 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDP-CSGP: Differentially Private Stochastic Gradient Push with Compressed Communication
Dec 15, 2025In this paper, we propose a Differentially Private Stochastic Gradient Push with Compressed communication (termed DP-CSGP) for decentralized learning over directed graphs. Different from existing works, the proposed algorithm is designed to maintain high model utility while ensuring both rigorous differential privacy (DP) guarantees and efficient communication. For general non-convex and smooth objective functions, we show that the proposed algorithm achieves a tight utility bound of $\mathcal{O}\left( \sqrt{d\log \left( \frac{1}δ \right)}/(\sqrt{n}Jε) \right)$ ($J$ and $d$ are the number of local samples and the dimension of decision variables, respectively) with $\left(ε, δ\right)$-DP guarantee for each node, matching that of decentralized counterparts with exact communication. Extensive experiments on benchmark tasks show that, under the same privacy budget, DP-CSGP achieves comparable model accuracy with significantly lower communication cost than existing decentralized counterparts with exact communication.
Dyn-D$^2$P: Dynamic Differentially Private Decentralized Learning with Provable Utility Guarantee
May 10, 2025Most existing decentralized learning methods with differential privacy (DP) guarantee rely on constant gradient clipping bounds and fixed-level DP Gaussian noises for each node throughout the training process, leading to a significant accuracy degradation compared to non-private counterparts. In this paper, we propose a new Dynamic Differentially Private Decentralized learning approach (termed Dyn-D$^2$P) tailored for general time-varying directed networks. Leveraging the Gaussian DP (GDP) framework for privacy accounting, Dyn-D$^2$P dynamically adjusts gradient clipping bounds and noise levels based on gradient convergence. This proposed dynamic noise strategy enables us to enhance model accuracy while preserving the total privacy budget. Extensive experiments on benchmark datasets demonstrate the superiority of Dyn-D$^2$P over its counterparts employing fixed-level noises, especially under strong privacy guarantees. Furthermore, we provide a provable utility bound for Dyn-D$^2$P that establishes an explicit dependency on network-related parameters, with a scaling factor of $1/\sqrt{n}$ in terms of the number of nodes $n$ up to a bias error term induced by gradient clipping. To our knowledge, this is the first model utility analysis for differentially private decentralized non-convex optimization with dynamic gradient clipping bounds and noise levels.
PrivSGP-VR: Differentially Private Variance-Reduced Stochastic Gradient Push with Tight Utility Bounds
May 04, 2024



In this paper, we propose a differentially private decentralized learning method (termed PrivSGP-VR) which employs stochastic gradient push with variance reduction and guarantees $(\epsilon, \delta)$-differential privacy (DP) for each node. Our theoretical analysis shows that, under DP Gaussian noise with constant variance, PrivSGP-VR achieves a sub-linear convergence rate of $\mathcal{O}(1/\sqrt{nK})$, where $n$ and $K$ are the number of nodes and iterations, respectively, which is independent of stochastic gradient variance, and achieves a linear speedup with respect to $n$. Leveraging the moments accountant method, we further derive an optimal $K$ to maximize the model utility under certain privacy budget in decentralized settings. With this optimized $K$, PrivSGP-VR achieves a tight utility bound of $\mathcal{O}\left( \sqrt{d\log \left( \frac{1}{\delta} \right)}/(\sqrt{n}J\epsilon) \right)$, where $J$ and $d$ are the number of local samples and the dimension of decision variable, respectively, which matches that of the server-client distributed counterparts, and exhibits an extra factor of $1/\sqrt{n}$ improvement compared to that of the existing decentralized counterparts, such as A(DP)$^2$SGD. Extensive experiments corroborate our theoretical findings, especially in terms of the maximized utility with optimized $K$, in fully decentralized settings.
Robust Fully-Asynchronous Methods for Distributed Training over General Architecture
Jul 21, 2023



Perfect synchronization in distributed machine learning problems is inefficient and even impossible due to the existence of latency, package losses and stragglers. We propose a Robust Fully-Asynchronous Stochastic Gradient Tracking method (R-FAST), where each device performs local computation and communication at its own pace without any form of synchronization. Different from existing asynchronous distributed algorithms, R-FAST can eliminate the impact of data heterogeneity across devices and allow for packet losses by employing a robust gradient tracking strategy that relies on properly designed auxiliary variables for tracking and buffering the overall gradient vector. More importantly, the proposed method utilizes two spanning-tree graphs for communication so long as both share at least one common root, enabling flexible designs in communication architectures. We show that R-FAST converges in expectation to a neighborhood of the optimum with a geometric rate for smooth and strongly convex objectives; and to a stationary point with a sublinear rate for general non-convex settings. Extensive experiments demonstrate that R-FAST runs 1.5-2 times faster than synchronous benchmark algorithms, such as Ring-AllReduce and D-PSGD, while still achieving comparable accuracy, and outperforms existing asynchronous SOTA algorithms, such as AD-PSGD and OSGP, especially in the presence of stragglers.
Tackling Data Heterogeneity: A New Unified Framework for Decentralized SGD with Sample-induced Topology
Jul 08, 2022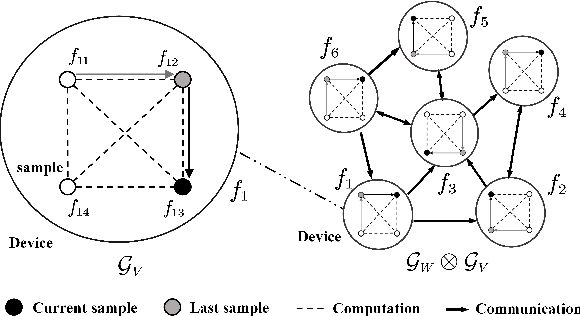
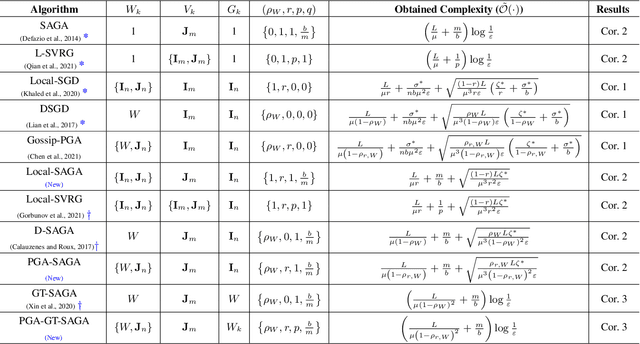
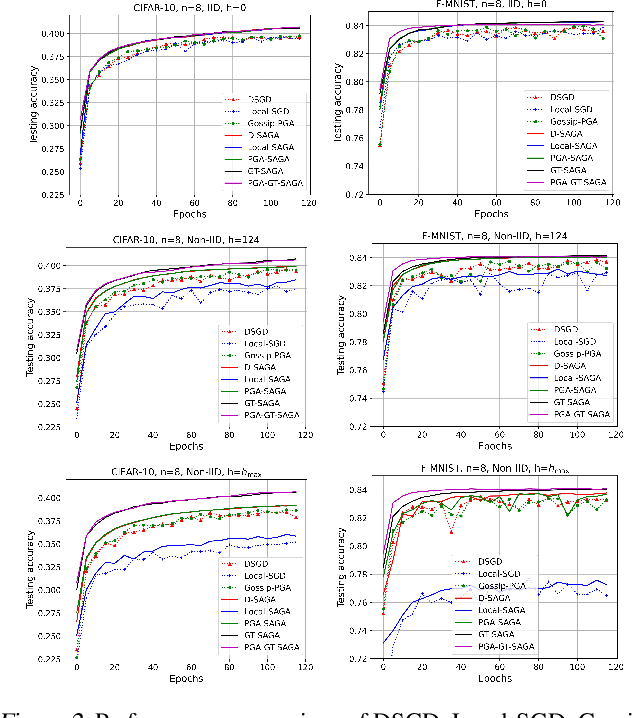
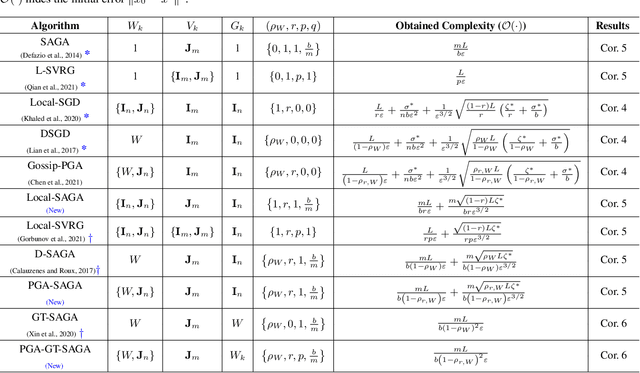
We develop a general framework unifying several gradient-based stochastic optimization methods for empirical risk minimization problems both in centralized and distributed scenarios. The framework hinges on the introduction of an augmented graph consisting of nodes modeling the samples and edges modeling both the inter-device communication and intra-device stochastic gradient computation. By designing properly the topology of the augmented graph, we are able to recover as special cases the renowned Local-SGD and DSGD algorithms, and provide a unified perspective for variance-reduction (VR) and gradient-tracking (GT) methods such as SAGA, Local-SVRG and GT-SAGA. We also provide a unified convergence analysis for smooth and (strongly) convex objectives relying on a proper structured Lyapunov function, and the obtained rate can recover the best known results for many existing algorithms. The rate results further reveal that VR and GT methods can effectively eliminate data heterogeneity within and across devices, respectively, enabling the exact convergence of the algorithm to the optimal solution. Numerical experiments confirm the findings in this paper.