 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaCauchy: An Extensible FEM Framework for Vision-Based Tactile Simulation
Jun 18, 2026Vision-based tactile sensors require high-fidelity simulation for reinforcement learning, yet existing approaches struggle to provide accurate mechanical stress fields within GPU-accelerated robotics platforms. We present TaCauchy, an extensible Finite Element Method (FEM) framework that integrates rigorous physics-based force computation into Isaac Sim. Built on the Unified Incremental Potential Contact (UIPC) solver, TaCauchy directly computes Cauchy stress tensors from hyperelastic constitutive laws and projects them onto contact surfaces to obtain traction forces and pressure distributions, providing mechanical ground truth from first principles rather than empirical estimation. Our framework features automatic mesh generation with geometry-aware adaptive refinement and a modular sensor interface enabling rapid integration of diverse sensors (GelSight Mini, DIGIT, 9DTact) with minimal configuration. Performance benchmarks demonstrate 33.40 FPS for single environments and 555 FPS aggregate throughput across 60 parallel environments, with stress extraction overhead under 1 ms. Physical validation experiments show strong agreement between simulated and real tactile responses across force ranges from 1.2556 N to 4.7332 N, achieving SSIM above 0.93, confirming the framework's capability to provide accurate, physically-grounded force supervision for downstream robotic manipulation tasks.
OA-WAM: Object-Addressable World Action Model for Robust Robot Manipulation
May 07, 2026World Action Models (WAMs) enhance Vision-Language-Action policies by jointly predicting scene evolution and robot actions, but existing methods usually represent the predicted world as holistic images, video tokens, or global latents. These representations are difficult for an action decoder to address when an instruction refers to a particular object, especially under scene shifts where object identity is entangled with context. We propose OA-WAM, an Object-Addressable World Action Model for robust robot manipulation. OA-WAM decomposes each frame into N+1 slot states, with one robot slot and N object slots. Each slot contains a persistent address vector and a time-varying content vector, and is fused with text, image, proprioception, and past-action tokens in a block-causal sequence. A world head predicts next-frame slot states, while a flow-matching action head decodes a 16-step continuous action chunk in the same forward pass. Addressability is enforced by routing cross-slot attention through address-only keys and resetting the address slice at every transformer layer, separating which object to act on from what that object currently is without adding extra tokens. OA-WAM matches strong VLA and WAM baselines on LIBERO (97.8%) and SimplerEnv (79.3%), reaches state-of-the-art performance on the most relevant LIBERO-Plus geometric axes, and remains competitive on the seven-axis aggregate. A causal slot-intervention test yields a swap-binding cosine of 0.87, versus at most 0.09 for holistic baselines. These results suggest that addressable object states provide an effective interface for robust world-action modeling under scene perturbations.
Master Micro Residual Correction with Adaptive Tactile Fusion and Force-Mixed Control for Contact-Rich Manipulation
Mar 16, 2026Robotic contact-rich and fine-grained manipulation remains a significant challenge due to complex interaction dynamics and the competing requirements of multi-timescale control. While current visual imitation learning methods excel at long-horizon planning, they often fail to perceive critical interaction cues like friction variations or incipient slip, and struggle to balance global task coherence with local reactive feedback. To address these challenges, we propose M2-ResiPolicy, a novel Master-Micro residual control architecture that synergizes high-level action guidance with low-level correction. The framework consists of a Master-Guidance Policy (MGP) operating at 10 Hz, which generates temporally consistent action chunks via a diffusion-based backbone and employs a tactile-intensity-driven adaptive fusion mechanism to dynamically modulate perceptual weights between vision and touch. Simultaneously, a high-frequency (60 Hz) Micro-Residual Corrector (MRC) utilizes a lightweight GRU to provide real-time action compensation based on TCP wrench feedback. This policy is further integrated with a force-mixed PBIC execution layer, effectively regulating contact forces to ensure interaction safety. Experiments across several demanding tasks including fragile object grasping and precision insertion, demonstrate that M2-ResiPolicy significantly outperforms standard Diffusion Policy (DP) and state-of-the-art Reactive Diffusion Policy (RDP), achieving a 93\% damage-free success rate in chip grasping and superior force regulation stability.
Learning to Manipulate Anything: Revealing Data Scaling Laws in Bounding-Box Guided Policies
Feb 12, 2026Diffusion-based policies show limited generalization in semantic manipulation, posing a key obstacle to the deployment of real-world robots. This limitation arises because relying solely on text instructions is inadequate to direct the policy's attention toward the target object in complex and dynamic environments. To solve this problem, we propose leveraging bounding-box instruction to directly specify target object, and further investigate whether data scaling laws exist in semantic manipulation tasks. Specifically, we design a handheld segmentation device with an automated annotation pipeline, Label-UMI, which enables the efficient collection of demonstration data with semantic labels. We further propose a semantic-motion-decoupled framework that integrates object detection and bounding-box guided diffusion policy to improve generalization and adaptability in semantic manipulation. Throughout extensive real-world experiments on large-scale datasets, we validate the effectiveness of the approach, and reveal a power-law relationship between generalization performance and the number of bounding-box objects. Finally, we summarize an effective data collection strategy for semantic manipulation, which can achieve 85\% success rates across four tasks on both seen and unseen objects. All datasets and code will be released to the community.
SandWorm: Event-based Visuotactile Perception with Active Vibration for Screw-Actuated Robot in Granular Media
Jan 20, 2026Perception in granular media remains challenging due to unpredictable particle dynamics. To address this challenge, we present SandWorm, a biomimetic screw-actuated robot augmented by peristaltic motion to enhance locomotion, and SWTac, a novel event-based visuotactile sensor with an actively vibrated elastomer. The event camera is mechanically decoupled from vibrations by a spring isolation mechanism, enabling high-quality tactile imaging of both dynamic and stationary objects. For algorithm design, we propose an IMU-guided temporal filter to enhance imaging consistency, improving MSNR by 24%. Moreover, we systematically optimize SWTac with vibration parameters, event camera settings and elastomer properties. Motivated by asymmetric edge features, we also implement contact surface estimation by U-Net. Experimental validation demonstrates SWTac's 0.2 mm texture resolution, 98% stone classification accuracy, and 0.15 N force estimation error, while SandWorm demonstrates versatile locomotion (up to 12.5 mm/s) in challenging terrains, successfully executes pipeline dredging and subsurface exploration in complex granular media (observed 90% success rate). Field experiments further confirm the system's practical performance.
CEI: A Unified Interface for Cross-Embodiment Visuomotor Policy Learning in 3D Space
Jan 14, 2026Robotic foundation models trained on large-scale manipulation datasets have shown promise in learning generalist policies, but they often overfit to specific viewpoints, robot arms, and especially parallel-jaw grippers due to dataset biases. To address this limitation, we propose Cross-Embodiment Interface (\CEI), a framework for cross-embodiment learning that enables the transfer of demonstrations across different robot arm and end-effector morphologies. \CEI introduces the concept of \textit{functional similarity}, which is quantified using Directional Chamfer Distance. Then it aligns robot trajectories through gradient-based optimization, followed by synthesizing observations and actions for unseen robot arms and end-effectors. In experiments, \CEI transfers data and policies from a Franka Panda robot to \textbf{16} different embodiments across \textbf{3} tasks in simulation, and supports bidirectional transfer between a UR5+AG95 gripper robot and a UR5+Xhand robot across \textbf{6} real-world tasks, achieving an average transfer ratio of 82.4\%. Finally, we demonstrate that \CEI can also be extended with spatial generalization and multimodal motion generation capabilities using our proposed techniques. Project website: https://cross-embodiment-interface.github.io/
FlexiCup: Wireless Multimodal Suction Cup with Dual-Zone Vision-Tactile Sensing
Nov 18, 2025



Conventional suction cups lack sensing capabilities for contact-aware manipulation in unstructured environments. This paper presents FlexiCup, a fully wireless multimodal suction cup that integrates dual-zone vision-tactile sensing. The central zone dynamically switches between vision and tactile modalities via illumination control for contact detection, while the peripheral zone provides continuous spatial awareness for approach planning. FlexiCup supports both vacuum and Bernoulli suction modes through modular mechanical configurations, achieving complete wireless autonomy with onboard computation and power. We validate hardware versatility through dual control paradigms. Modular perception-driven grasping across structured surfaces with varying obstacle densities demonstrates comparable performance between vacuum (90.0% mean success) and Bernoulli (86.7% mean success) modes. Diffusion-based end-to-end learning achieves 73.3% success on inclined transport and 66.7% on orange extraction tasks. Ablation studies confirm that multi-head attention coordinating dual-zone observations provides 13% improvements for contact-aware manipulation. Hardware designs and firmware are available at https://anonymous.4open.science/api/repo/FlexiCup-DA7D/file/index.html?v=8f531b44.
UMIGen: A Unified Framework for Egocentric Point Cloud Generation and Cross-Embodiment Robotic Imitation Learning
Nov 12, 2025



Data-driven robotic learning faces an obvious dilemma: robust policies demand large-scale, high-quality demonstration data, yet collecting such data remains a major challenge owing to high operational costs, dependence on specialized hardware, and the limited spatial generalization capability of current methods. The Universal Manipulation Interface (UMI) relaxes the strict hardware requirements for data collection, but it is restricted to capturing only RGB images of a scene and omits the 3D geometric information on which many tasks rely. Inspired by DemoGen, we propose UMIGen, a unified framework that consists of two key components: (1) Cloud-UMI, a handheld data collection device that requires no visual SLAM and simultaneously records point cloud observation-action pairs; and (2) a visibility-aware optimization mechanism that extends the DemoGen pipeline to egocentric 3D observations by generating only points within the camera's field of view. These two components enable efficient data generation that aligns with real egocentric observations and can be directly transferred across different robot embodiments without any post-processing. Experiments in both simulated and real-world settings demonstrate that UMIGen supports strong cross-embodiment generalization and accelerates data collection in diverse manipulation tasks.
MoiréTac: A Dual-Mode Visuotactile Sensor for Multidimensional Perception Using Moiré Pattern Amplification
Sep 16, 2025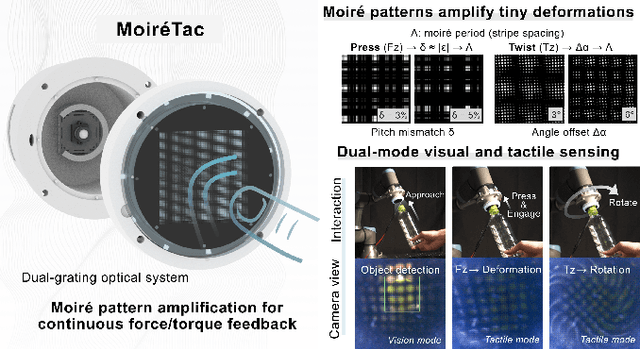

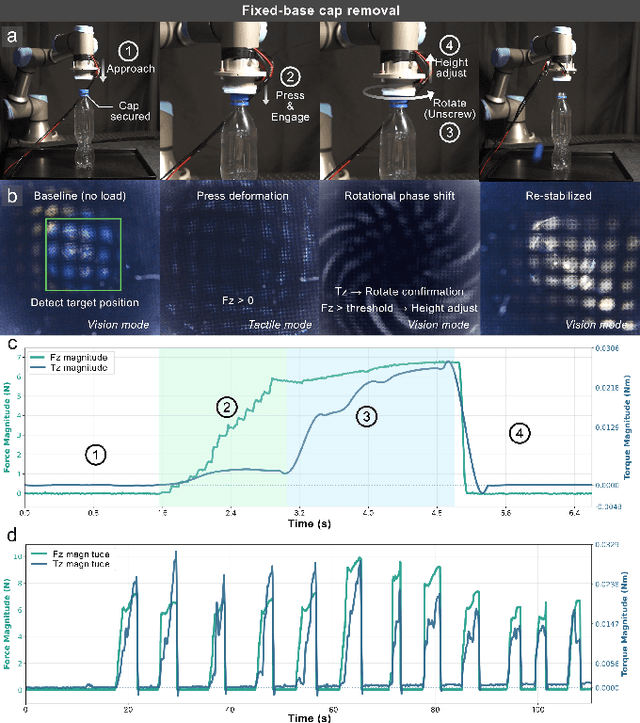

Visuotactile sensors typically employ sparse marker arrays that limit spatial resolution and lack clear analytical force-to-image relationships. To solve this problem, we present \textbf{Moir\'eTac}, a dual-mode sensor that generates dense interference patterns via overlapping micro-gratings within a transparent architecture. When two gratings overlap with misalignment, they create moir\'e patterns that amplify microscopic deformations. The design preserves optical clarity for vision tasks while producing continuous moir\'e fields for tactile sensing, enabling simultaneous 6-axis force/torque measurement, contact localization, and visual perception. We combine physics-based features (brightness, phase gradient, orientation, and period) from moir\'e patterns with deep spatial features. These are mapped to 6-axis force/torque measurements, enabling interpretable regression through end-to-end learning. Experimental results demonstrate three capabilities: force/torque measurement with R^2 > 0.98 across tested axes; sensitivity tuning through geometric parameters (threefold gain adjustment); and vision functionality for object classification despite moir\'e overlay. Finally, we integrate the sensor into a robotic arm for cap removal with coordinated force and torque control, validating its potential for dexterous manipulation.
UltraTac: Integrated Ultrasound-Augmented Visuotactile Sensor for Enhanced Robotic Perception
Aug 29, 2025

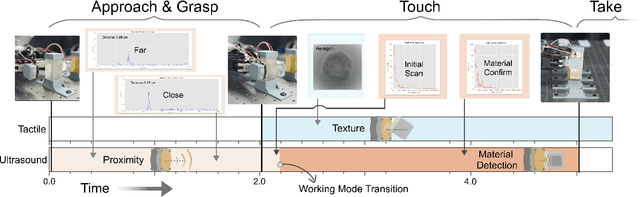
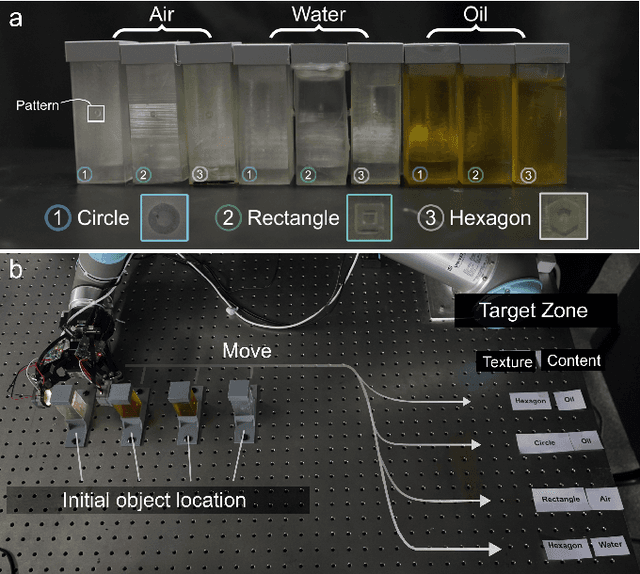
Visuotactile sensors provide high-resolution tactile information but are incapable of perceiving the material features of objects. We present UltraTac, an integrated sensor that combines visuotactile imaging with ultrasound sensing through a coaxial optoacoustic architecture. The design shares structural components and achieves consistent sensing regions for both modalities. Additionally, we incorporate acoustic matching into the traditional visuotactile sensor structure, enabling integration of the ultrasound sensing modality without compromising visuotactile performance. Through tactile feedback, we dynamically adjust the operating state of the ultrasound module to achieve flexible functional coordination. Systematic experiments demonstrate three key capabilities: proximity sensing in the 3-8 cm range ($R^2=0.90$), material classification (average accuracy: 99.20%), and texture-material dual-mode object recognition achieving 92.11% accuracy on a 15-class task. Finally, we integrate the sensor into a robotic manipulation system to concurrently detect container surface patterns and internal content, which verifies its potential for advanced human-machine interaction and precise robotic manipulation.