 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE-TTS: A New Embodied Test-Time Scaling Framework for Robotic Manipulation
Jun 25, 2026Recently, a few works have made early attempts to study test-time scaling for embodied tasks. However, two major challenges remain unsolved: (1) reasoning can effectively improve the performance of the policy, but its scaling mechanism has seldom been studied; (2) historical information is essential, as embodied tasks are inherently long-horizon and sequential, making sole reliance on current observations for action scaling inadequate due to the lack of historical context utilization. To address these challenges, we introduce E-TTS, a modular and plug-and-play Embodied Test-Time Scaling framework that unifies reasoning and action scaling for robotic manipulation via history-aware iterative refinement with vision-language verifiers. To support joint reasoning-action scaling, E-TTS performs reasoning-action joint sampling and scoring in a pairwise manner. To better utilize historical information, E-TTS uses a history buffer to store historical context, which is then used by reasoning and action verifiers to evaluate the sampled candidates. Unlike conventional open-loop TTS methods, E-TTS introduces feedback generation into the sampling process to form a closed-loop iterative refinement mechanism, enhancing both inference efficiency and environmental adaptability. Each component functions as an independent and composable module, allowing flexible and adaptive configuration depending on task requirements. To evaluate the advantages of our framework, we conduct experiments across 4 different benchmarks, 6 environments, 3 embodiments, and 4 base vision-language-action models. The experimental results demonstrate that, without requiring additional expert data collection or retraining, E-TTS consistently improves performance, achieving up to a 33.14% increase in simulation and 26.62% in real-world scenarios.
UniBYD: A Unified Framework for Learning Robotic Manipulation Across Embodiments Beyond Imitation of Human Demonstrations
Dec 12, 2025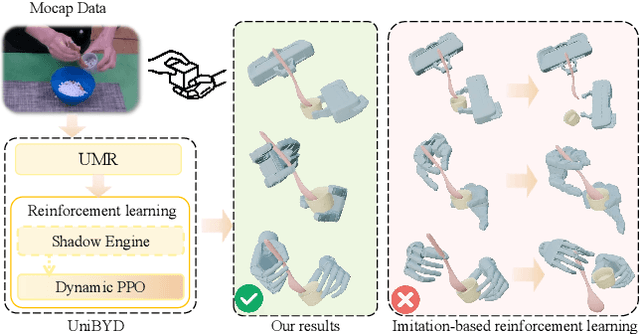
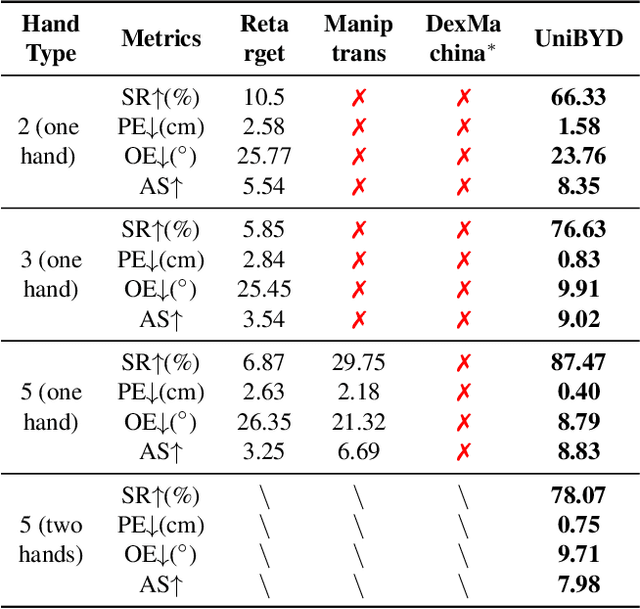
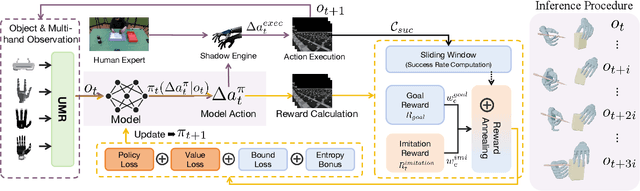
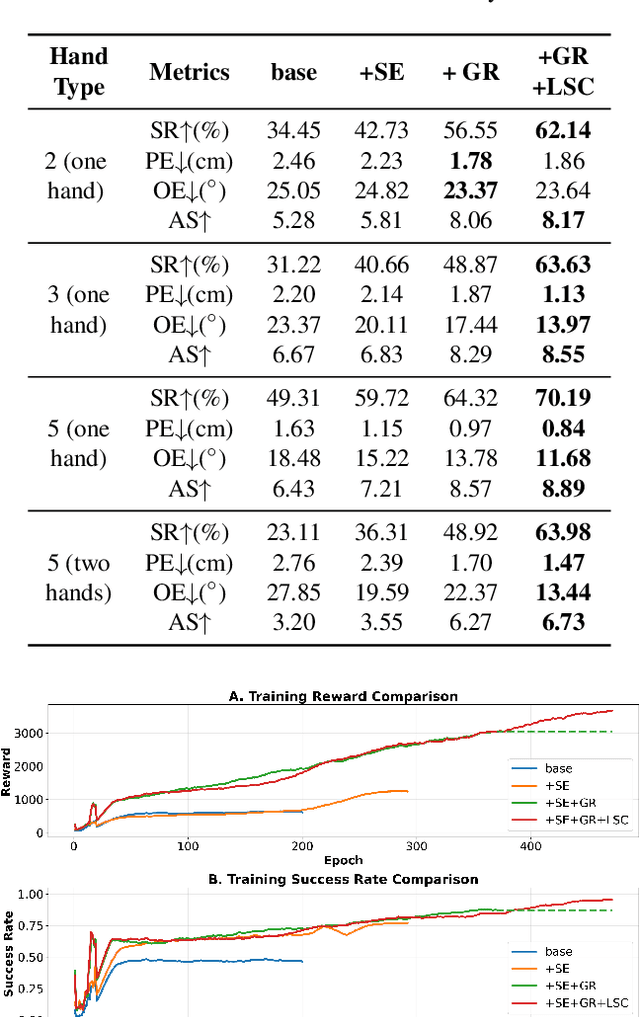
In embodied intelligence, the embodiment gap between robotic and human hands brings significant challenges for learning from human demonstrations. Although some studies have attempted to bridge this gap using reinforcement learning, they remain confined to merely reproducing human manipulation, resulting in limited task performance. In this paper, we propose UniBYD, a unified framework that uses a dynamic reinforcement learning algorithm to discover manipulation policies aligned with the robot's physical characteristics. To enable consistent modeling across diverse robotic hand morphologies, UniBYD incorporates a unified morphological representation (UMR). Building on UMR, we design a dynamic PPO with an annealed reward schedule, enabling reinforcement learning to transition from imitation of human demonstrations to explore policies adapted to diverse robotic morphologies better, thereby going beyond mere imitation of human hands. To address the frequent failures of learning human priors in the early training stage, we design a hybrid Markov-based shadow engine that enables reinforcement learning to imitate human manipulations in a fine-grained manner. To evaluate UniBYD comprehensively, we propose UniManip, the first benchmark encompassing robotic manipulation tasks spanning multiple hand morphologies. Experiments demonstrate a 67.90% improvement in success rate over the current state-of-the-art. Upon acceptance of the paper, we will release our code and benchmark at https://github.com/zhanheng-creator/UniBYD.
GenPilot: A Multi-Agent System for Test-Time Prompt Optimization in Image Generation
Oct 08, 2025Text-to-image synthesis has made remarkable progress, yet accurately interpreting complex and lengthy prompts remains challenging, often resulting in semantic inconsistencies and missing details. Existing solutions, such as fine-tuning, are model-specific and require training, while prior automatic prompt optimization (APO) approaches typically lack systematic error analysis and refinement strategies, resulting in limited reliability and effectiveness. Meanwhile, test-time scaling methods operate on fixed prompts and on noise or sample numbers, limiting their interpretability and adaptability. To solve these, we introduce a flexible and efficient test-time prompt optimization strategy that operates directly on the input text. We propose a plug-and-play multi-agent system called GenPilot, integrating error analysis, clustering-based adaptive exploration, fine-grained verification, and a memory module for iterative optimization. Our approach is model-agnostic, interpretable, and well-suited for handling long and complex prompts. Simultaneously, we summarize the common patterns of errors and the refinement strategy, offering more experience and encouraging further exploration. Experiments on DPG-bench and Geneval with improvements of up to 16.9% and 5.7% demonstrate the strong capability of our methods in enhancing the text and image consistency and structural coherence of generated images, revealing the effectiveness of our test-time prompt optimization strategy. The code is available at https://github.com/27yw/GenPilot.