 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvent-VLA: Action-Conditioned Event Fusion for Robust Vision-Language-Action Model
Jun 28, 2026Vision-Language-Action (VLA) models have become an important paradigm of embodied AI. However, existing VLA models typically assume well-lit and stable indoor settings, while real-world embodied manipulation may involve degraded RGB observations caused by illumination shifts, posing critical challenges for robust robotic manipulation. To address this gap, we propose \textbf{Event-VLA}, an event-enhanced VLA framework for generalizable manipulation across varying illumination conditions. We formulate VLA-based manipulation under degraded visibility as a practical robustness problem for RGB-centric policies, and introduce event streams as an illumination-robust, motion-sensitive complementary observation to improve robustness across visibility levels. Specifically, unlike conventional multimodal fusion that directly merges event features into the global semantic token space, Event-VLA injects event information through an action-query routing pathway. It uses learnable action queries to extract task-relevant semantics from the VLA reasoning process, and selectively aggregates event tokens via gated cross-attention to construct event-aware action representations. This design preserves the pretrained RGB-language semantic priors while effectively leveraging event information for robust action prediction. Experiments in simulation and real-world deployment show that Event-VLA maintains strong manipulation performance under normal lighting and improves success rates under low-light degradation and near-dark real-world settings.
OPD-Evolver: Cultivating Holistic Agent Evolver via On-Policy Distillation
Jun 16, 2026Memory has become a standard substrate for self-evolving agents, yet retaining experience is not the same as learning how to evolve through it. Existing memory agents can store trajectories, retrieve reflections, or accumulate skills, but often lack the holistic competence to select useful experience, act on it, write reusable knowledge, and maintain a growing repository. We introduce OPD-Evolver, a slow-fast co-evolution framework that cultivates such an agent evolver through on-policy self-distillation. In the fast loop, OPD-Evolver interacts with a four-level memory hierarchy to read, use, write, and maintain experience for rapid test-time evolution. In the slow loop, outcome-calibrated memory attribution and privileged hindsight distill these four abilities into the deployable policy. Across multi-domain benchmarks, OPD-Evolver surpasses memory systems such as ReasoningBank by up to 11.5%, and training-based methods such as Skill0 by ~5.8%. Further analysis shows that OPD-Evolver internalizes high-value experience and memory management, enabling OPD-Evolver-9B to challenge giant counterparts such as Qwen3.5-397B-A17B and Step-3.5-Flash, pointing beyond memory-augmented agents toward genuinely qualified agent evolvers.
PRISM: : Planning and Reasoning with Intent in Simulated Embodied Environments
May 12, 2026When an LLM-based embodied agent fails at a household task, the culprit could be misidentified objects, forgotten sub-goals, or poor action sequencing -- yet existing benchmarks report only a single success rate, making it impossible to tell which cognitive module is responsible. We present PRISM, a diagnostic benchmark that reframes this problem: rather than asking only \textit{did the agent succeed?}, PRISM asks \textit{which capability is most likely responsible for failure?} Built on five photorealistic multi-room apartments (4--8 rooms each), PRISM structures 300 human-verified tasks into three capability tiers -- \textit{Basic Ability}, \textit{Reasoning Ability}, and \textit{Long-horizon Ability} -- that isolate perception-to-action grounding, implicit intent resolution, and sustained multi-step coordination respectively. PRISM exposes an agent-agnostic executable action API that allows arbitrary agents: LLM agents, VLM agents, symbolic planners, RL policies, and hybrid systems, to be evaluated end-to-end under the same benchmark protocol. To support deeper diagnosis, optional probes for perception, memory, and planning can be adopted, replaced, or bypassed entirely, enabling controlled component-level analysis when desired. Experiments on seven contemporary LLMs establish a clear hierarchy: explicit spatial grounding is not the dominant failure source under oracle perception, implicit intent resolution is a significant bottleneck for all model families, and long-horizon coordination exposes a stark capability cliff -- lightweight models collapse to as low as 20.0\% success while simultaneously consuming more tokens than their frontier counterparts, a signature of compensatory over-reasoning rather than genuine planning capability. Project page: \href{https://sj-li.com/PROJ/PRISM}{link}.
Aligning LLMs with Graph Neural Solvers for Combinatorial Optimization
Mar 28, 2026Recent research has demonstrated the effectiveness of large language models (LLMs) in solving combinatorial optimization problems (COPs) by representing tasks and instances in natural language. However, purely language-based approaches struggle to accurately capture complex relational structures inherent in many COPs, rendering them less effective at addressing medium-sized or larger instances. To address these limitations, we propose AlignOPT, a novel approach that aligns LLMs with graph neural solvers to learn a more generalizable neural COP heuristic. Specifically, AlignOPT leverages the semantic understanding capabilities of LLMs to encode textual descriptions of COPs and their instances, while concurrently exploiting graph neural solvers to explicitly model the underlying graph structures of COP instances. Our approach facilitates a robust integration and alignment between linguistic semantics and structural representations, enabling more accurate and scalable COP solutions. Experimental results demonstrate that AlignOPT achieves state-of-the-art results across diverse COPs, underscoring its effectiveness in aligning semantic and structural representations. In particular, AlignOPT demonstrates strong generalization, effectively extending to previously unseen COP instances.
AnalogAgent: Self-Improving Analog Circuit Design Automation with LLM Agents
Mar 25, 2026Recent advances in large language models (LLMs) suggest strong potential for automating analog circuit design. Yet most LLM-based approaches rely on a single-model loop of generation, diagnosis, and correction, which favors succinct summaries over domain-specific insight and suffers from context attrition that erases critical technical details. To address these limitations, we propose AnalogAgent, a training-free agentic framework that integrates an LLM-based multi-agent system (MAS) with self-evolving memory (SEM) for analog circuit design automation. AnalogAgent coordinates a Code Generator, Design Optimizer, and Knowledge Curator to distill execution feedback into an adaptive playbook in SEM and retrieve targeted guidance for subsequent generation, enabling cross-task transfer without additional expert feedback, databases, or libraries. Across established benchmarks, AnalogAgent achieves 92% Pass@1 with Gemini and 97.4% Pass@1 with GPT-5. Moreover, with compact models (e.g., Qwen-8B), it yields a +48.8% average Pass@1 gain across tasks and reaches 72.1% Pass@1 overall, indicating that AnalogAgent substantially strengthens open-weight models for high-quality analog circuit design automation.
The Reward Model Selection Crisis in Personalized Alignment
Dec 28, 2025Personalized alignment from preference data has focused primarily on improving reward model (RM) accuracy, with the implicit assumption that better preference ranking translates to better personalized behavior. However, in deployment, computational constraints necessitate inference-time adaptation via reward-guided decoding (RGD) rather than per-user policy fine-tuning. This creates a critical but overlooked requirement: reward models must not only rank preferences accurately but also effectively guide token-level generation decisions. We demonstrate that standard RM accuracy fails catastrophically as a selection criterion for deployment-ready personalized alignment. Through systematic evaluation across three datasets, we introduce policy accuracy, a metric quantifying whether RGD scoring functions correctly discriminate between preferred and dispreferred responses. We show that RM accuracy correlates only weakly with this policy-level discrimination ability (Kendall's tau = 0.08--0.31). More critically, we introduce Pref-LaMP, the first personalized alignment benchmark with ground-truth user completions, enabling direct behavioral evaluation without circular reward-based metrics. On Pref-LaMP, we expose a complete decoupling between discrimination and generation: methods with 20-point RM accuracy differences produce almost identical output quality, and even methods achieving high discrimination fail to generate behaviorally aligned responses. Finally, simple in-context learning (ICL) dominates all reward-guided methods for models > 3B parameters, achieving 3-5 point ROUGE-1 gains over the best reward method at 7B scale. These findings show that the field optimizes proxy metrics that fail to predict deployment performance and do not translate preferences into real behavioral adaptation under deployment constraints.
Enhancing Generalization of Depth Estimation Foundation Model via Weakly-Supervised Adaptation with Regularization
Nov 18, 2025The emergence of foundation models has substantially advanced zero-shot generalization in monocular depth estimation (MDE), as exemplified by the Depth Anything series. However, given access to some data from downstream tasks, a natural question arises: can the performance of these models be further improved? To this end, we propose WeSTAR, a parameter-efficient framework that performs Weakly supervised Self-Training Adaptation with Regularization, designed to enhance the robustness of MDE foundation models in unseen and diverse domains. We first adopt a dense self-training objective as the primary source of structural self-supervision. To further improve robustness, we introduce semantically-aware hierarchical normalization, which exploits instance-level segmentation maps to perform more stable and multi-scale structural normalization. Beyond dense supervision, we introduce a cost-efficient weak supervision in the form of pairwise ordinal depth annotations to further guide the adaptation process, which enforces informative ordinal constraints to mitigate local topological errors. Finally, a weight regularization loss is employed to anchor the LoRA updates, ensuring training stability and preserving the model's generalizable knowledge. Extensive experiments on both realistic and corrupted out-of-distribution datasets under diverse and challenging scenarios demonstrate that WeSTAR consistently improves generalization and achieves state-of-the-art performance across a wide range of benchmarks.
Patch-as-Decodable-Token: Towards Unified Multi-Modal Vision Tasks in MLLMs
Oct 02, 2025
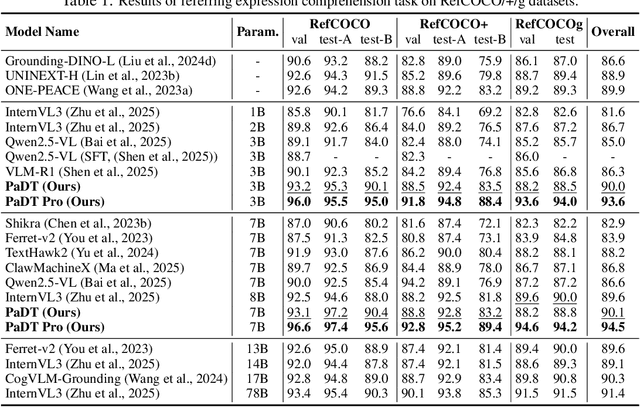

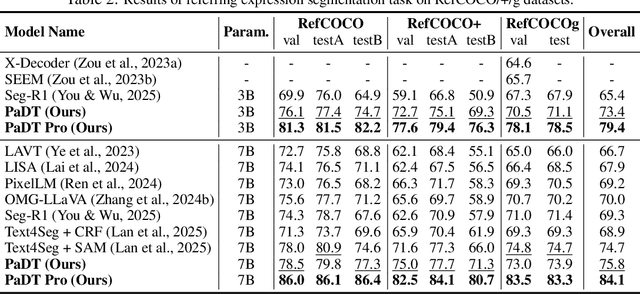
Multimodal large language models (MLLMs) have advanced rapidly in recent years. However, existing approaches for vision tasks often rely on indirect representations, such as generating coordinates as text for detection, which limits performance and prevents dense prediction tasks like segmentation. To overcome these challenges, we introduce Patch-as-Decodable Token (PaDT), a unified paradigm that enables MLLMs to directly generate both textual and diverse visual outputs. Central to PaDT are Visual Reference Tokens (VRTs), derived from visual patch embeddings of query images and interleaved seamlessly with LLM's output textual tokens. A lightweight decoder then transforms LLM's outputs into detection, segmentation, and grounding predictions. Unlike prior methods, PaDT processes VRTs independently at each forward pass and dynamically expands the embedding table, thus improving localization and differentiation among similar objects. We further tailor a training strategy for PaDT by randomly selecting VRTs for supervised fine-tuning and introducing a robust per-token cross-entropy loss. Our empirical studies across four visual perception and understanding tasks suggest PaDT consistently achieving state-of-the-art performance, even compared with significantly larger MLLM models. The code is available at https://github.com/Gorilla-Lab-SCUT/PaDT.
Box-Level Class-Balanced Sampling for Active Object Detection
Aug 25, 2025



Training deep object detectors demands expensive bounding box annotation. Active learning (AL) is a promising technique to alleviate the annotation burden. Performing AL at box-level for object detection, i.e., selecting the most informative boxes to label and supplementing the sparsely-labelled image with pseudo labels, has been shown to be more cost-effective than selecting and labelling the entire image. In box-level AL for object detection, we observe that models at early stage can only perform well on majority classes, making the pseudo labels severely class-imbalanced. We propose a class-balanced sampling strategy to select more objects from minority classes for labelling, so as to make the final training data, \ie, ground truth labels obtained by AL and pseudo labels, more class-balanced to train a better model. We also propose a task-aware soft pseudo labelling strategy to increase the accuracy of pseudo labels. We evaluate our method on public benchmarking datasets and show that our method achieves state-of-the-art performance.
AD-FM: Multimodal LLMs for Anomaly Detection via Multi-Stage Reasoning and Fine-Grained Reward Optimization
Aug 06, 2025



While Multimodal Large Language Models (MLLMs) demonstrate remarkable capabilities across diverse domains, their application to specialized anomaly detection (AD) remains constrained by domain adaptation challenges. Existing Group Relative Policy Optimization (GRPO) based approaches suffer from two critical limitations: inadequate training data utilization when models produce uniform responses, and insufficient supervision over reasoning processes that encourage immediate binary decisions without deliberative analysis. We propose a comprehensive framework addressing these limitations through two synergistic innovations. First, we introduce a multi-stage deliberative reasoning process that guides models from region identification to focused examination, generating diverse response patterns essential for GRPO optimization while enabling structured supervision over analytical workflows. Second, we develop a fine-grained reward mechanism incorporating classification accuracy and localization supervision, transforming binary feedback into continuous signals that distinguish genuine analytical insight from spurious correctness. Comprehensive evaluation across multiple industrial datasets demonstrates substantial performance improvements in adapting general vision-language models to specialized anomaly detection. Our method achieves superior accuracy with efficient adaptation of existing annotations, effectively bridging the gap between general-purpose MLLM capabilities and the fine-grained visual discrimination required for detecting subtle manufacturing defects and structural irregularities.