporal order, Color, Visual style, Audio, and Resolution. We curate 1,210 high-quality samples from YouTube across 20 thematic categories, using large models for generation with human verification. Based on the benchmark, we propose ShotFinder, a text-driven three-stage retrieval and localization pipeline: (1) query expansion via video imagination, (2) candidate video retrieval with a search engine, and (3) description-guided temporal localization. Experiments on multiple closed-source and open-source models reveal a significant gap to human performance, with clear imbalance across constraints: temporal localization is relatively tractable, while color and visual style remain major challenges. These results reveal that open-domain video shot retrieval is still a critical capability that multimodal large models have yet to overcome.
VERM: Leveraging Foundation Models to Create a Virtual Eye for Efficient 3D Robotic Manipulation
Dec 18, 2025When performing 3D manipulation tasks, robots have to execute action planning based on perceptions from multiple fixed cameras. The multi-camera setup introduces substantial redundancy and irrelevant information, which increases computational costs and forces the model to spend extra training time extracting crucial task-relevant details. To filter out redundant information and accurately extract task-relevant features, we propose the VERM (Virtual Eye for Robotic Manipulation) method, leveraging the knowledge in foundation models to imagine a virtual task-adaptive view from the constructed 3D point cloud, which efficiently captures necessary information and mitigates occlusion. To facilitate 3D action planning and fine-grained manipulation, we further design a depth-aware module and a dynamic coarse-to-fine procedure. Extensive experimental results on both simulation benchmark RLBench and real-world evaluations demonstrate the effectiveness of our method, surpassing previous state-of-the-art methods while achieving 1.89x speedup in training time and 1.54x speedup in inference speed. More results can be found on our project website at https://verm-ral.github.io .
DP-CSGP: Differentially Private Stochastic Gradient Push with Compressed Communication
Dec 15, 2025In this paper, we propose a Differentially Private Stochastic Gradient Push with Compressed communication (termed DP-CSGP) for decentralized learning over directed graphs. Different from existing works, the proposed algorithm is designed to maintain high model utility while ensuring both rigorous differential privacy (DP) guarantees and efficient communication. For general non-convex and smooth objective functions, we show that the proposed algorithm achieves a tight utility bound of $\mathcal{O}\left( \sqrt{d\log \left( \frac{1}δ \right)}/(\sqrt{n}Jε) \right)$ ($J$ and $d$ are the number of local samples and the dimension of decision variables, respectively) with $\left(ε, δ\right)$-DP guarantee for each node, matching that of decentralized counterparts with exact communication. Extensive experiments on benchmark tasks show that, under the same privacy budget, DP-CSGP achieves comparable model accuracy with significantly lower communication cost than existing decentralized counterparts with exact communication.
UniBYD: A Unified Framework for Learning Robotic Manipulation Across Embodiments Beyond Imitation of Human Demonstrations
Dec 12, 2025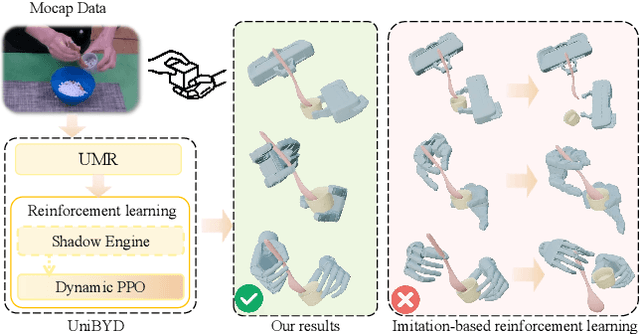
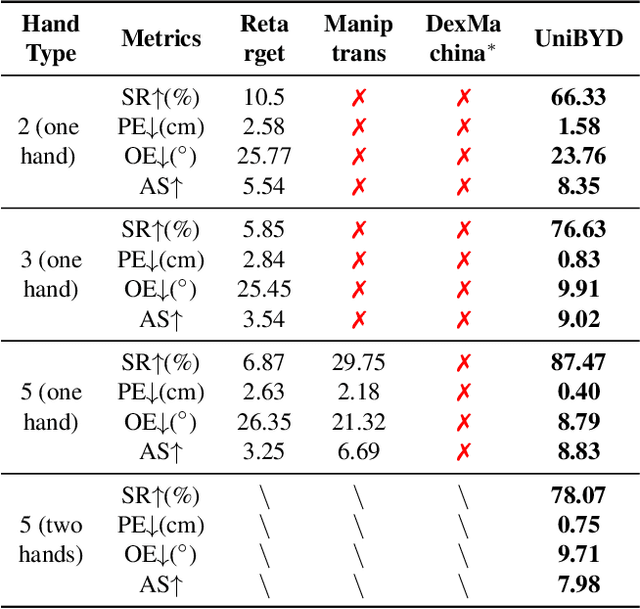
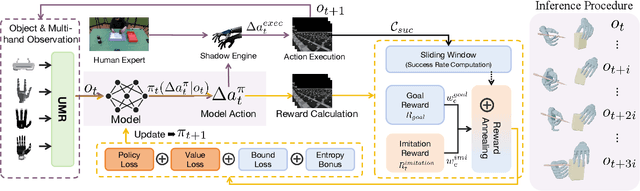
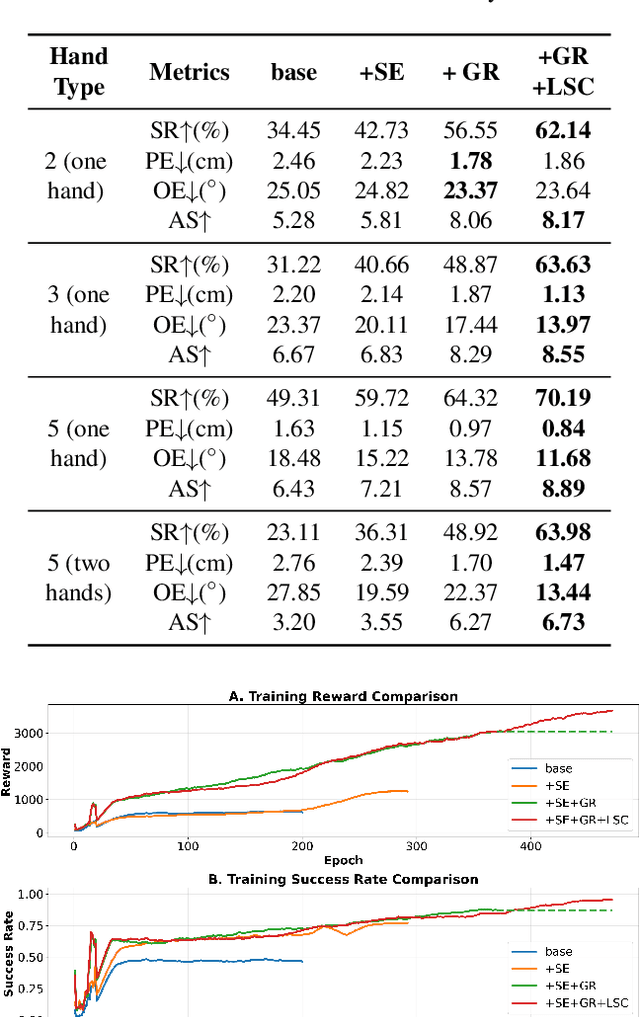
In embodied intelligence, the embodiment gap between robotic and human hands brings significant challenges for learning from human demonstrations. Although some studies have attempted to bridge this gap using reinforcement learning, they remain confined to merely reproducing human manipulation, resulting in limited task performance. In this paper, we propose UniBYD, a unified framework that uses a dynamic reinforcement learning algorithm to discover manipulation policies aligned with the robot's physical characteristics. To enable consistent modeling across diverse robotic hand morphologies, UniBYD incorporates a unified morphological representation (UMR). Building on UMR, we design a dynamic PPO with an annealed reward schedule, enabling reinforcement learning to transition from imitation of human demonstrations to explore policies adapted to diverse robotic morphologies better, thereby going beyond mere imitation of human hands. To address the frequent failures of learning human priors in the early training stage, we design a hybrid Markov-based shadow engine that enables reinforcement learning to imitate human manipulations in a fine-grained manner. To evaluate UniBYD comprehensively, we propose UniManip, the first benchmark encompassing robotic manipulation tasks spanning multiple hand morphologies. Experiments demonstrate a 67.90% improvement in success rate over the current state-of-the-art. Upon acceptance of the paper, we will release our code and benchmark at https://github.com/zhanheng-creator/UniBYD.
Unified Video Editing with Temporal Reasoner
Dec 08, 2025Existing video editing methods face a critical trade-off: expert models offer precision but rely on task-specific priors like masks, hindering unification; conversely, unified temporal in-context learning models are mask-free but lack explicit spatial cues, leading to weak instruction-to-region mapping and imprecise localization. To resolve this conflict, we propose VideoCoF, a novel Chain-of-Frames approach inspired by Chain-of-Thought reasoning. VideoCoF enforces a ``see, reason, then edit" procedure by compelling the video diffusion model to first predict reasoning tokens (edit-region latents) before generating the target video tokens. This explicit reasoning step removes the need for user-provided masks while achieving precise instruction-to-region alignment and fine-grained video editing. Furthermore, we introduce a RoPE alignment strategy that leverages these reasoning tokens to ensure motion alignment and enable length extrapolation beyond the training duration. We demonstrate that with a minimal data cost of only 50k video pairs, VideoCoF achieves state-of-the-art performance on VideoCoF-Bench, validating the efficiency and effectiveness of our approach. Our code, weight, data are available at https://github.com/knightyxp/VideoCoF.
VP-AutoTest: A Virtual-Physical Fusion Autonomous Driving Testing Platform
Dec 08, 2025The rapid development of autonomous vehicles has led to a surge in testing demand. Traditional testing methods, such as virtual simulation, closed-course, and public road testing, face several challenges, including unrealistic vehicle states, limited testing capabilities, and high costs. These issues have prompted increasing interest in virtual-physical fusion testing. However, despite its potential, virtual-physical fusion testing still faces challenges, such as limited element types, narrow testing scope, and fixed evaluation metrics. To address these challenges, we propose the Virtual-Physical Testing Platform for Autonomous Vehicles (VP-AutoTest), which integrates over ten types of virtual and physical elements, including vehicles, pedestrians, and roadside infrastructure, to replicate the diversity of real-world traffic participants. The platform also supports both single-vehicle interaction and multi-vehicle cooperation testing, employing adversarial testing and parallel deduction to accelerate fault detection and explore algorithmic limits, while OBU and Redis communication enable seamless vehicle-to-vehicle (V2V) and vehicle-to-infrastructure (V2I) cooperation across all levels of cooperative automation. Furthermore, VP-AutoTest incorporates a multidimensional evaluation framework and AI-driven expert systems to conduct comprehensive performance assessment and defect diagnosis. Finally, by comparing virtual-physical fusion test results with real-world experiments, the platform performs credibility self-evaluation to ensure both the fidelity and efficiency of autonomous driving testing. Please refer to the website for the full testing functionalities on the autonomous driving public service platform OnSite:https://www.onsite.com.cn.
Enhancing Generalization of Depth Estimation Foundation Model via Weakly-Supervised Adaptation with Regularization
Nov 18, 2025The emergence of foundation models has substantially advanced zero-shot generalization in monocular depth estimation (MDE), as exemplified by the Depth Anything series. However, given access to some data from downstream tasks, a natural question arises: can the performance of these models be further improved? To this end, we propose WeSTAR, a parameter-efficient framework that performs Weakly supervised Self-Training Adaptation with Regularization, designed to enhance the robustness of MDE foundation models in unseen and diverse domains. We first adopt a dense self-training objective as the primary source of structural self-supervision. To further improve robustness, we introduce semantically-aware hierarchical normalization, which exploits instance-level segmentation maps to perform more stable and multi-scale structural normalization. Beyond dense supervision, we introduce a cost-efficient weak supervision in the form of pairwise ordinal depth annotations to further guide the adaptation process, which enforces informative ordinal constraints to mitigate local topological errors. Finally, a weight regularization loss is employed to anchor the LoRA updates, ensuring training stability and preserving the model's generalizable knowledge. Extensive experiments on both realistic and corrupted out-of-distribution datasets under diverse and challenging scenarios demonstrate that WeSTAR consistently improves generalization and achieves state-of-the-art performance across a wide range of benchmarks.
UMIGen: A Unified Framework for Egocentric Point Cloud Generation and Cross-Embodiment Robotic Imitation Learning
Nov 12, 2025



Data-driven robotic learning faces an obvious dilemma: robust policies demand large-scale, high-quality demonstration data, yet collecting such data remains a major challenge owing to high operational costs, dependence on specialized hardware, and the limited spatial generalization capability of current methods. The Universal Manipulation Interface (UMI) relaxes the strict hardware requirements for data collection, but it is restricted to capturing only RGB images of a scene and omits the 3D geometric information on which many tasks rely. Inspired by DemoGen, we propose UMIGen, a unified framework that consists of two key components: (1) Cloud-UMI, a handheld data collection device that requires no visual SLAM and simultaneously records point cloud observation-action pairs; and (2) a visibility-aware optimization mechanism that extends the DemoGen pipeline to egocentric 3D observations by generating only points within the camera's field of view. These two components enable efficient data generation that aligns with real egocentric observations and can be directly transferred across different robot embodiments without any post-processing. Experiments in both simulated and real-world settings demonstrate that UMIGen supports strong cross-embodiment generalization and accelerates data collection in diverse manipulation tasks.